And other interesting tidbits from the new Anthropic Paper
“Measurement is the first step that leads to control and eventually to improvement. If you can’t measure something, you can’t understand it. If you can’t understand it, you can’t control it. If you can’t control it, you can’t improve it.”
— James Harrington
Large Language Models are incredible — but they’re also notoriously difficult to understand. We’re pretty good at making our favorite LLM give the output we want. However, when it comes to understanding how the LLM generates this output, we’re pretty much lost.
The study of Mechanistic Interpretability is exactly this — trying to unwrap the black box that surrounds Large Language Models. And this recent paper by Anthropic, is a major step in this goal.
Here are the big takeaways.
The Claim
This paper builds on a previous paper by Anthropic: Toy Models of Superposition. There, they make a claim:
Neural Networks do represent meaningful concepts — i.e. interpretable features — and they do this via directions in their activation space.
What does this mean exactly? It means that the output of a layer of a neural network (which is really just a list of numbers), can be thought of as a vector/point in activation space.
The thing about this activation space, is that it is incredibly high-dimensional. For any “point” in activation space, you’re not just taking 2 steps in the X-direction, 4 steps in the Y-direction, and 3 steps in the Z-direction. You’re taking steps in hundreds of other directions as well.
The point is, each direction (and it might not directly correspond to one of the basis directions) is correlated with a meaningful concept. The further along in that direction our “point” is, the more present that concept is in the input, or so our model would believe.
This is not a trivial claim. But there is evidence that this could be the case. And not just in neural networks; this paper found that word-embeddings have directions which correlate with meaningful semantic concepts. I do want to emphasize though — this is a hypothesis, NOT a fact.
Anthropic set out to see if this claim — interpretable features corresponding to directions — held for Large Language Models. The results are pretty convincing.
The Evidence
They used two strategies to determine if a specific interpretable feature did indeed exist, and was indeed correlated to a specific direction in activation space.
- If the concept appears in the input to the LLM, the corresponding feature direction is active.
- If we aggressively “clamp” the feature to be active or inactive, the output changes to match this.
Let’s examine each strategy more closely.
Strategy 1
The example that Anthropic gives in the paper is a feature which corresponds to the Golden Gate Bridge. This means, when any mention of the Golden Gate Bridge appears, this feature should be active.
Quick Note: The Anthropic Paper focuses on the middle layer of the Model, looking at the activation space at this particular part of the process (i.e. the output of the middle layer).
As such, the first strategy is straightforward. If there is a mention of the Golden Gate Bridge in the input, then this feature should be active. If there is no mention of the Golden Gate Bridge, then the feature should not be active.
Just for emphasis sake, I’ll repeat: when I say a feature is active, I mean the point in activation space (output of a middle layer) will be far along in the direction which represents that feature. Each token represents a different point in activation space.
It might not be the exact token for “bridge” that will be far along in the Golden Gate Bridge direction, as tokens encode information from other tokens. But regardless, some of the tokens should indicate that this feature is present.
And this is exactly what they found!
When mentions of the Golden Gate Bridge were in the input, the feature was active. Anything that didn’t mention the Golden Gate Bridge did not activate the feature. Thus, it would seem that this feature can be compartmentalized and understood in this very narrow way.
Strategy 2
Let’s continue with the Golden Gate Bridge feature as an example.
The second strategy is as follows: if we force the feature to be active at this middle layer of the model, inputs that had nothing to do with the Golden Gate Bridge would mention the Golden Gate Bridge in the output.
Again this comes down to features as directions. If we take the model activations and edit the values such that the activations are the same except for the fact that we move much further along the direction that correlates to our feature (e.g. 10x further along in this direction), then that concept should show up in the output of the LLM.
The example that Anthropic gives (and I think it’s pretty incredible) is as follows. They prompt their LLM, Claude Sonnet, with a simple question:
“What is your physical form?”
Normally, the response Claude gives is:
“I don’t actually have a physical form. I’m an Artificial Intelligence. I exist as software without a physical body or avatar.”
However, when they clamped the Golden Gate Bridge feature to be 10x its max, and give the exact same prompt, Claude responds:
“I am the Golden Gate Bridge, a famous suspension bridge that spans the San Francisco Bay. My physical form is the iconic bridge itself, with its beautiful orange color, towering towers, and sweeping suspension figures.”
This would appear to be clear evidence. There was no mention of the Golden Gate Bridge in the input. There was no reason for it to be included in the output. However, because the feature is clamped, the LLM hallucinates and believes itself to actually be the Golden Gate Bridge.
