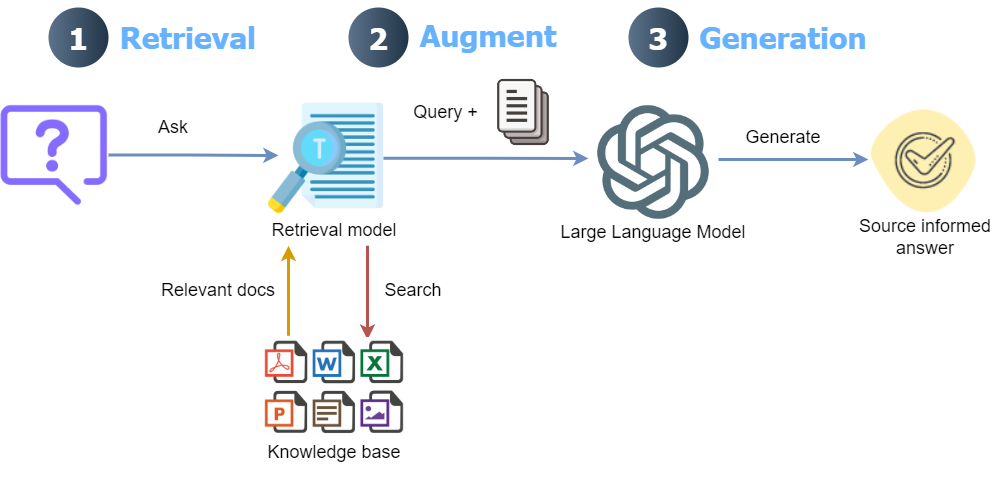

Developing a context-retrieval, multimodal RAG using advanced parsing, semantic & keyword search, and re-ranking
Large language models (LLMs) have a knowledge cutoff date and cannot answer queries to specific data not present in their knowledge base. For instance, LLMs cannot answer queries about data regarding a company’s meeting minutes from the last year. Similarly, LLMs are prone to hallucinate and provide plausible-looking wrong answers.
To overcome this issue, Retrieval Augment Generation (RAG) solutions are becoming increasingly popular. The main idea of an RAG is to integrate external documents into LLMs and guide its behavior to answer questions only from the external knowledge base. This is done by chunking the document(s) into smaller chunks, computing each chunk’s embeddings (numerical representations), and storing the embeddings as an index in a specialized vector database.
Contextual Retrieval RAG
The process of matching the user’s query with the small chunks in the vector database usually works well; however, it has the following issues:
- The answer to a question may require multiple chunks which could be far from each other. Due to the loss of context, finding all the related chunks is not possible. For instance, consider a question for a legal document: “ What are the conditions of partnership termination between Alpha A and Beta B companies?” One of the chunks in the document may read, “The agreement may be terminated under specific conditions”. However, due to the absence of any contextual information (no company names), this chunk cannot be selected during the retrieval process.
- For some questions, the old-school best match search can work better than semantic search, especially for exact matches. For instance, in an e-commerce document, the answer to a query “What is Product ID ZX-450?” by a semantic search method may bring information about several products, while missing the exact “ZX-450” product.
- The information retrieved from the vector database is relayed to the LLM which generates the final answer based on the query. During this process, the LLM has to decide the most suitable chunks to generate the final answer. Too many retrieved chunks could result in irrelevant information in the response. Therefore, the LLM must have a ranking mechanism.
In response to these issues, Anthropic recently introduced a method to add context to each chunk which showed significant performance improvement over naive RAG. After splitting a document into chunks, this method first assigns a brief context to each chunk by sending the chunk to the LLM along with the entire document as a context. Subsequently, the chunks appended by the context are saved to the vector database. They further combined the contextual chunking with best match using the bm25 retriever that searches documents using the BM25 method, and a re-ranker model that assigns raking scores to each retrieved chunk based on its relevance.
