How paying “better” attention can drive ML cost savings

Introduced in the landmark 2017 paper “Attention Is All You Need” (Vaswani et al., 2017), the Transformer architecture is widely regarded as one of the most influential scientific breakthroughs of the past decade. At the core of the Transformer is the attention mechanism, a novel approach that enables AI models to comprehend complex structures by focusing on different parts of input sequences based on the task at hand. Originally demonstrated in the world of natural language processing, the success of the Transformers architecture has quickly spread to many other domains, including speech recognition, scene understanding, reinforcement learning, protein structure prediction, and more. However, attention layers are highly resource-intensive, and as these layers become the standard across increasingly large models, the costs associated with their training and deployment have surged. This has created an urgent need for strategies that reduce the computational cost of this core layer so as to increase the efficiency and scalability of Transformer-based AI models.
In this post, we will explore several tools for optimizing attention in PyTorch. Our focus will be on methods that maintain the accuracy of the attention layer. These will include PyTorch SDPA, FlashAttention, TransformerEngine Attention, FlexAttention, and xFormer attention. Other methods that reduce the computational cost via approximation of the attention calculation (e.g., DeepSpeed’s Sparse Attention, Longformer, Linformer, and more) will not be considered. Additionally, we will not discuss general optimization techniques that, while beneficial to attention performance, are not specific to the attention computation itself (e.g., FP8 training, model sharding, and more).
Importantly, attention optimization is an active area of research with new methods coming out on a pretty regular basis. Our goal is to increase your awareness of some of the existing solutions and provide you with a foundation for further exploration and experimentation. The code we will share below is intended for demonstrative purposes only — we make no claims regarding its accuracy, optimality, or robustness. Please do not interpret our mention of any platforms, libraries, or optimization techniques as an endorsement for their use. The best options for you will depend greatly on the specifics of your own use-case.
Many thanks to Yitzhak Levi for his contributions to this post.
Toy Model
To facilitate our discussion, we build a Vision Transformer (ViT)-backed classification model using the popular timm Python package (version 0.9.7). We will use this model to illustrate the performance impact of various attention kernels.
We start by defining a simplified Transformer block that allows for programming the attention function by passing it into its constructor. Since attention implementations assume specific input tensor formats, we also include an option for controlling the format, ensuring compatibility with the attention kernel of our choosing.
# general imports
import os, time, functools
# torch imports
import torch
from torch.utils.data import Dataset, DataLoader
import torch.nn as nn
# timm imports
from timm.models.vision_transformer import VisionTransformer
from timm.layers import Mlp
IMG_SIZE = 224
BATCH_SIZE = 128
# Define ViT settings
NUM_HEADS = 16
HEAD_DIM = 64
DEPTH = 24
PATCH_SIZE = 16
SEQ_LEN = (IMG_SIZE // PATCH_SIZE)**2 # 196
class MyAttentionBlock(nn.Module):
def __init__(
self,
attn_fn,
format = None,
dim: int = 768,
num_heads: int = 12,
**kwargs
) -> None:
super().__init__()
self.attn_fn = attn_fn
self.num_heads = num_heads
self.head_dim = dim // num_heads
self.norm1 = nn.LayerNorm(dim)
self.norm2 = nn.LayerNorm(dim)
self.qkv = nn.Linear(dim, dim * 3, bias=False)
self.proj = nn.Linear(dim, dim)
self.mlp = Mlp(
in_features=dim,
hidden_features=dim * 4,
)
permute = (2, 0, 3, 1, 4)
self.permute_attn = functools.partial(torch.transpose,dim0=1,dim1=2)
if format == 'bshd':
permute = (2, 0, 1, 3, 4)
self.permute_attn = nn.Identity()
self.permute_qkv = functools.partial(torch.permute,dims=permute)
def forward(self, x_in: torch.Tensor) -> torch.Tensor:
x = self.norm1(x_in)
B, N, C = x.shape
qkv = self.qkv(x).reshape(B, N, 3, self.num_heads, self.head_dim)
# permute tensor based on the specified format
qkv = self.permute_qkv(qkv)
q, k, v = qkv.unbind(0)
# use the attention function specified by the user
x = self.attn_fn(q, k, v)
# permute output according to the specified format
x = self.permute_attn(x).reshape(B, N, C)
x = self.proj(x)
x = x + x_in
x = x + self.mlp(self.norm2(x))
return x
We define a randomly generated dataset which we will use to feed to our model during training.
