How can we use clustering techniques to combine and refactor a large number of disparate dashboards?
Background
Organizations generate voluminous amounts of data on a daily basis. Dashboards are built to analyze this data and derive meaningful business insights as well as to track KPIs. Over time, we find ourselves with hundreds (or maybe more) of such dashboards. Oftentimes, this phenomenon of Dashboard Proliferation is driven by multiple groups developing their own analyses in silos without visibility into analytics that may already be available. For example, sales teams may create a dashboard to track their forecasts vs. actual sales not knowing that a forecast accuracy dashboard is currently available with the supply chain team. Not only does this result in duplication of efforts but we may end up with common metrics and analyses across multiple dashboards with no single source of truth due to differing data sources and assumptions.
As teams come together to provide updates on the state of the business to senior management, they usually spend several person-hours reconciling differing metrics to provide a clear and coherent message to leadership. Let’s say we have a 1000-person organization, where it takes an average of 2 hours per week spent by each person to reconcile data from different reports. This amounts to 100,000 person-hours annually assuming 50 weeks/yr. If we assume an average employee compensation at $50/hour, the yearly cost of this reconciliation runs up to $5MM. While the numbers above are hypothetical, they aren’t un-representative of operations and planning teams in large Fortune 100 companies. In this post, we will go over an approach to consolidate dashboards and reports to save time and effort in reconciling KPIs.
Bridging Reporting Differences within an Organization

Even metrics that ostensibly have the same definition may not match when reported by different teams in different reports. To bridge these differences, we may consider one of the following approaches to reconcile metrics and analyses across dashboards and reports:
(i) Tracking — this approach would entail keeping the dashboards as they are but creating a new directory to keep track of all dashboards. This directory will list metrics found in each dashboard along with their definitions, estimation assumptions, and input data sources.
(ii) Elimination — as the name suggests, we identify rarely used dashboards and work with their developers and users that have used the dashboards over the past 12 months. We may want to deprecate dashboards/reports after transferring relevant KPIs to other dashboards as needed.
(iii) Consolidation — here we would create a reduced number of dashboards by combining similar metrics into a single dashboard.
While we recommend elimination of sparsely utilized dashboards to the extent possible, we may still be left with many dashboards overlapping in metrics and purpose after this removal. This post will focus on an approach to merge together dashboards with similar content to yield a rationalized list. The proposed solution considers consolidation as a two-part problem. First, we identify which dashboards can be grouped together, following which we determine how to combine the dashboards within each cluster.
Considerations for Grouping Dashboards

A simple mental model is to group together similar dashboards. This similarity can be measured across multiple dimensions as noted below:
(a) Metrics — arguably the most important criterion. This includes all the entities exposed to the users from a given dashboard. For example, forecast accuracy, forecasts, and historical actuals may be key metrics in a demand planning dashboard. As metrics are a function of the purpose of a dashboard, grouping dashboards with similar metrics aligns the purpose of reporting as well.
(b) User Personas — the different roles within an organization that may use a dashboard on a regular basis. This is more of a secondary consideration when combining dashboards.
(c) Filters — the granularity at which the metrics, analyses and insights are available can be another consideration. As we combine dashboards, we need to ensure that the legacy granularities that support business decision-making are not lost.
(d) Input Data Sources — this may be a minor factor in deciding which dashboards to combine. All else remaining equal, it may be worthwhile grouping dashboards that derive data from the same sources for ease of integration.
All the afore-mentioned factors may not be equally significant. As such, we may need to give unequal weightage to each factor with potentially the highest to metrics and lowest to input data sources.
Dashboard Clustering

This is a critical step of the overall endeavor as it determines the effort needed to integrate the dashboards within a cluster into a single entity. The more disparate the dashboards within a cluster, the more time and effort needed to combine them into a single unit. We’ll walk through a case study, where we want to consolidate seven dashboards (shown in Figure. 1) into 2–3 groups.