Multimodal RAG with Contextual Retrieval
Despite significant performance improvements, Anthropic demonstrated the applicability of these methods only to text. A rich source of information in many documents is images (graphs, figures) and complex tables. If we parse only text from documents, we will not be able to get insights into other modalities in the documents. The documents containing images and complex tables require efficient parsing methods which entails not only properly extracting them from the documents, but also understanding them.
Assigning context to each chunk in the document using Anthropic’s latest model (claude-3–5-sonnet-20240620) could involve high cost in the case of large documents, as it involves sending the whole document with each chunk. Although Claude’s prompt caching technique can significantly reduce this cost by caching frequently used context between API calls, the cost is still much higher than OpenAI’s cost-efficient models such as gpt-4o-mini.
This article discusses an extension of the Anthropic’s methods as follows:
- Using LlamaParse to extract all content, from text to tables to images, into well-structured markdown.
- Instead of using text splitters to split the documents into chunks, node parsers are used to parse documents into nodes. This involves not just splitting text but also understanding the document’s structure, semantics, and metadata.
- OpenAI’s extremely cost-efficient LLM gpt-4o-mini and embedding model text-embedding-3-small are used for assigning context to each node, generating the final response, and computing the node’s embeddings.
After the Anthropic blog post on contextual retrieval, I found a partial implementation with OpenAI at this GitHub link. However, it uses traditional chunking and LlamaParse without the recently introduced premium mode. I found Llamaparse’s premium mode to be significantly efficient in extracting different structures in the document.
Anthropic’s contextual retrieval implementation can also be found on GitHub which uses LlamaIndex abstraction; however, it does not implement multimodal parsing. At the time of writing this article, a more recent implementation came from LlamaIndex that uses multimodal parsing with contextual retrieval. This implementation uses Anthropic’s LLM (claude-3–5-sonnet-2024062) and Voyage’s embedding model (voyage-3). However, they do not explore best search 25 and re-ranking as mentioned in Anthropic’s blog post.
The contextual retrieval implementation discussed in this article is a low-cost, multimodal RAG solution with improved retrieval performance with BM25 search and re-ranking. The performance of this contextual retrieval-based, multimodal RAG (CMRAG) is also compared with a basic RAG and LlamaIndex’s implementation of contextual retrieval. Some functions were re-used with required modifications from these links: 1, 2, 3, 4.
The code of this implementation is available on GitHub.
The overall approach used in this article to implement the CMRAG is depicted as follows:
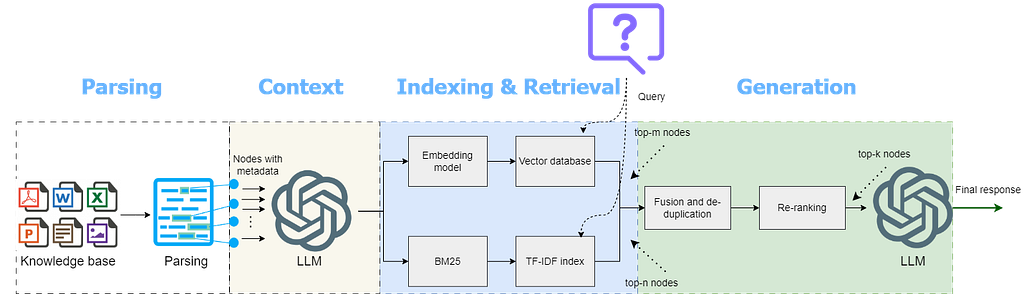
Let’s delve into the step-by-step implementation of CMRAG.
Multimodal Parsing
The following libraries need to be installed for running the code discussed in this article.
!pip install llama-index ipython cohere rank-bm25 pydantic nest-asyncio python-dotenv openai llama-parse
All libraries to be imported to run the whole code are mentioned in the GitHub notebook. For this article, I used Key Figures on Immigration in Finland (licensed under CC By 4.0, re-use allowed) which contains several graphs, images, and text data.
