
Recommendation Systems
Current ML models can recommend similar products, but how about complementary?
In the domain of AI Recommendation Systems, Machine Learning models have been heavily used to recommend similar samples, whether products, content or even suggesting similar contacts. Most of these pre-trained models are open-source and can be used without training a model from scratch. However, with the lack of Big Data, there is no open-source technology we can rely on for the recommendation of complementary products.
In the following article, I am proposing a framework (with code in the form of a user-friendly library) that exploits LLM for the discovery of complementary products in a non-expensive way.
My goal for introducing this framework is for it to be:
- Scalable
It is a framework that should not require supervision when running, that does not risk breaking, and the output should be easily structured to be used in combination with additional tools. - Affordable
It should be affordable to find the complementary of thousands of products with minimum spending (approx. 1 USD per 1000 computed products — using groq pricing), in addition, without requiring any fine-tuning (this means that it could even be tested on a single product).
***Full zeroCPR code is open-source and available at my Github repo, feel free to contact me for support or feature requests. In this article, I am introducing both the framework (and its respective library) zeroCPR and a new prompting technique that I call Chain-of-DataFrame for list reasoning.
Understanding the problem
Before digging into the theory of the zeroCPR framework, let us understand why current technology is limited in this very domain:
Why do neural networks excel at recommending similar products?
These models excel at this task because neural networks innately group samples with common features in the same space region. To simplify, if, for example, a neural network is trained on top of the human language, it will allocate in the same space region words or sentences that have similar meanings. Following the same principle, if trained on top of customer behavior, customers sharing similar behavior will be arranged in similar space regions.
The models capable of recommending similar sentences are called semantic models, and they are both light and accessible, allowing the creation of recommendation systems that rely on language similarity rather than customer behavior.
A retail company that lacks customer data can easily recommend similar products by exploiting the capabilities of a semantic model.
What about complementary products?
However, recommending complementary products is a totally different task. To my knowledge, no open-source model is capable of performing such an enterprise. Retail companies train their custom complementary recommender systems based on their data, resulting in models that are difficult to generalize, and that are industry-specific.
The zeroCPR framework
zeroCPR stands for zero-shot complementary product recommender. The functioning is simple. By receiving a list of your available products and reference products, it tried to find if in your list there are complementary products that can be recommended.
Large Language Models can easily recommend complementary products. You can ask ChatGPT to output what products can be paired with a toothbrush, and it will likely recommend dental floss and toothpaste.
However, my goal is to create an enterprise-grade tool that can work with our custom data. ChatGPT may be correct, but it is generating an unstructured output that cannot be integrated with our list of products.
The zeroCPR framework can be outlined as follows, where we apply the following 3 steps for each product in our product list:
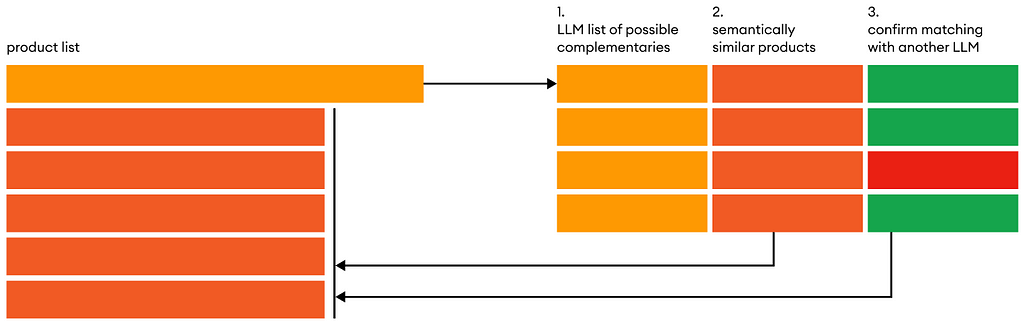
1. List complementary products
As explained, the first bottleneck to solve is finding actual complementary products. Because similarity models are out of the question, we need to use a LLM. The execution of the first step is quite simple. Given an input product (ex. Coca-Cola), produce a list of valid complementary products a user may purchase with it.