# Use random data
class FakeDataset(Dataset):
def __len__(self):
return 1000000
def __getitem__(self, index):
rand_image = torch.randn([3, IMG_SIZE, IMG_SIZE],
dtype=torch.float32)
label = torch.tensor(data=index % 1000, dtype=torch.int64)
return rand_image, label
Next, we define our ViT training function. While our example focuses on demonstrating a training workload, it is crucial to emphasize that optimizing the attention layer is equally, if not more, important during model inference.
The training function we define accepts the customized Transformer block and a flag that controls the use of torch.compile.
def train_fn(block_fn, compile):
torch.random.manual_seed(0)
device = torch.device("cuda:0")
torch.set_float32_matmul_precision("high")
# Create dataset and dataloader
train_set = FakeDataset()
train_loader = DataLoader(
train_set, batch_size=BATCH_SIZE,
num_workers=12, pin_memory=True, drop_last=True)
model = VisionTransformer(
img_size=IMG_SIZE,
patch_size=PATCH_SIZE,
embed_dim=NUM_HEADS*HEAD_DIM,
depth=DEPTH,
num_heads=NUM_HEADS,
class_token=False,
global_pool="avg",
block_fn=block_fn
).to(device)
if compile:
model = torch.compile(model)
# Define loss and optimizer
criterion = torch.nn.CrossEntropyLoss()
optimizer = torch.optim.SGD(model.parameters())
model.train()
t0 = time.perf_counter()
summ = 0
count = 0
for step, data in enumerate(train_loader):
# Copy data to GPU
inputs = data[0].to(device=device, non_blocking=True)
label = data[1].to(device=device, non_blocking=True)
with torch.amp.autocast('cuda', enabled=True, dtype=torch.bfloat16):
outputs = model(inputs)
loss = criterion(outputs, label)
optimizer.zero_grad(set_to_none=True)
loss.backward()
optimizer.step()
# Capture step time
batch_time = time.perf_counter() - t0
if step > 20: # Skip first steps
summ += batch_time
count += 1
t0 = time.perf_counter()
if step > 100:
break
print(f'average step time: {summ / count}')
# define compiled and uncompiled variants of our train function
train = functools.partial(train_fn, compile=False)
train_compile = functools.partial(train_fn, compile=True)
In the code block below we define a PyTorch-native attention function and use it to train our ViT model:
def attn_fn(q, k, v):
scale = HEAD_DIM ** -0.5
q = q * scale
attn = q @ k.transpose(-2, -1)
attn = attn.softmax(dim=-1)
x = attn @ v
return x
block_fn = functools.partial(MyAttentionBlock, attn_fn=attn_fn)
print('Default Attention')
train(block_fn)
print('Compiled Default Attention')
train_compile(block_fn)
We ran this on an NVIDIA H100 with CUDA 12.4 and PyTorch 2.5.1. The uncompiled variant resulted in an average step time of 370 milliseconds (ms), while the compiled variant improved to 242 ms. We will use these results as a baseline for comparison as we consider alternative solutions for performing the attention computation.
PyTorch SDPA
One of the easiest ways to boost the performance of our attention layers in PyTorch is to use the scaled_dot_product_attention (SDPA) function. Currently in beta, PyTorch SDPA consolidates multiple kernel-level optimizations and dynamically selects the most efficient one based on the input’s properties. Supported backends (as of now) include: FlashAttention-2, Memory-Efficient Attention, a C++-based Math Attention, and CuDNN. These backends fuse together high-level operations while employing GPU-level optimizations for increasing compute efficiency and memory utilization.