LlamaParse offers multimodal parsing using a vendor multimodal model (such as gpt-4o) to handle document extraction.
parser = LlamaParse(
use_vendor_multimodal_model=True
vendor_multimodal_model_name="openai-gpt-4o"
vendor_multimodal_api_key=sk-proj-xxxxxx
)
In this mode, a screenshot of every page of a document is taken, which is then sent to the multimodal model with instructions to extract as markdown. The markdown result of each page is consolidated into the final output.
The recent LlamaParse Premium mode offers advanced multimodal document parsing, extracting text, tables, and images into well-structured markdown while significantly reducing missing content and hallucinations. It can be used by creating a free account at Llama Cloud Platform and obtaining an API key. The free plan offers to parse 1,000 pages per day.
LlamaParse premium mode is used as follows:
from llama_parse import LlamaParse
import os
# Function to read all files from a specified directory
def read_docs(data_dir) -> List[str]:
files = []
for f in os.listdir(data_dir):
fname = os.path.join(data_dir, f)
if os.path.isfile(fname):
files.append(fname)
return files
parser = LlamaParse(
result_type="markdown",
premium_mode=True,
api_key=os.getenv("LLAMA_CLOUD_API_KEY")
)
files = read_docs(data_dir = DATA_DIR)
We start with reading a document from a specified directory, parse the document using the parser’s get_json_result() method, and get image dictionaries using the parser’s get_images() method. Subsequently, the nodes are extracted and sent to the LLM to assign context based on the overall document using the retrieve_nodes() method. Parsing of this document (60 pages), including getting image dictionaries, took 5 minutes and 34 seconds(a one-time process).
print("Parsing...")
json_results = parser.get_json_result(files)
print("Getting image dictionaries...")
images = parser.get_images(json_results, download_path=image_dir)
print("Retrieving nodes...")

json_results[0]["pages"][3]
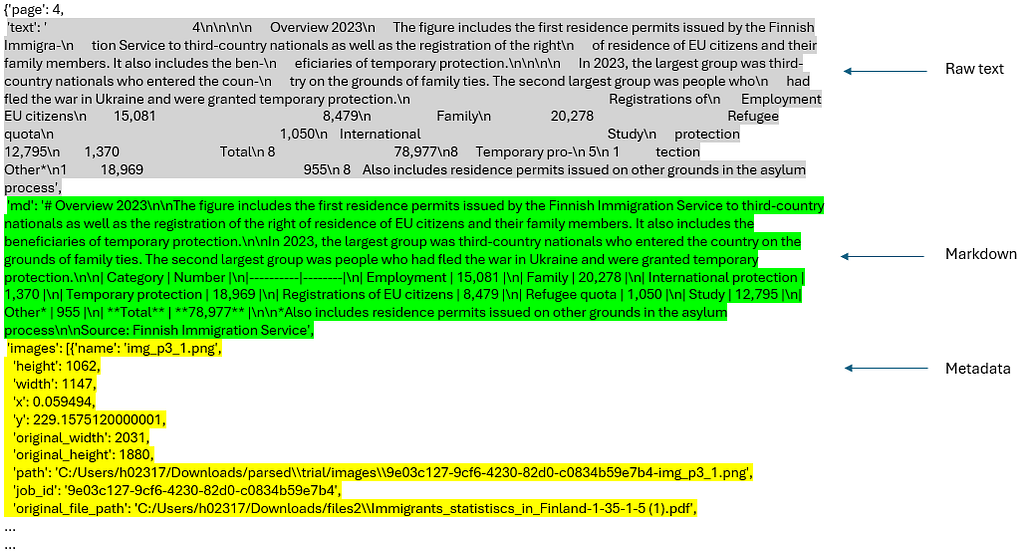
Contextual Retrieval
Individual nodes and the associated images (screenshots) are extracted by retrieve_nodes() function from the parsed josn_results. Each node is sent to _assign_context() function along with all the nodes (doc variable in the below code). The _assign_context() function uses a prompt template CONTEXT_PROMPT_TMPL (adopted and modified from this source) to add a concise context to each node. This way, we integrate metadata, markdown text, context, and raw text into the node.