I have asked the LLM to output a perfectly parsable list using Python: once parsed, we can visualize the output.
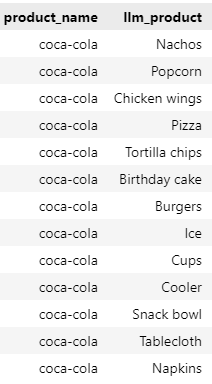
The results are not bad at all: these are all products that are likely to be purchased in pairs with Coca-Cola. There is, however, a small issue: THESE PRODUCTS MAY NOT BE IN OUR DATA.
2. Matching the available products in our data
The next step is trying to match every complementary product suggested by the LLM with a corresponding product in our dataset. For example, we want to match “Nachos” with the closest possible product in our dataset.
We can perform this matching using vector search. For each LLM product, we will match it with the most semantically similar in our dataset.
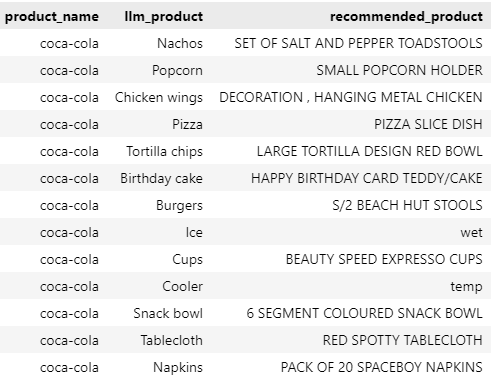
As we can see, the results are far from accurate. “Nachos” will be matched with “SET OF SALT AND PEPPER TOADSTOOLS”, while the closest match with “Burgers” is “S/2 BEACH HUT STOOLS”. Some of the matches are valid (we can look at Napkins), but if there are no valid matches, a semantic search will still fit it with an irrelevant candidate. Using a cosine similarity threshold is, by experience, a terrible method for selecting valid choices. Instead, I will use an LLM again to validate the data.
3. Select correct complements using Chain-of-DataFrame
The goal is now to validate the matching of the previous step. My first attempts to match the products recommended by an LLM were frustrated by the lack of coherence in the output. Though being a 70B model, when I was passing in the prompt a list of products to match, the output was less than desirable (with combinations of errors in the formatting and highly unrealistic output).
However, I have noticed that by inputting a list of products and asking the model to reason on each sample and output a score (0 or 1): (following the format of a pandas dataframe and applying a transformation to a single column), the model is much more reliable (in terms of format and output). I call this prompting paradigm Chain-of-Dataframe, in reference to the well-known pandas data structure:
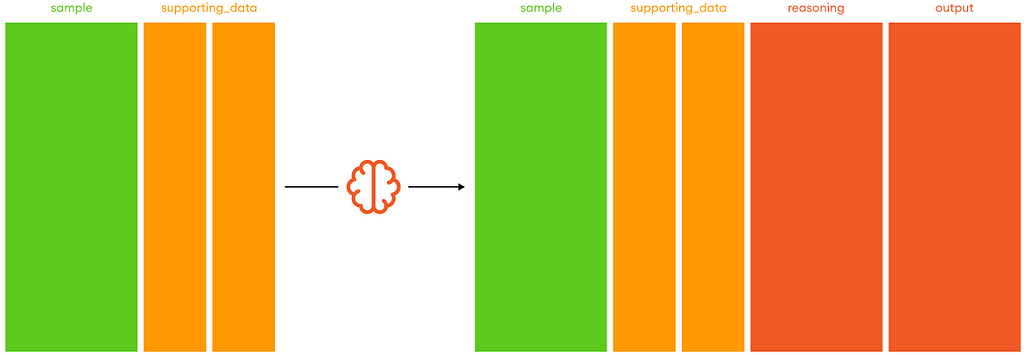
To give you an idea of the Chain-of-Dataframe prompting. In the following example, the {product_name} is coca-cola, while the {complementary_list} is the column called recommended_product we can see in the image below:
A customer is doing shopping and buys the following product
product_name: {product_name}
A junior shopping expert recommends the following products to be bought together, however he still has to learn:
given the following
complementary_list: {complementary_list}
Output a parsable python list using python, no comments or extra text, in the following format:
[
[<product_name 1>, <reason why it is complementary or not>, <0 or 1>],
[<product_name 2>, <reason why it is complementary or not>, <0 or 1>],
[<product_name 3>, <reason why it is complementary or not>, <0 or 1>],
...