A series of steps is recommended for the clustering:
1) Understand the purpose of each dashboard by talking with current users and developers. This voice of customer is crucial to capture at an early stage to facilitate adoption of the consolidated dashboards. We may also unearth new information about the dashboards and be able to update our initial assumptions and definitions.
2) Assign weights to the different dimensions — for instance, we may want to assign a higher weightage to metrics over the other factors. In our example above, we give metrics a 2x weightage vs. the others.
3) Convert the information into a dataframe conducive for applying clustering techniques. Figure 2 shows the dataframe for our case study accounting for the appropriate weights across dimensions.

4) Apply a standard clustering approach after removing the names of the dashboards. Figure 3 shows the dendrogram output from hierarchical clustering with Euclidean distance and Average linkage. If we overlay the dashed green line, it produces 3 clusters with the dashboards in our example {A, F}, {G, B, C, D}, {E}.
5) Iterate on number of clusters to arrive at a set of balanced clusters that make business sense.

A caveat here is that a given metric may be a part of different dashboards across multiple clusters. We can either document this occurrence to inform users or we could remove the metric based on business judgment from K-1 dashboards, where K is the total number of clusters where the metric appears. However, this type of judgment-based elimination can be sub-optimal.
One other challenge with a traditional clustering approach is that it may not group dashboards that are subsets of other dashboards in the same cluster. For example, Dashboard A is a subset of Dashboard E as can be seen in Figure 1 (i.e. metrics, user personas, filers and data sources in Dashboard A are also present in Dashboard E) but they are grouped in different clusters (Figure 3). The idea behind capturing subsets is to eliminate them since an alternate (superset) dashboard is available that also exposes the same metrics along with others to users. To mitigate this issue, we propose an alternate clustering algorithm to help group together subsets.
A New Algorithm to Merge Subsets

In this approach, we treat each dashboard as a list where each of the metrics, filters, user personas, and input data sources are categorical elements of the list. The idea is to create correlation indicators between the dashboards accounting for common elements and cluster together dashboards (or groups of dashboards), where the correlation exceeds a user-defined threshold. The steps in the algorithm are as follows:
- Separate the metrics, user personas, filters, and input data sources for each dashboard as we may need to assign different weights to each of these dimensions. The set Dimension = {metrics, user personas, filters, input data sources}, while dim ∈ Dimension is used to index each element of this set.
- Select a pair of dashboards and label one of them D1 and the other D2.
- Count the number of elements within each dimension across the two dashboards: N(dim, D1) and N(dim, D2).
- Count the number of common elements within each dimension between D1 and D2 represented by cm(dim, D1, D2).
- Estimate two correlation indicators: Corr1(dim, D1, D2) = cm(dim, D1, D2)/N(dim, D1) and Corr2(dim, D1, D2) = cm(dim, D1, D2)/N(dim, D2). If one of D1 or D2 is a subset of the other, Corr1 or Corr2 will equal 1.0.
- Calculate overall correlation factors using user-assigned weights for each dimension: Total_Corr1(D1, D2) = sum{dim, weight(dim)*Corr1(dim, D1, D2)} and Total_Corr2(D1, D2) = sum{dim, weight(dim)*Corr2(dim, D1, D2)}.
- Get the maximum and minimum value between Total_Corr1 and Total_Corr2: Max_Corr(D1, D2) = maximum{Total_Corr1(D1, D2), Total_Corr2(D1, D2)} and Min_Corr(D1, D2) = minimum{ Total_Corr1(D1, D2), Total_Corr2(D1, D2)}.
- Repeat steps 2–7 for all possible combinations of D1 and D2, where D1 and D2 are not the same dashboard.
- Add Max_Corr and Min_Corr values to two separate lists.
- Sort the list with Max_Corr values in descending order. If multiple dashboard pairs have the same Max_Corr values, then the pair with the lower Min_Corr value takes precedence. This approach is an approximation to ensure dashboards with potentially larger number of elements are prioritized.
- Select a threshold for Max_Corr above which dashboards can be combined.
- As we move through each pair D1 and D2 in the list of Max_Corr values in descending order, we may encounter four scenarios: (i) D1 and D2 are currently part of the same cluster: no action needed, (ii) D1 and D2 are currently not part of any cluster: if Max_Corr(D1, D2) >= Threshold, D1 and D2 should be clustered together, (iii) D1 is part of a cluster but D2 is not: combine the elements across all dimensions of all dashboards in the cluster with D1 to create a hypothetical single dashboard. Estimate value of Max_Corr between D2 and the newly created larger dashboard. If it is higher than the threshold, add D2 to the cluster with D1, (iv) D1 and D2 are both part of separate clusters: create two hypothetical dashboards by collating the elements in the dashboards within each cluster. Establish Max_Corr between the two new dashboards and check against the threshold. If Max_Corr >= Threshold, merge the two existing clusters that subsume D1 and D2.
- Repeat Step 12 until we fully traverse through the entire list of Max_Corr values.
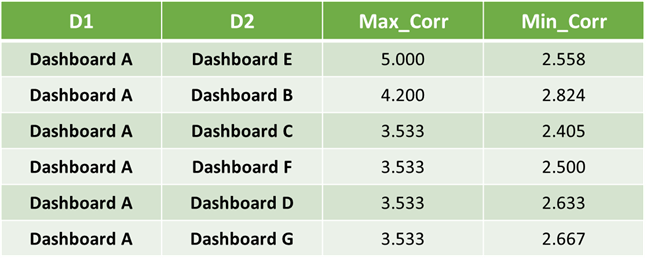
We apply Steps 2–10 to our earlier example to estimate the correlations (Figure 4) between Dashboard A and all other dashboards to test if the approach works as intended. We see that the highest value of Max_Corr is between Dashboard A and Dashboard E along expected lines as Dashboard A is a subset of Dashboard E across all dimensions.
This new algorithm will yield a set of clusters with similar dashboards across the dimensions outlined in the earlier sections. The choice of threshold determines the number of clusters and count of dashboards within each. We may want to test multiple thresholds iteratively until we find the clusters to be closely aligned to business expectations. In general, this approach works well for clustering entities in any categorical dataframe.
Consolidation within a Cluster