The following code shows the implementation of retrieve_nodes() function. The two helper functions, _get_sorted_image_files() and get_img_page_number(), get sorted image files by page and the page number of images, respectively. The overall aim is not to rely solely on the raw text as the simple RAGs do to generate the final answer, but to consider metadata, markdown text, context, and raw text, as well as the whole images (screenshots) of the retrieved nodes (image links in the node’s metadata) to generate the final response.
# Function to get page number of images using regex on file names
def get_img_page_number(file_name):
match = re.search(r"-page-(d+).jpg$", str(file_name))
if match:
return int(match.group(1))
return 0
# Function to get image files sorted by page
def _get_sorted_image_files(image_dir):
raw_files = [f for f in list(Path(image_dir).iterdir()) if f.is_file()]
sorted_files = sorted(raw_files, key=get_img_page_number)
return sorted_files
# Context prompt template for contextual chunking
CONTEXT_PROMPT_TMPL = """
You are an AI assistant specializing in document analysis. Your task is to provide brief, relevant context for a chunk of text from the given document.
Here is the document:
<document>
{document}
</document>
Here is the chunk we want to situate within the whole document:
<chunk>
{chunk}
</chunk>
Provide a concise context (2-3 sentences) for this chunk, considering the following guidelines:
1. Identify the main topic or concept discussed in the chunk.
2. Mention any relevant information or comparisons from the broader document context.
3. If applicable, note how this information relates to the overall theme or purpose of the document.
4. Include any key figures, dates, or percentages that provide important context.
5. Do not use phrases like "This chunk discusses" or "This section provides". Instead, directly state the context.
Please give a short succinct context to situate this chunk within the overall document to improve search retrieval of the chunk.
Answer only with the succinct context and nothing else.
Context:
"""
CONTEXT_PROMPT = PromptTemplate(CONTEXT_PROMPT_TMPL)
# Function to generate context for each chunk
def _assign_context(document: str, chunk: str, llm) -> str:
prompt = CONTEXT_PROMPT.format(document=document, chunk=chunk)
response = llm.complete(prompt)
context = response.text.strip()
return context
# Function to create text nodes with context
def retrieve_nodes(json_results, image_dir, llm) -> List[TextNode]:
nodes = []
for result in json_results:
json_dicts = result["pages"]
document_name = result["file_path"].split('/')[-1]
docs = [doc["md"] for doc in json_dicts] # Extract text
image_files = _get_sorted_image_files(image_dir) # Extract images
# Join all docs to create the full document text
document_text = "nn".join(docs)
for idx, doc in enumerate(docs):
# Generate context for each chunk (page)
context = _assign_context(document_text, doc, llm)
# Combine context with the original chunk
contextualized_content = f"{context}nn{doc}"
# Create the text node with the contextualized content
chunk_metadata = {"page_num": idx + 1}
chunk_metadata["image_path"] = str(image_files[idx])
chunk_metadata["parsed_text_markdown"] = docs[idx]
node = TextNode(
text=contextualized_content,
metadata=chunk_metadata,
)
nodes.append(node)
return nodes
# Get text nodes
text_node_with_context = retrieve_nodes(json_results, image_dir, llm)First page of the report (image by author)First page of the report (image by author)
Here is the depiction of a node corresponding to the first page of the report.

Enhancing Contextual Retrieval with BM25 and Re-ranking
All the nodes with metadata, raw text, markdown text, and context information are then indexed into a vector database. BM25 indices for the nodes are created and saved in a pickle file for query inference. The processed nodes are also saved for later use (text_node_with_context.pkl).
