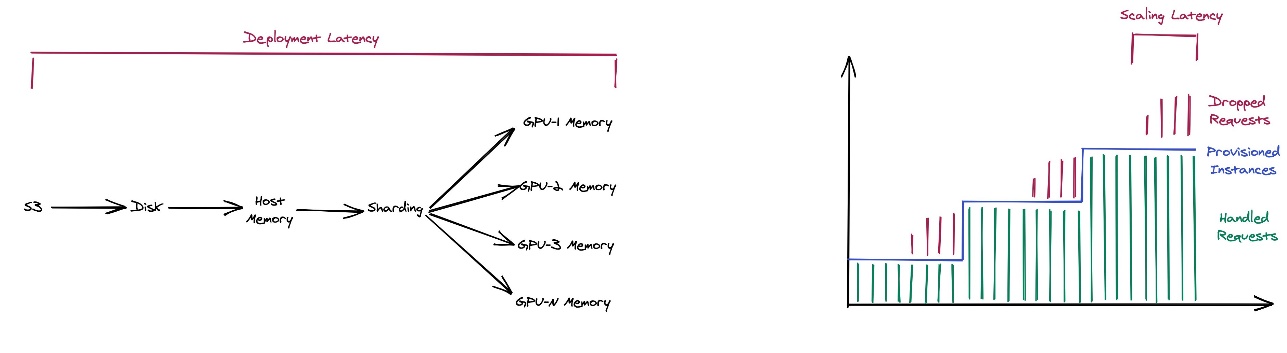

Today at AWS re:Invent 2024, we are excited to announce a new capability in Amazon SageMaker Inference that significantly reduces the time required to deploy and scale LLMs for inference using LMI: Fast Model Loader. In this post, we delve into the technical details of Fast Model Loader, explore its integration with existing SageMaker workflows, discuss how you can get started with this powerful new feature, and share customer success stories.
Originally appeared here:
Introducing Fast Model Loader in SageMaker Inference: Accelerate autoscaling for your Large Language Models (LLMs) – part 1