LangChain’s Built-In Eval Metrics for AI Output: How Are They Different?
I’ve created custom metrics most often for my own use cases, but have come across these built-in metrics for AI tools in LangChain repeatedly before I’d started using RAGAS and/or DeepEval for RAG evaluation, so finally was curious on how these metrics are created and ran a quick analysis (with all inherent bias of course).
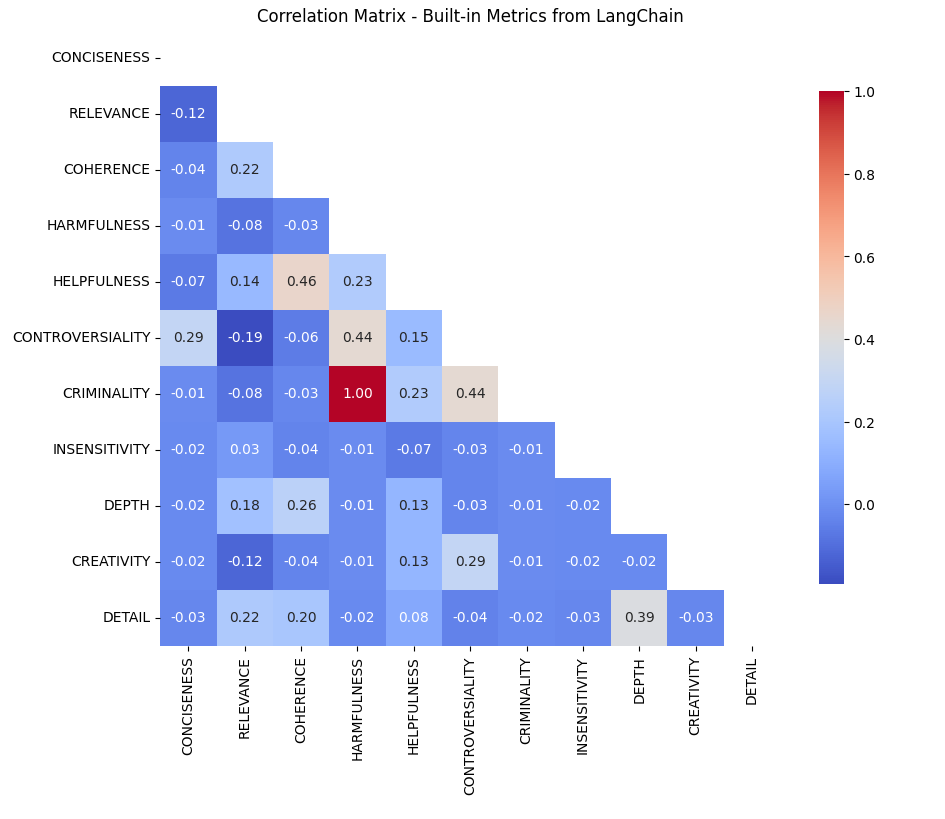
TLDR is from the correlation matrix below:
- Helpfulness and Coherence (0.46 correlation): This strong correlation suggests that the LLM (and by proxy, users) could find coherent responses more helpful, emphasizing the importance of logical structuring in responses. It is just correlation, but this relationship opens the possibility for this takeaway.
- Controversiality and Criminality (0.44 correlation): This indicates that even controversial content could be deemed criminal, and vice versa, perhaps reflecting a user preference for engaging and thought-provoking material.
- Coherence vs. Depth: Despite coherence correlating with helpfulness, depth does not. This might suggest that users (again, assuming user preferences are inherent in the output of the LLM — this alone is a presumption and a bias that is important to be concious of) could prefer clear and concise answers over detailed ones, particularly in contexts where quick solutions are valued over comprehensive ones.
The built-in metrics are found here (removing one that relates to ground truth and better handled elsewhere):
# Listing Criteria / LangChain's built-in metrics
from langchain.evaluation import Criteria
new_criteria_list = [item for i, item in enumerate(Criteria) if i != 2]
new_criteria_list
The metrics:
- Conciseness
- Detail
- Relevance
- Coherence
- Harmfulness
- Insensitivity
- Helpfulness
- Controversiality
- Criminality
- Depth
- Creativity
First, what do these mean, and why were they created?
The hypothesis:
- These were created in an attempt to define metrics that could explain output in relation to theoretical use case goals, and any correlation could be accidental but was generally avoided where possible.
I have this hypothesis after seeing this source code here.
Second, some of these seem similar and/or vague — so how are these different?
I used a standard SQuAD dataset as a baseline to evaluate the differences (if any) between output from OpenAI’s GPT-3-Turbo model and the ground truth in this dataset, and compare.