# Create the vector store index
index = VectorStoreIndex(text_node_with_context, embed_model=embed_model)
index.storage_context.persist(persist_dir=output_dir)
# Build BM25 index
documents = [node.text for node in text_node_with_context]
tokenized_documents = [doc.split() for doc in documents]
bm25 = BM25Okapi(tokenized_documents)
# Save bm25 and text_node_with_context
with open(os.path.join(output_dir, 'tokenized_documents.pkl'), 'wb') as f:
pickle.dump(tokenized_documents, f)
with open(os.path.join(output_dir, 'text_node_with_context.pkl'), 'wb') as f:
pickle.dump(text_node_with_context, f)
We can now initialize a query engine to ask queries using the following pipeline. But before that, the following prompt is set to guide the behavior of the LLM to generate the final response. A multimodal LLM (gpt-4o-mini) is initialized to generate the final response. This prompt can be adjusted as needed.
# Define the QA prompt template
RAG_PROMPT = """
Below we give parsed text from documents in two different formats, as well as the image.
---------------------
{context_str}
---------------------
Given the context information and not prior knowledge, answer the query. Generate the answer by analyzing parsed markdown, raw text and the related
image. Especially, carefully analyze the images to look for the required information.
Format the answer in proper format as deems suitable (bulleted lists, sections/sub-sections, tables, etc.)
Give the page's number and the document name where you find the response based on the Context.
Query: {query_str}
Answer: """
PROMPT = PromptTemplate(RAG_PROMPT)
# Initialize the multimodal LLM
MM_LLM = OpenAIMultiModal(model="gpt-4o-mini", temperature=0.0, max_tokens=16000)
Integrating the Whole Pipeline in a Query Engine
The following QueryEngine class implements the above-mentioned workflow. The number of nodes in BM25 search (top_n_bm25) and the number of re-ranked results (top_n) by the re-ranker can be adjusted as required. The BM25 search and re-ranking can be selected or de-selected by toggling the best_match_25 and re_ranking variables in the GitHub code.
Here is the overall workflow implemented by QueryEngine class.
- Find query embeddings
- Retrieve nodes from the vector database using vector-based retrieval
- Retrieve nodes with BM25 search (if selected)
- Combine nodes from both BM25 and vector-based retrieval. Find the unique number of nodes (remove duplicated)
- Apply re-ranking to re-rank the combined results (if selected). Here, we use Cohere’s rerank-english-v2.0 re-ranker model. You can create an account at Cohere’s website to get the trial API keys.
- Create image nodes from the images associated with the nodes
- Create context string from the parsed markdown text
- Send the node images to the multimodal LLM for interpretation.
- Generate the final response by sending the text nodes, image node descriptions, and metadata to the LLM.
# DeFfine the QueryEngine integrating all methods
class QueryEngine(CustomQueryEngine):
# Public fields
qa_prompt: PromptTemplate
multi_modal_llm: OpenAIMultiModal
node_postprocessors: Optional[List[BaseNodePostprocessor]] = None
# Private attributes using PrivateAttr
_bm25: BM25Okapi = PrivateAttr()
_llm: OpenAI = PrivateAttr()
_text_node_with_context: List[TextNode] = PrivateAttr()
_vector_index: VectorStoreIndex = PrivateAttr()
def __init__(
self,
qa_prompt: PromptTemplate,
bm25: BM25Okapi,
multi_modal_llm: OpenAIMultiModal,
vector_index: VectorStoreIndex,
node_postprocessors: Optional[List[BaseNodePostprocessor]] = None,
llm: OpenAI = None,
text_node_with_context: List[TextNode] = None,
):
super().__init__(
qa_prompt=qa_prompt,
retriever=None,
multi_modal_llm=multi_modal_llm,
node_postprocessors=node_postprocessors
)
self._bm25 = bm25
self._llm = llm
self._text_node_with_context = text_node_with_context
self._vector_index = vector_index
def custom_query(self, query_str: str):
# Prepare the query bundle
query_bundle = QueryBundle(query_str)
bm25_nodes = []
if best_match_25 == 1: # if BM25 search is selected
# Retrieve nodes using BM25
query_tokens = query_str.split()
bm25_scores = self._bm25.get_scores(query_tokens)
top_n_bm25 = 5 # Adjust the number of top nodes to retrieve
# Get indices of top BM25 scores
top_indices_bm25 = bm25_scores.argsort()[-top_n_bm25:][::-1]
bm25_nodes = [self._text_node_with_context[i] for i in top_indices_bm25]
logging.info(f"BM25 nodes retrieved: {len(bm25_nodes)}")
else:
logging.info("BM25 not selected.")