SDPA is continuously evolving, with new and improved backend implementations being introduced regularly. Staying up to date with the latest PyTorch releases is key to leveraging the most recent performance improvements. For example, PyTorch 2.5 introduced an updated CuDNN backend featuring a specialized SDPA primitive specifically tailored for training on NVIDIA Hopper architecture GPUs.
In the code block below, we iterate through the list of supported backends and assess the runtime performance of training with each one. We use a helper function, set_sdpa_backend, for programming the SDPA backend:
from torch.nn.functional import scaled_dot_product_attention as sdpa
def set_sdpa_backend(backend):
torch.backends.cuda.enable_flash_sdp(False)
torch.backends.cuda.enable_mem_efficient_sdp(False)
torch.backends.cuda.enable_math_sdp(False)
torch.backends.cuda.enable_cudnn_sdp(False)
if backend in ['flash_sdp','all']:
torch.backends.cuda.enable_flash_sdp(True)
if backend in ['mem_efficient_sdp','all']:
torch.backends.cuda.enable_mem_efficient_sdp(True)
if backend in ['math_sdp','all']:
torch.backends.cuda.enable_math_sdp(True)
if backend in ['cudnn_sdp','all']:
torch.backends.cuda.enable_cudnn_sdp(True)
for backend in ['flash_sdp', 'mem_efficient_sdp',
'math_sdp', 'cudnn_sdp']:
set_sdpa_backend(backend)
block_fn = functools.partial(MyAttentionBlock,
attn_fn=sdpa)
print(f'PyTorch SDPA - {backend}')
train(block_fn)
print(f'Compiled PyTorch SDPA - {backend}')
train_compile(block_fn)
We summarize our interim results in the table below
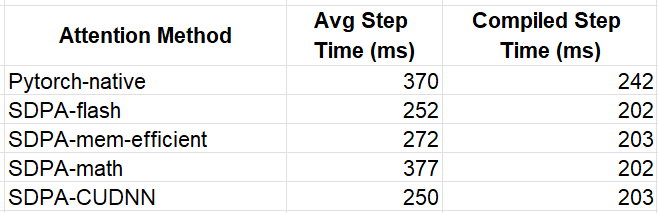
While the choice of SDPA backend has a noticeable impact on performance when running in eager mode, the optimizations performed by model compilation appear to overshadow the differences between the attention kernels. Once again, we caution against deriving any conclusions from these results as the performance impact of different attention functions can vary significantly depending on the specific model and use case.
Third-Party Attention Kernels
While PyTorch SDPA is a great place to start, using third-party attention kernels can help accelerate your ML workloads further. These alternatives often come with added flexibility, offering a wider range of configuration options for attention. Some may also include optimizations tailored for specific hardware accelerators or newer GPU architectures.
In this section, we will explore some of the third-party attention kernels available and evaluate their potential impact on runtime performance.
FlashAttention-3
While Pytorch SDPA supports a FlashAttention backend, more advanced FlashAttention implementations can be found in the flash-attn library. Here we will explore the FlashAttention-3 beta release which boasts a speed of up to 2x compared to FlashAttention-2. Given the early stage in its development, FlashAttention-3 can only be installed directly from the GitHub repository and its use is limited to certain head dimensions. Additionally, it does not yet support model compilation. In the following code block, we configure our transformer block to use flash-attn-3 while setting the attention input format to “bshd” (batch, sequence, head, depth) to meet the expectations of the library.
# flash attention 3
from flash_attn_interface import flash_attn_func as fa3
attn_fn = lambda q,k,v: fa3(q,k,v)[0]
block_fn = functools.partial(MyAttentionBlock,
attn_fn=attn_fn,
format='bshd')
print(f'Flash Attention 3')
train(block_fn)
The resultant step time was 240 ms, making it 5% faster than the SDPA flash-attn.
Transformer Engine
Transformer Engine (TE) is a specialized library designed to accelerate Transformer models on NVIDIA GPUs. TE is updated regularly with optimizations that leverage the capabilities of the latest NVIDIA hardware and software offerings, giving users access to specialized kernels long before they are integrated into general-purpose frameworks such as PyTorch.