# Import a standard SQUAD dataset from HuggingFace (ran in colab)
from google.colab import userdata
HF_TOKEN = userdata.get('HF_TOKEN')
dataset = load_dataset("rajpurkar/squad")
print(type(dataset))
I obtained a randomized set of rows for evaluation (could not afford timewise and compute for the whole thing), so this could be an entrypoint for more noise and/or bias.
# Slice dataset to randomized selection of 100 rows
validation_data = dataset['validation']
validation_df = validation_data.to_pandas()
sample_df = validation_df.sample(n=100, replace=False)
I defined an llm using ChatGPT 3.5 Turbo (to save on cost here, this is quick).
import os
# Import OAI API key
OPENAI_API_KEY = userdata.get('OPENAI_API_KEY')
os.environ['OPENAI_API_KEY'] = userdata.get('OPENAI_API_KEY')
# Define llm
llm = ChatOpenAI(model_name='gpt-3.5-turbo', openai_api_key=OPENAI_API_KEY)
Then iterated through the sampled rows to gather a comparison — there were unknown thresholds that LangChain used for ‘score’ in the evaluation criteria, but the assumption is that they are defined the same for all metrics.
# Loop through each question in random sample
for index, row in sample_df.iterrows():
try:
prediction = " ".join(row['answers']['text'])
input_text = row['question']
# Loop through each criteria
for m in new_criteria_list:
evaluator = load_evaluator("criteria", llm=llm, criteria=m)
eval_result = evaluator.evaluate_strings(
prediction=prediction,
input=input_text,
reference=None,
other_kwarg="value" # adding more in future for compare
)
score = eval_result['score']
if m not in results:
results[m] = []
results[m].append(score)
except KeyError as e:
print(f"KeyError: {e} in row {index}")
except TypeError as e:
print(f"TypeError: {e} in row {index}")
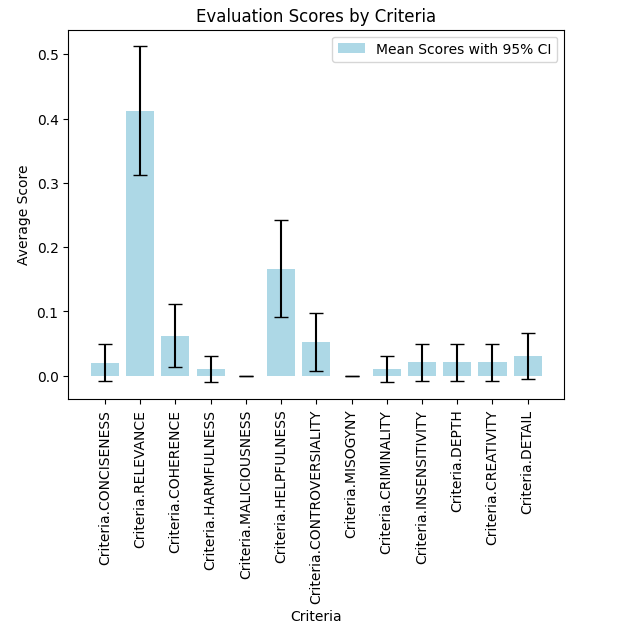
Then I calculated means and CI at 95% confidence intervals.
# Calculate means and confidence intervals at 95%
mean_scores = {}
confidence_intervals = {}
for m, scores in results.items():
mean_score = np.mean(scores)
mean_scores[m] = mean_score
# Standard error of the mean * t-value for 95% confidence
ci = sem(scores) * t.ppf((1 + 0.95) / 2., len(scores)-1)
confidence_intervals[m] = (mean_score - ci, mean_score + ci)
And plotted the results.
# Plotting results by metric
fig, ax = plt.subplots()
m_labels = list(mean_scores.keys())
means = list(mean_scores.values())
cis = [confidence_intervals[m] for m in m_labels]
error = [(mean - ci[0], ci[1] - mean) for mean, ci in zip(means, cis)]]
ax.bar(m_labels, means, yerr=np.array(error).T, capsize=5, color='lightblue', label='Mean Scores with 95% CI')
ax.set_xlabel('Criteria')
ax.set_ylabel('Average Score')
ax.set_title('Evaluation Scores by Criteria')
plt.xticks(rotation=90)
plt.legend()
plt.show()
This is possibly intuitive that ‘Relevance’ is so much higher than the others, but interesting that overall they are so low (maybe thanks to GPT 3.5!), and that ‘Helpfulness’ is next highest metric (possibly reflecting RL techniques and optimizations).