Once we have a set of acceptable clusters, we need to combine each collection into a single dashboard. We typically rely on guidance from software engineering teams on the merging of dashboards. One option may be to create a new dashboard to capture all metrics and filters within a cluster. If starting from scratch is not the recommended solution, we need to pick one dashboard from each cluster and add information to it from other dashboards in the cluster. To minimize re-work, we would want to sort the dashboards in order of increasing complexity and use the most complex one as the base. We would add data from the other dashboards to this base starting with the next most complex dashboard, while avoiding duplication of information as we go through the dashboards in the cluster. Ordering is important to avoid inefficiencies in the process of combining dashboards. Complexity is best defined by the software development engineers — this can be lines of code, number of functions, or any other criteria. If complexity is around the same across all dashboards, then we may want to consider the following hierarchy to sort:
Number of metrics >> Number of filters/views >> Number of input data sources >> Number of users
For instance, if the complexity is around the same across dashboards, we would use the dashboard with most metrics as our base and add metrics from other dashboards to it.
To Summarize…

Unstructured growth of data is a common challenge that is not limited to a single industry, organization or business line. Teams spend countless hours trying to reconcile data from different sources. Even seemingly similar metrics may have been built for different purposes with different assumptions. These situations are not uncommon because dashboard and report creation are typically decentralized where any employee can use an organization’s data to build their own views. Combining dashboards with similar metrics can help alleviate the time and effort spent in data reconciliation by 1) reducing the number of entities to consider while bridging, and 2) driving towards a single source of truth for many metrics.
Traditional clustering algorithms can help decide which dashboards should go together, but we may need to consider custom approaches as described in this post to group together subsets of dashboards. Eventually, the solution to this issue of data reconciliation is to develop a mechanism to create reports in a centralized fashion. If that isn’t organizationally feasible, an advanced solution to this problem of manual reconciliation would be to use a Generative AI framework to sift through multiple reports and dashboards within an organization’s repository and provide the bridges between metrics highlighting key drivers behind the differences.
Thanks for reading. Hope you found it useful. Feel free to send me your comments at [email protected]. Let’s connect on LinkedIn
Information Rationalization in Large Organizations was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
Originally appeared here:
Information Rationalization in Large Organizations
Go Here to Read this Fast! Information Rationalization in Large Organizations