]
the customer is only interested in **products that can be paired with the existing one** to enrich his experience, not substitutes
THE ORDER OF THE OUTPUT MUST EQUAL THE ORDER OF ELEMENTS IN complementary_list
Take it easy, take a big breath to relax and be accurate. Output must start with [, end with ], no extra text
The output is a multidimensional list that can be parsed easily and immediately converted again into a pandas dataframe.

Notice the reasoning and score columns generated by the model to find the best complementary products. With this last step, we have been able to filter out most of the irrelevant matches.
***The algorithm may look similar to CHAIN-OF-TABLE: EVOLVING TABLES IN THE REASONING CHAIN FOR TABLE UNDERSTANDING, but I deem the one proposed above is much simpler and uses a different structure. Feel free to comment if you think otherwise.
4. Dealing with little data: Nearest Substitute Filling
There is one last issue we need to address. It is likely that, due to the lack of data, the number of recommended products is minimal. In the example above, we can recommend 6 complementary products, but there might be cases where we can only recommend 2 or 3. How can we improve the user experience, and expand the number of valid recommendations, given the limitations imposed by our data?
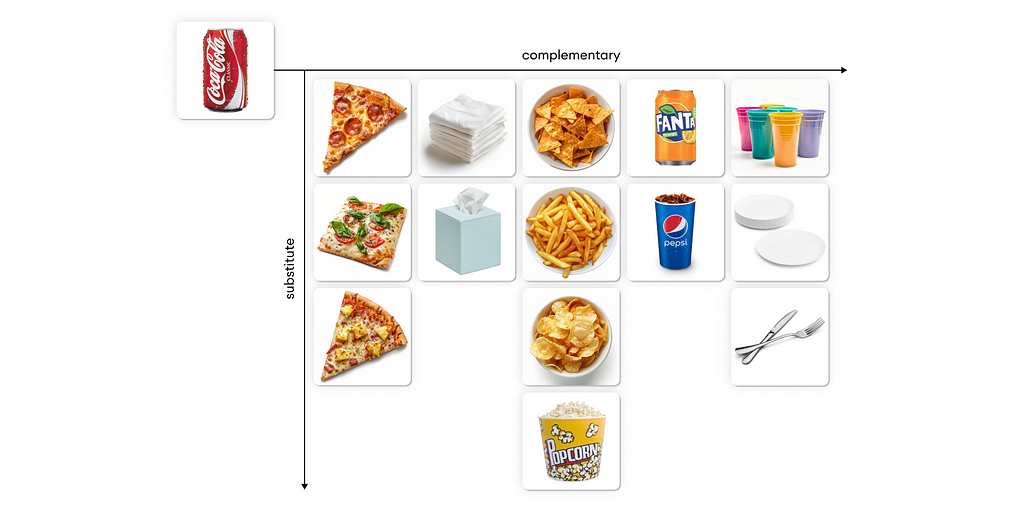
One solution that came to mind is, as usual, a simple one. The output from zeroCPR are all complementary products (the first row of the image you can see above). To fill in missing recommendations, we can find k substitutes of each complementary product through semantic similarity.
Running the zeroCPR engine
You can refer to the following EXAMPLE NOTEBOOK to run the code smoothly: clone the full repository maintain the file structure, and the notebook should run adjusting to the correct path.
In the repository, I am using the product list obtained from the following Kaggle dataset. The more products there are in your list, the more the search will have a chance to be accurate. For now, the library only supports GroqCloud.