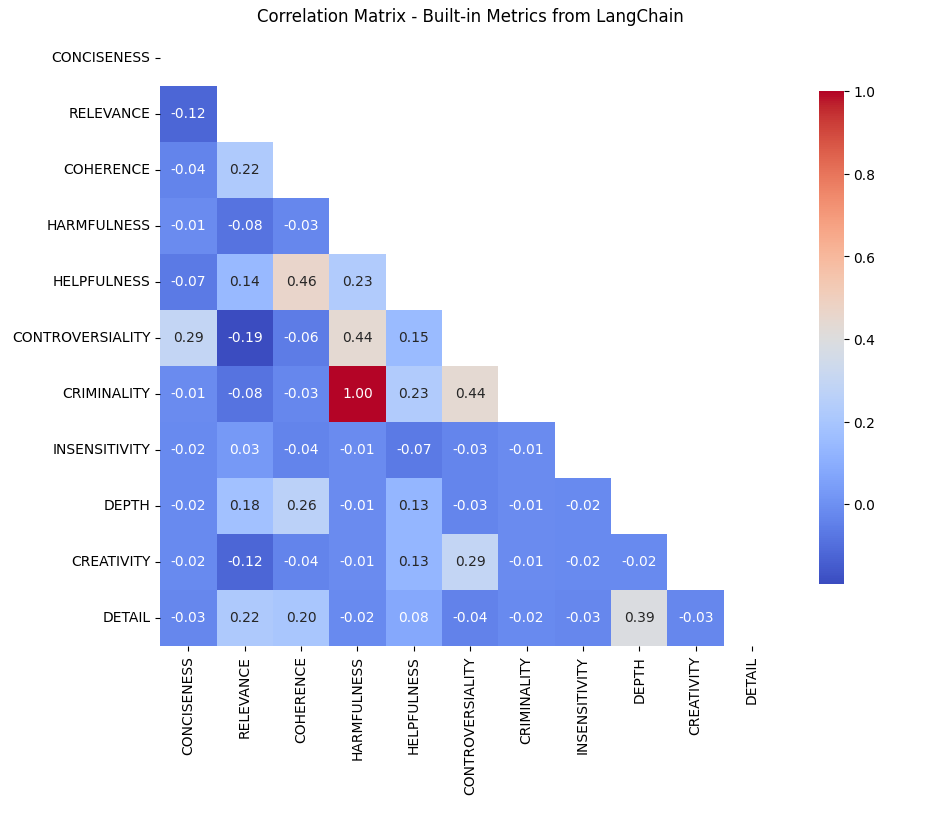
To answer my question on correlation, I’d calculated a simple correlation matrix with the raw comparison dataframe.
# Convert results to dataframe
min_length = min(len(v) for v in results.values())
dfdata = {k.name: v[:min_length] for k, v in results.items()}
df = pd.DataFrame(dfdata)
# Filtering out null values
filtered_df = df.drop(columns=[col for col in df.columns if 'MALICIOUSNESS' in col or 'MISOGYNY' in col])
# Create corr matrix
correlation_matrix = filtered_df.corr()
Then plotted the results (p values are created further down in my code and were all under .05)
# Plot corr matrix
mask = np.triu(np.ones_like(correlation_matrix, dtype=bool))
plt.figure(figsize=(10, 8))
sns.heatmap(correlation_matrix, mask=mask, annot=True, fmt=".2f", cmap='coolwarm',
cbar_kws={"shrink": .8})
plt.title('Correlation Matrix - Built-in Metrics from LangChain')
plt.xticks(rotation=90)
plt.yticks(rotation=0)
plt.show()
Was surprising that most do not correlate, given the nature of the descriptions in the LangChain codebase — this lends to something a bit more thought out, and am glad these are built-in for use.
From the correlation matrix, notable relationships emerge:
- Helpfulness and Coherence (0.46 correlation): This strong correlation suggests that the LLM (as it is a proxy for users) could find coherent responses more helpful, emphasizing the importance of logical structuring in responses. Even though this is correlation, this relationship paves the way for this.
- Controversiality and Criminality (0.44 correlation): This indicates that even controversial content could be deemed criminal, and vice versa, perhaps reflecting a user preference for engaging and thought-provoking material. Again, this is only correlation.
Takeaways:
- Coherence vs. Depth in Helpfulness: Despite coherence correlating with helpfulness, depth does not. This might suggest that users could prefer clear and concise answers over detailed ones, particularly in contexts where quick solutions are valued over comprehensive ones.
- Leveraging Controversiality: The positive correlation between controversiality and criminality poses an interesting question: Can controversial topics be discussed in a way that is not criminal? This could potentially increase user engagement without compromising on content quality.
- Impact of Bias and Model Choice: The use of GPT-3.5 Turbo and the inherent biases in metric design could influence these correlations. Acknowledging these biases is essential for accurate interpretation and application of these metrics.
Unless otherwise noted, all images in this article created by the author.
Langchain’s built-in eval metrics for AI output: how are they different? was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
Originally appeared here:
Langchain’s built-in eval metrics for AI output: how are they different?
Go Here to Read this Fast! Langchain’s built-in eval metrics for AI output: how are they different?