In the code block below we use DotProductAttention from TE version 1.11.0. Similar to PyTorch SDPA, TE supports a number of backends which are controlled via environment variables. Here we demonstrate the use of the NVTE_FUSED_ATTN backend.
def set_te_backend(backend):
# must be applied before first use of
# transformer_engine.pytorch.attention
os.environ["NVTE_FLASH_ATTN"] = '0'
os.environ["NVTE_FUSED_ATTN"] = '0'
os.environ["NVTE_UNFUSED_ATTN"] = '0'
if backend == 'flash':
os.environ["NVTE_FLASH_ATTN"] = '1'
if backend == 'fused':
os.environ["NVTE_FUSED_ATTN"] = '1'
if backend == 'unfused':
os.environ["NVTE_UNFUSED_ATTN"] = '1'
from transformer_engine.pytorch.attention import DotProductAttention
set_te_backend('fused')
attn_fn = DotProductAttention(NUM_HEADS, HEAD_DIM, NUM_HEADS,
qkv_format='bshd',
# disable masking (default is causal mask)
attn_mask_type='no_mask')
block_fn = functools.partial(MyAttentionBlock,
attn_fn=attn_fn,
format='bshd')
print(f'Transformer Engine Attention')
train(block_fn)
print(f'Compiled Transformer Engine Attention')
train_compile(block_fn)
TE attention resulted in average step times of 243 ms and 204 ms for the eager and compiled model variants, correspondingly.
XFormer Attention
Underlying the memory-efficient backend of PyTorch SDPA is an attention kernel provided by the xFormers library. Once again, we can go to the source to benefit from the latest kernel optimizations and from the full set of API capabilities. In the following code block we use the memory_efficient_attention operator from xFormers version 0.0.28.
# xformer memory efficient attention
from xformers.ops import memory_efficient_attention as mea
block_fn = functools.partial(MyAttentionBlock,
attn_fn=mea,
format='bshd')
print(f'xFormer Attention ')
train(block_fn)
print(f'Compiled xFormer Attention ')
train_compile(block_fn)
This eager model variant resulted in an average step time of 246 ms, making it 10.5% faster than the SDPA memory efficient kernel. The compiled variant resulted in a step time of 203 ms.
Results
The table below summarizes our experiments:
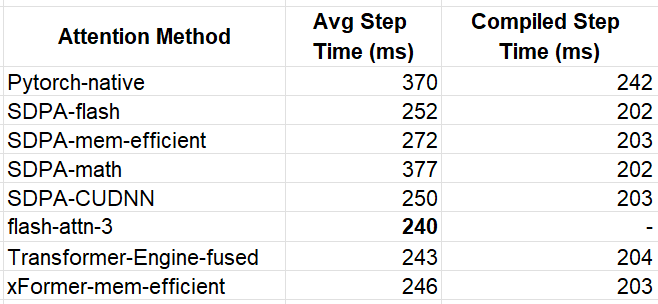
The winner for the eager model was flash-attn-3 with an average step time that is 54% faster than our baseline model. This translates to a similar 54% reduction in training costs. In compiled mode, the performance across the optimized kernels was more or less equal, with the fastest implementations achieving 202 ms, representing a 20% improvement compared to the baseline experiment.
As mentioned above, the precise impact savings is greatly dependent on the model definition. To assess this variability, we reran the experiments using modified settings that increased the attention sequence length to 3136 tokens.