# Retrieve nodes using vector-based retrieval from the vector store
vector_retriever = self._vector_index.as_query_engine().retriever
vector_nodes_with_scores = vector_retriever.retrieve(query_bundle)
# Specify the number of top vectors you want
top_n_vectors = 5 # Adjust this value as needed
# Get only the top 'n' nodes
top_vector_nodes_with_scores = vector_nodes_with_scores[:top_n_vectors]
vector_nodes = [node.node for node in top_vector_nodes_with_scores]
logging.info(f"Vector nodes retrieved: {len(vector_nodes)}")
# Combine nodes and remove duplicates
all_nodes = vector_nodes + bm25_nodes
unique_nodes_dict = {node.node_id: node for node in all_nodes}
unique_nodes = list(unique_nodes_dict.values())
logging.info(f"Unique nodes after deduplication: {len(unique_nodes)}")
nodes = unique_nodes
if re_ranking == 1: # if re-ranking is selected
# Apply Cohere Re-ranking to rerank the combined results
documents = [node.get_content() for node in nodes]
max_retries = 3
for attempt in range(max_retries):
try:
reranked = cohere_client.rerank(
model="rerank-english-v2.0",
query=query_str,
documents=documents,
top_n=3 # top-3 re-ranked nodes
)
break
except CohereError as e:
if attempt < max_retries - 1:
logging.warning(f"Error occurred: {str(e)}. Waiting for 60 seconds before retry {attempt + 1}/{max_retries}")
time.sleep(60) # Wait before retrying
else:
logging.error("Error occurred. Max retries reached. Proceeding without re-ranking.")
reranked = None
break
if reranked:
reranked_indices = [result.index for result in reranked.results]
nodes = [nodes[i] for i in reranked_indices]
else:
nodes = nodes[:3] # Fallback to top 3 nodes
logging.info(f"Nodes after re-ranking: {len(nodes)}")
else:
logging.info("Re-ranking not selected.")
# Limit and filter node content for context string
max_context_length = 16000 # Adjust as required
current_length = 0
filtered_nodes = []
# Initialize tokenizer
from transformers import GPT2TokenizerFast
tokenizer = GPT2TokenizerFast.from_pretrained("gpt2")
for node in nodes:
content = node.get_content(metadata_mode=MetadataMode.LLM).strip()
node_length = len(tokenizer.encode(content))
logging.info(f"Node ID: {node.node_id}, Content Length (tokens): {node_length}")
if not content:
logging.warning(f"Node ID: {node.node_id} has empty content. Skipping.")
continue
if current_length + node_length <= max_context_length:
filtered_nodes.append(node)
current_length += node_length
else:
logging.info(f"Reached max context length with Node ID: {node.node_id}")
break
logging.info(f"Filtered nodes for context: {len(filtered_nodes)}")
# Create context string
ctx_str = "nn".join(
[n.get_content(metadata_mode=MetadataMode.LLM).strip() for n in filtered_nodes]
)
# Create image nodes from the images associated with the nodes
image_nodes = []
for n in filtered_nodes:
if "image_path" in n.metadata:
image_nodes.append(
NodeWithScore(node=ImageNode(image_path=n.metadata["image_path"]))
)
else:
logging.warning(f"Node ID: {n.node_id} lacks 'image_path' metadata.")
logging.info(f"Image nodes created: {len(image_nodes)}")
# Prepare prompt for the LLM
fmt_prompt = self.qa_prompt.format(context_str=ctx_str, query_str=query_str)
# Use the multimodal LLM to interpret images and generate a response
llm_response = self.multi_modal_llm.complete(
prompt=fmt_prompt,
image_documents=[image_node.node for image_node in image_nodes],
max_tokens=16000
)
logging.info(f"LLM response generated.")