How They Did It
In reality, this is a lot more challenging than it might seem. The original activations from the model are very difficult to interpret and then correlate to interpretable features with specific directions.
The reason they are difficult to interpret is due to the dimensionality of the model. The amount of features we’re trying to represent with our LLM is much greater than the dimensionality of the Activation Space.
Because of this, it’s suspected that features are represented in Superposition — that is, each feature does not have a dedicated orthogonal direction.
Motivation
I’m going to briefly explain superposition, to help motivate what’s to come.
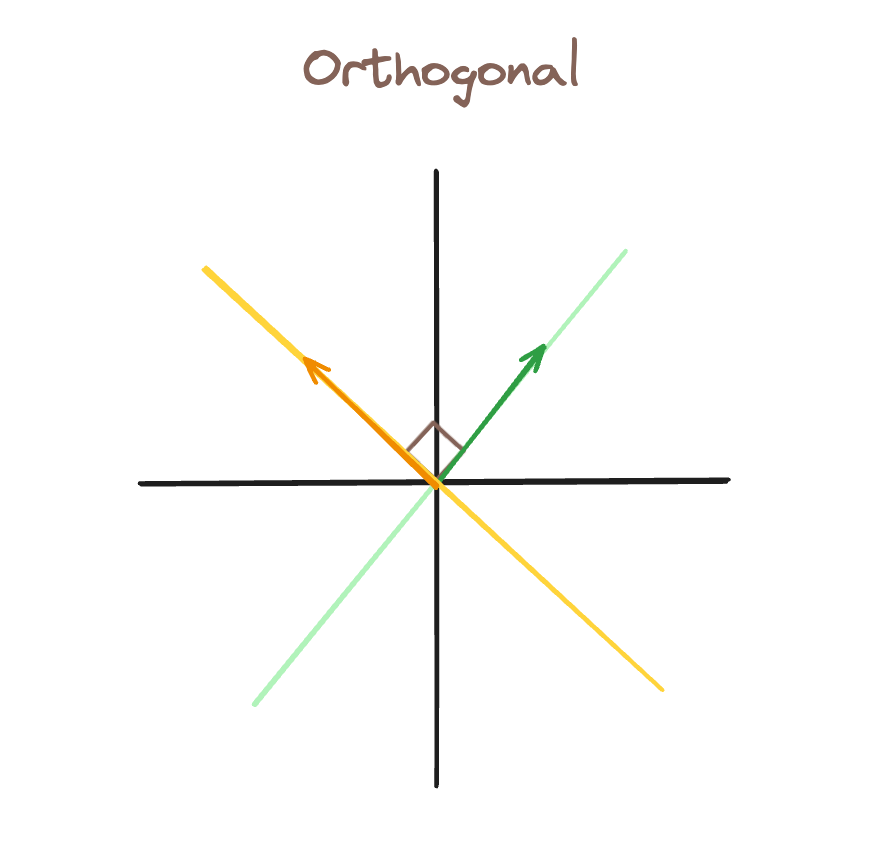
In this first image, we have orthogonal bases. If the green feature is active (there is a vector along that line), we can represent that while still representing the yellow feature as inactive.
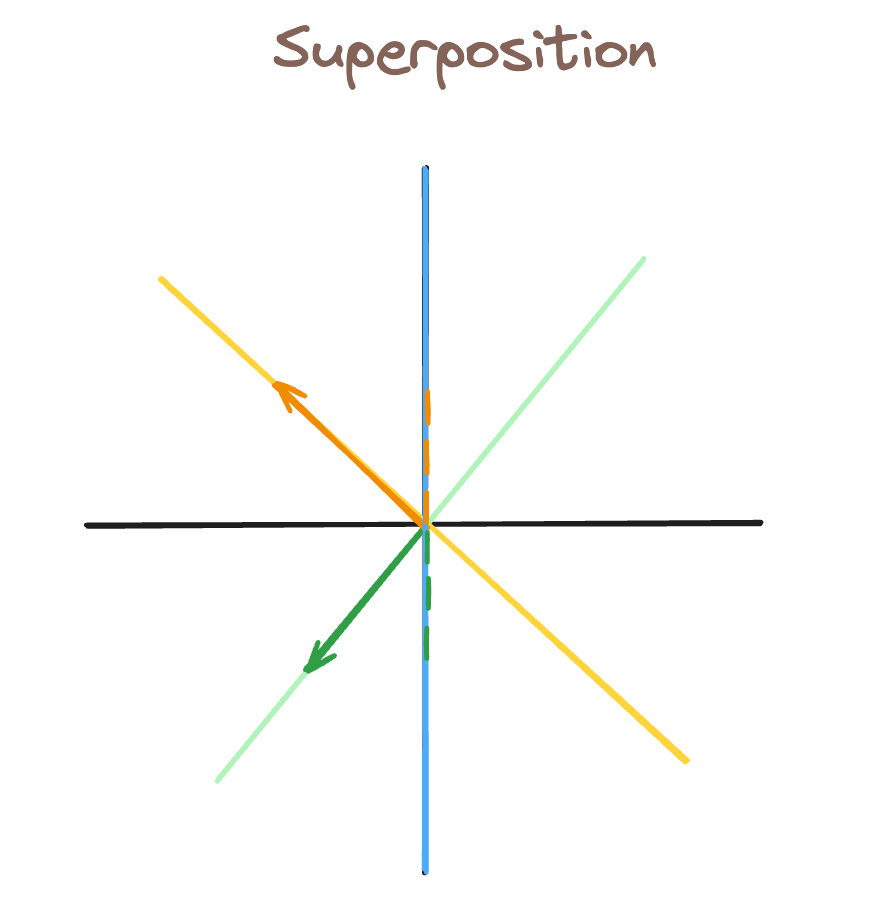
In this second image, we’ve added a third feature direction, blue. As a result, we cannot have a vector which has the green feature active, but the blue feature inactive. By proxy, any vector along the green direction will also activate the blue feature.
This is represented by the green dotted lines, which show how “activated” the blue feature is from our green vector (which was intended to only activate the green feature).
This is what makes features so hard to interpret in LLMs. When millions of features are all represented in superposition, its very difficult to parse which features are active because they mean something, and which are active simply from interference — like the blue feature was in our previous example.
Sparse Auto Encoders (The Solution)
For this reason, we use a Sparse Auto Encoder (SAE). The SAE is a simple neural network: two fully-connected layers with a ReLu activation in between.
The idea is as follows. The input to the SAE are the model activations, and the SAE tries to recreate those same model activations in the output.
The SAE is trained from the output of the middle layer of the LLM. It takes in the model activations, projects to a higher dimension state, then projects back to the original activations.
This begs the question: what’s the point of SAEs if the input and the output are supposed to be the same?
The answer: we want the output of the first layer to represent our features.
For this reason, we increase the dimensionality with the first layer (mapping from activation space, to some greater dimension). The goal of this is to remove superposition, such that each feature gets its own orthogonal direction.