IMG_SIZE = 224
BATCH_SIZE = 8
# Define ViT settings
NUM_HEADS = 12
HEAD_DIM = 64
DEPTH = 6
PATCH_SIZE = 4
SEQ_LEN = (IMG_SIZE // PATCH_SIZE)**2 # 3136
The results are summarized in the table below:
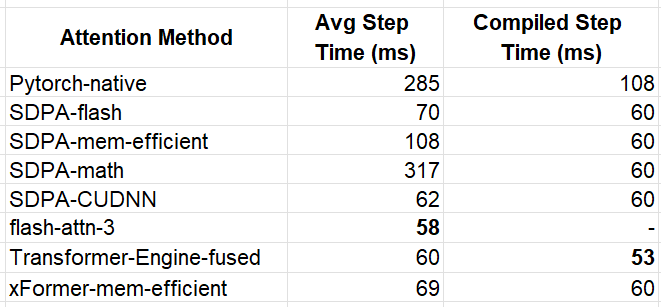
Our immediate observation is that when the sequence length is greater the performance impact of the attention kernels is far more pronounced. Once again, flash-attn-3 came out in front for the eager execution mode — this time with a ~5x increase in performance compared to the PyTorch-native function. For the compiled model we see that the TE kernel broke away from the pack with an overall best step-time of 53 ms.
Customizing Attention with FlexAttention
Thus far, we’ve focused on the standard attention function. However, sometimes we may want to use a variant of the typical attention computation in which we either mask out some of the values of intermediate tensors or apply some operation on them. These types of changes may interfere with our ability to use the optimized attention blocks we covered above. In this section we discuss some of the ways to address this:
Leverage Advanced Kernel APIs
Many optimized attention kernels provide extensive APIs with controls for customizing the attention computation. Before implementing a new solution, explore these APIs to determine if they already support your required functionality.
Implement a custom kernel:
If the existing APIs do not meet your needs, you could consider creating your own custom attention implementation. In previous posts (e.g., here) we discussed some of the pros and cons of custom kernel development. Achieving optimal performance can be extremely difficult. If you do go down this path, one approach might be to start with an existing (optimal) kernel and apply minimal changes to integrate the desired change.
Use FlexAttention:
A recent addition to PyTorch, FlexAttention empowers users to implement a wide variety of attention variants without needing to compromise on performance. Denoting the result of the dot product of the query and key tokens by score, flex_attention allows for programming either a score_mod function or a block_mask mask that is automatically applied to the score tensor. See the documentation as well as the accompanying attention-gym repository for examples of the types of operations that the API enables.
FlexAttention works by compiling the score_mod operator into the attention operator, thereby creating a single fused kernel. It also leverages the sparsity of block_masks to avoid unnecessary computations. The benchmarks reported in the FlexAttention documentation show considerable performance gains for a variety of use cases.
Let’s see both the score_mod and block_mask in action.
Score Mod Example — Soft-Capping with Tanh
Soft-capping is a common technique used to control the logit sizes (e.g., see here). The following code block extends our PyTorch-native attention kernel with soft-capping:
def softcap_attn(q, k, v):
scale = HEAD_DIM ** -0.5
q = q * scale
attn = q @ k.transpose(-2, -1)
# apply soft-capping
attn = 30 * torch.tanh(attn/30)
attn = attn.softmax(dim=-1)
x = attn @ v
return x
In the code block below we train our model, first with our PyTorch-native kernel, and then with the optimized Flex Attention API. These experiments were run with the 3136-length sequence settings.
# flex attention imports
from torch.nn.attention.flex_attention import (
create_block_mask,
create_mask,
flex_attention
)
compiled_flex = torch.compile(flex_attention)
# score_mod definition
def tanh_softcap(score, b, h, q_idx, kv_idx):
return 30 * torch.tanh(score/30)
block_fn = functools.partial(MyAttentionBlock, attn_fn=softcap_attn)
print(f'Attention with Softcap')
train(block_fn)
print(f'Compiled Attention with Softcap')
train_compile(block_fn)
flex_fn = functools.partial(flex_attention, score_mod=tanh_softcap)
compiled_flex_fn = functools.partial(compiled_flex, score_mod=tanh_softcap)
block_fn = functools.partial(MyAttentionBlock,
attn_fn=flex_fn)
compiled_block_fn = functools.partial(MyAttentionBlock,
attn_fn=compiled_flex_fn)
print(f'Flex Attention with Softcap')
train(compiled_block_fn)
print(f'Compiled Flex Attention with Softcap')
train_compile(block_fn)
The results of the experiments are captured in the table below:

The impact of the Flash Attention kernel is clearly evident, delivering performance boosts of approximately 3.5x in eager mode and 1.5x in compiled mode.