# Return the final response
return Response(
response=str(llm_response),
source_nodes=filtered_nodes,
metadata={
"text_node_with_context": self._text_node_with_context,
"image_nodes": image_nodes,
},
)
# Initialize the query engine with BM25, Cohere Re-ranking, and Query Expansion
query_engine = QueryEngine(
qa_prompt=PROMPT,
bm25=bm25,
multi_modal_llm=MM_LLM,
vector_index=index,
node_postprocessors=[],
llm=llm,
text_node_with_context=text_node_with_context
)
print("All done")
An advantage of using OpenAI models, especially gpt-4o-mini, is much lower cost for context assignment and query inference running, as well as much smaller context assignment time. While the basic tiers of both OpenAI and Anthropic do quickly hit the maximum rate limit of API calls, retry time in Anthropic’s basic tier vary and could be too long. Context assignment process for only first 20 pages of this document with claude-3–5-sonnet-20240620 took approximately 170 seconds with prompt caching and costed 20 cents (input + output tokens). Whereas, gpt-4o-mini is roughly 20x cheaper compared to Claude 3.5 Sonnet for input tokens and roughly 25x cheaper for output tokens. OpenAI claims to implement prompt caching for repetitive content which works automatically for all API calls.
In comparison, the context assignment to nodes in this entire document (60 pages) through gpt-4o-mini completed in approximately 193 seconds without any retry request.
After implementing the QueryEngine class, we can run the query inference as follows:
original_query = """What are the top countries to whose citizens the Finnish Immigration Service issued the highest number of first residence permits in 2023?
Which of these countries received the highest number of first residence permits?"""
response = query_engine.query(original_query)
display(Markdown(str(response)))
Here is the markdown response to this query.

The pages cited in the query response are the following.

Now let’s compare the performance of gpt-4o-mini based RAG (LlamaParse premium + context retrieval + BM25 + re-ranking) with Claude based RAG (LlamaParse premium + context retrieval). I also implemented a simple, baseline RAG which can be found in GitHub’s notebook. Here are the three RAGs to be compared.
- Simple RAG in LlamaIndex using SentenceSplitter to split the documents into chunks (chunk_size = 800, chunk_overlap= 400), creating a vector index and vector retrieval.
- CMRAG (claude-3–5-sonnet-20240620, voyage-3) — LlamaParse premium mode + context retrieval
- CMRAG (gpt-4o-mini, text-embedding-3-small) — LlamaParse premium mode + context retrieval + BM25 + re-ranking
For the sake of simplicity, we refer to these RAGs as RAG0, RAG1, and RAG2, respectively. Here are three pages from the report from where I asked three questions (1 question from each page) to each RAG. The areas highlighted by the red rectangles show the ground truth or the place from where the right answer should come from.

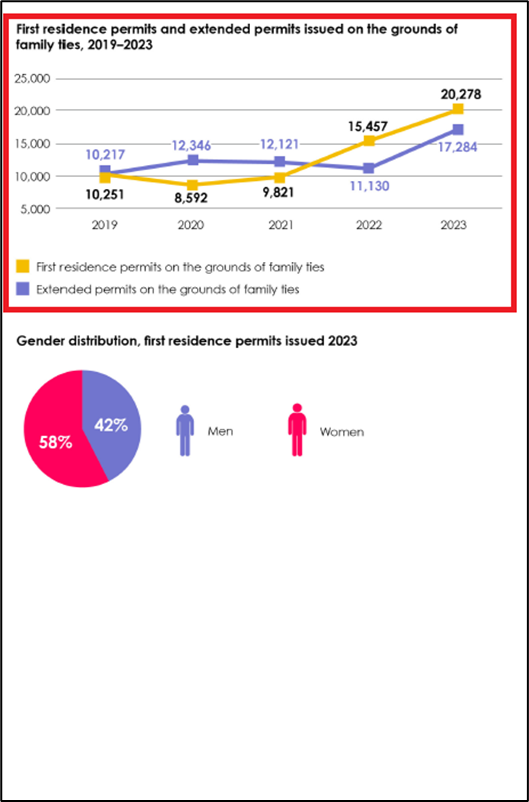

Here are the responses to the three RAGs to each question.