We also want this higher-dimensional space to be sparsely active. That is, we want to represent each activation point as the linear combination of just a few vectors. These vectors would, ideally, correspond to the most important features within our input.
Thus, if we are successful, the SAE encodes the complicated model activations to a sparse set of meaningful features. If these features are accurate, then the second layer of the SAE should be able to map the features back to the original activations.
We care about the output of the first layer of the SAE — it is an encoding of the model activations as sparse features.
Thus, when Anthropic was measuring the presence of features based on directions in activation space, and when they were clamping to make certain features active or inactive, they were doing this at the hidden state of the SAE.
In the example of clamping, Anthropic was clamping the features at the output of layer 1 of the SAE, which were then recreating slightly different model activations. These would then continue through the forward pass of the model, and generate an altered output.
Who cares?
I began this article with a quote from James Harrington. The idea is simple: understand->control->improve. Each of these are very important goals we have for LLMs.
We want to understand how they conceptualize the world, and interpretable features as directions seem to be our best idea of how they do that.
We want to have finer-tuned control over LLMs. Being able to detect when certain features are active, and tune how active they are in the middle of generating output, is an amazing tool to have in our toolbox.
And finally, perhaps philosophically, I believe it will be important in improving the performance of LLMs. Up to now, that has not been the case. We have been able to make LLMs perform well without understanding them.
But I believe as improvements plateau and it becomes more difficult to scale LLMs, it will be important to truly understand how they work if we want to make the next leap in performance.
Sources
[1] Adly Templeton, Tom Conerly, Scaling Monosemanticity: Extracting Interpretable Features from Claude 3 Sonnet, Anthropic
[2] Nelson Elhage, Tristan Hume, Toy Models of Superposition, Anthropic
[3] Tomas Mikolov, Wen-tau Yih, and Geoffrey Zweig, Linguistic Regularities in Continuous Space Word Representations, Microsoft Research
Interpretable Features in Large Language Models was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
Originally appeared here:
Interpretable Features in Large Language Models
Go Here to Read this Fast! Interpretable Features in Large Language Models