Mask Mod Example — Neighborhood Masking
We assess the mask_mod functionality by applying a sparse mask to our attention score. Recall that each token in our sequence represents a patch in our 2D input image. We modify our kernel so that each token only attends to other tokens that our within a 5×5 window in the corresponding 2-D token array.
# convert the token id to a 2d index
def seq_indx_to_2d(idx):
n_row_patches = IMG_SIZE // PATCH_SIZE
r_ind = idx // n_row_patches
c_ind = idx % n_row_patches
return r_ind, c_ind
# only attend to tokens in a 5x5 surrounding window in our 2D token array
def mask_mod(b, h, q_idx, kv_idx):
q_r, q_c = seq_indx_to_2d(q_idx)
kv_r, kv_c = seq_indx_to_2d(kv_idx)
return torch.logical_and(torch.abs(q_r-kv_r)<5, torch.abs(q_c-kv_c)<5)
As a baseline for our experiment, we use PyTorch SDPA which includes support for passing in an attention mask. The following block includes the masked SDPA experiment followed by the Flex Attention implementation:
# materialize the mask to use in SDPA
mask = create_mask(mask_mod, 1, 1, SEQ_LEN, SEQ_LEN, device='cuda')
set_sdpa_backend('all')
masked_sdpa = functools.partial(sdpa, attn_mask=mask)
block_fn = functools.partial(MyAttentionBlock,
attn_fn=masked_sdpa)
print(f'Masked SDPA Attention')
train(block_fn)
print(f'Compiled Masked SDPA Attention')
train_compile(block_fn)
block_mask = create_block_mask(mask_mod, None, None, SEQ_LEN, SEQ_LEN)
flex_fn = functools.partial(flex_attention, block_mask=block_mask)
compiled_flex_fn = functools.partial(compiled_flex, block_mask=block_mask)
block_fn = functools.partial(MyAttentionBlock,
attn_fn=flex_fn)
compiled_block_fn = functools.partial(MyAttentionBlock,
attn_fn=compiled_flex_fn)
print(f'Masked Flex Attention')
train(compiled_block_fn)
print(f'Compiled Masked Flex Attention')
train_compile(block_fn)
The results of the experiments are captured below:

Once again, Flex Attention offers a considerable performance boost, amounting to 2.19x in eager mode and 2.59x in compiled mode.
Flex Attention Limitations
Although we have succeeded in demonstrating the power and potential of Flex Attention, there are a few limitations that should be noted:
- Limited Scope of Modifications: With Flex Attention you can (as of the time of this writing) only modify the attention score (the result of the dot product between the query and key tokens). It does not support changes at other stages of the attention computation.
- Dependency on torcch.compile: Given the reliance on torch.compile, great care must be taken to avoid excessive recompilations which could greatly degrade runtime performance. For instance, while the support for Document Masking very compelling, it will only perform as expected if the sum of the lengths of all of the documents remains fixed.
- No Support for Trainable Parameters in score_mod: At the time of this writing, Flex Attention does not support a score_mod implementation that includes trainable parameters. For example, while the documentation highlights support for relative position encodings, these are commonly implemented with trainable parameters (rather than fixed values) which cannot currently be accommodated.
In the face of these limitations, we can return to one of the other optimization opportunities discussed above.
Summary
As the reliance on transformer architectures and attention layers in ML models increases, so does the need for tools and techniques for optimizing these components. In this post, we have explored a number of attention kernel variants, each with its own unique properties, capabilities, and limitations. Importantly, one size does not fit all — different models and use cases will warrant the use of different kernels and different optimization strategies. This underscores the importance of having a wide variety tools and techniques for optimizing attention layers.
In a future post, we hope to further explore attention layer optimization by focusing on applying some of the tools we discussed to tackle the challenge of handling variable-sized input sequences. Stay tuned…
Increasing Transformer Model Efficiency Through Attention Layer Optimization was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
Originally appeared here:
Increasing Transformer Model Efficiency Through Attention Layer Optimization