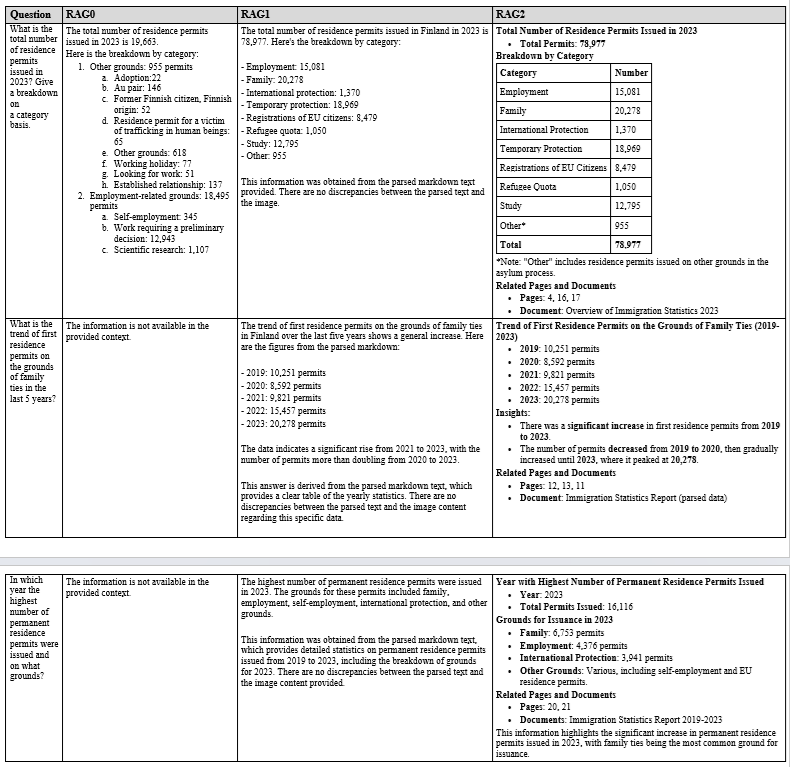
It can be seen that RAG2 performs very well. For the first question, RAG0 provides a wrong answer because the question was asked from an image. Both RAG1 and RAG2 provided the right answer to this question. For the other two questions, RAG0 could not provide any answer. Whereas, both RAG1 and RAG2, provided right answers to these questions.
Overall, RAG2’s performance was equal or even better than RAG1 in many cases due to the integration of BM25, re-ranking, and better prompting. It provides a cost-effective solution to a contextual, multimodal RAG. A possible integration in this pipeline could be hypothetical document embedding (hyde) or query extension. Similarly, open-source embedding models (such as all-MiniLM-L6-v2) and/or light-weight LLMs (such as gemma2 or phi-3-small) could also be explored to make it more cost effective.
If you like the article, please clap the article and follow me on Medium and/or LinkedIn
GitHub
For the full code reference, please take a look at my repo:
GitHub – umairalipathan1980/Multimodal-contextual-RAG: Multimodal contextual RAG
Integrating Multimodal Data into a Large Language Model was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
Originally appeared here:
Integrating Multimodal Data into a Large Language Model
Go Here to Read this Fast! Integrating Multimodal Data into a Large Language Model