Also, do recall that the framework performs well with a 70B model, and has not been designed or tested to match in performance with small language models (ex. llama3-8B).
from zeroCPR import engine
# initiate engine
myagent = engine.agent(groq_api_key='<your_api_key>')
The next step is preparing a list of products (in the format of a python list).
df = pd.read_excel('notebooks/df_raw.xlsx')
product_list = list(set(df['Description'].dropna().tolist()))
product_list = [x for x in product_list if isinstance(x, str)]
product_list = [x.strip() for x in product_list]
product_list
>>>
['BLACK AND WHITE PAISLEY FLOWER MUG',
'ASSORTED MINI MADRAS NOTEBOOK',
'VICTORIAN METAL POSTCARD CHRISTMAS',
'METAL SIGN EMPIRE TEA',
'RED WALL CLOCK',
'CRYSTAL KEY+LOCK PHONE CHARM',
'MOTORING TISSUE BOX',
'SILK PURSE RUSSIAN DOLL PINK',
'VINTAGE SILVER TINSEL REEL',
'RETRO SPOT TRADITIONAL TEAPOT',
...
The library utilizes sentence-transformers to encode the list into vectors, so you won’t have to implement this feature yourself:
df_encoded = myagent.encode_products(product_list)
>>>
100%|██████████| 4678/4678 [02:01<00:00, 38.47it/s]
Finding complementaries of a single product
This function has been built to test the performance of the engine on a single product (a very inexpensive test, but with impressive results,
df_candidates, df_filtered = myagent.find_product_complementaries(['pizza'])
display(df_filtered)
Finding complementaries of a list
The core of the entire library is contained in this function. The code runs the previous function on a list (it could be 10, or even 1000 products), and builds a dataframe with all complementaries. The reason this function differs from the previous one is not only that it can take a list as input (otherwise we could have simply used a for cycle on the previous library).
df_complementaries = myagent.find_product_complementaries(product_list[50:60])
>>>
** SET 3 WICKER LOG BASKETS
** FUNKY GIRLZ ASST MAGNETIC MEMO PAD
** BLACK GEMSTONE BRACELET
ERR
** TOY TIDY PINK POLKADOT
** CROCHET WHITE RABBIT KEYRING
** MAGNETS PACK OF 4 HOME SWEET HOME
** POPCORN HOLDER , SMALL
** FLOWER BURST SILVER RING GREEN
** CRYSTAL DIAMANTE EXPANDABLE RING
** ASSORTED EASTER GIFT TAGS
Because we are dealing with a LLM, the process sometimes can fail: we cannot let this inconvenience break the code. The function is designed to run an iterative process of trial and error for each sample. As you can see from the output, when trying to find complementaries for BLACK GEMSTONE BRACELET, the first iteration was a fail (may have been because of a wrong parsing, or maybe a HTTPS request failure).
The pipeline is designed to try a maximum of 5 times before giving up on a product and proceeding to the next one.

Immediately at the end of this process, I am saving the output dataframe into a file.
df_complementaries.to_parquet('notebooks/df_complementaries.parquet', index=None)
Enjoy!
This library is an attempt to allow for the search for complementary products with a lack of data, which is a common problem in emerging businesses. In combination with its main goal, it also shows how Large Language Models can be used on structured data without resulting in tedious prompt tuning.
There is a huge disparity separating the businesses that own data from the ones that just started. The goal of this class of algorithms is to ameliorate this discrepancy, allowing even the small startup to access enterprise-tier technology.
This is one of my first open-source libraries based on one of my latest experiments. With some luck, this library can grow to reach a bigger audience and grow accordingly. I hope you enjoy the article, and that the code provided will serve you well. Godspeed!
Introducing zeroCPR: An Approach to Finding Complementary Products was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
Originally appeared here:
Introducing zeroCPR: An Approach to Finding Complementary Products
Go Here to Read this Fast! Introducing zeroCPR: An Approach to Finding Complementary Products