

The class neighborhood of a dataset can be learned using soft nearest neighbor loss
In this article, we discuss how to implement the soft nearest neighbor loss which we also talked about here.
Representation learning is the task of learning the most salient features in a given dataset by a deep neural network. It is usually an implicit task done in a supervised learning paradigm, and it is a crucial factor in the success of deep learning (Krizhevsky et al., 2012; He et al., 2016; Simonyan et al., 2014). In other words, representation learning automates the process of feature extraction. With this, we can use the learned representations for downstream tasks such as classification, regression, and synthesis.
We can also influence how the learned representations are formed to cater specific use cases. In the case of classification, the representations are primed to have data points from the same class to flock together, while for generation (e.g. in GANs), the representations are primed to have points of real data flock with the synthesized ones.
In the same sense, we have enjoyed the use of principal components analysis (PCA) to encode features for downstream tasks. However, we do not have any class or label information in PCA-encoded representations, hence the performance on downstream tasks may be further improved. We can improve the encoded representations by approximating the class or label information in it by learning the neighborhood structure of the dataset, i.e. which features are clustered together, and such clusters would imply that the features belong to the same class as per the clustering assumption in the semi-supervised learning literature (Chapelle et al., 2009).
To integrate the neighborhood structure in the representations, manifold learning techniques have been introduced such as locally linear embeddings or LLE (Roweis & Saul, 2000), neighborhood components analysis or NCA (Hinton et al., 2004), and t-stochastic neighbor embedding or t-SNE (Maaten & Hinton, 2008).
However, the aforementioned manifold learning techniques have their own drawbacks. For instance, both LLE and NCA encode linear embeddings instead of nonlinear embeddings. Meanwhile, t-SNE embeddings result to different structures depending on the hyperparameters used.
To avoid such drawbacks, we can use an improved NCA algorithm which is the soft nearest neighbor loss or SNNL (Salakhutdinov & Hinton, 2007; Frosst et al., 2019). The SNNL improves the NCA algorithm by introducing nonlinearity, and it is computed for each hidden layer of a neural network instead of solely on the last encoding layer. This loss function is used to optimize the entanglement of points in a dataset.
In this context, entanglement is defined as how close class-similar data points to each other are compared to class-different data points. A low entanglement means that class-similar data points are much closer to each other than class-different data points (see Figure 1). Having such a set of data points will render downstream tasks much easier to accomplish with an even better performance. Frosst et al. (2019) expanded the SNNL objective by introducing a temperature factor T. Thus giving us the following as the final loss function,

where d is a distance metric on either raw input features or hidden layer representations of a neural network, and T is the temperature factor that is directly proportional to the distances among data points in a hidden layer. For this implementation, we use the cosine distance as our distance metric for more stable computations.
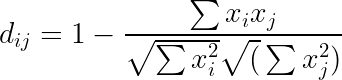
The purpose of this article is to help readers understand and implement the soft nearest neighbor loss, and so we shall dissect the loss function in order to understand it better.
Distance Metric
The first thing we should compute are the distances among data points, that are either the raw input features or hidden layer representations of the network.

For our implementation, we use the cosine distance metric (Figure 3) for more stable computations. At the time being, let us ignore the denoted subsets ij and ik in the figure above, and let us just focus on computing the cosine distance among our input data points. We accomplish this through the following PyTorch code:
normalized_a = torch.nn.functional.normalize(features, dim=1, p=2)
normalized_b = torch.nn.functional.normalize(features, dim=1, p=2)
normalized_b = torch.conj(normalized_b).T
product = torch.matmul(normalized_a, normalized_b)
distance_matrix = torch.sub(torch.tensor(1.0), product)
In the code snippet above, we first normalize the input features in lines 1 and 2 using Euclidean norm. Then in line 3, we get the conjugate transpose of the second set of the normalized input features. We compute the conjugate transpose to account for complex vectors. In lines 4 and 5, we compute the cosine similarity and distance of the input features.
Concretely, consider the following set of features,
tensor([[ 1.0999, -0.9438, 0.7996, -0.4247],
[ 1.2150, -0.2953, 0.0417, -1.2913],
[ 1.3218, 0.4214, -0.1541, 0.0961],
[-0.7253, 1.1685, -0.1070, 1.3683]])
Using the distance metric we defined above, we gain the following distance matrix,
tensor([[ 0.0000e+00, 2.8502e-01, 6.2687e-01, 1.7732e+00],
[ 2.8502e-01, 0.0000e+00, 4.6293e-01, 1.8581e+00],
[ 6.2687e-01, 4.6293e-01, -1.1921e-07, 1.1171e+00],
[ 1.7732e+00, 1.8581e+00, 1.1171e+00, -1.1921e-07]])
Sampling Probability
We can now compute the matrix that represents the probability of picking each feature given its pairwise distances to all other features. This is simply the probability of picking i points based on the distances between i and j or k points.

We can compute this through the following code:
pairwise_distance_matrix = torch.exp(
-(distance_matrix / temperature)
) - torch.eye(features.shape[0]).to(model.device)
The code first calculates the exponential of the negative of the distance matrix divided by the temperature factor, scaling the values to positive values. The temperature factor dictates how to control the importance given to the distances between pairs of points, for instance, at low temperatures, the loss is dominated by small distances while actual distances between widely separated representations become less relevant.
Prior to the subtraction of torch.eye(features.shape[0]) (aka diagonal matrix), the tensor was as follows,
tensor([[1.0000, 0.7520, 0.5343, 0.1698],
[0.7520, 1.0000, 0.6294, 0.1560],
[0.5343, 0.6294, 1.0000, 0.3272],
[0.1698, 0.1560, 0.3272, 1.0000]])
We subtract a diagonal matrix from the distance matrix to remove all self-similarity terms (i.e. the distance or similarity of each point to itself).
Next, we can compute the sampling probability for each pair of data points through the following code:
pick_probability = pairwise_distance_matrix / (
torch.sum(pairwise_distance_matrix, 1).view(-1, 1)
+ stability_epsilon
)
Masked Sampling Probability
So far, the sampling probability we have computed does not contain any label information. We integrate the label information into the sampling probability by masking it with the dataset labels.
First, we have to derive a pairwise matrix out of the label vectors:
masking_matrix = torch.squeeze(
torch.eq(labels, labels.unsqueeze(1)).float()
)
We apply the masking matrix to use the label information to isolate the probabilities for points that belong to the same class:
masked_pick_probability = pick_probability * masking_matrix
Next, we compute the sum probability for sampling a particular feature by computing the sum of the masked sampling probability per row,
summed_masked_pick_probability = torch.sum(masked_pick_probability, dim=1)
Finally, we can compute the logarithm of the sum of the sampling probabilities for features for computational convenience with an additional computational stability variable, and get the average to act as the nearest neighbor loss for the network,
snnl = torch.mean(
-torch.log(summed_masked_pick_probability + stability_epsilon
)
We can now string these components together in a forward pass function to compute the soft nearest neighbor loss across all layers of a deep neural network,
def forward(
self,
model: torch.nn.Module,
features: torch.Tensor,
labels: torch.Tensor,
outputs: torch.Tensor,
epoch: int,
) -> Tuple:
if self.use_annealing:
self.temperature = 1.0 / ((1.0 + epoch) ** 0.55)
primary_loss = self.primary_criterion(
outputs, features if self.unsupervised else labels
)
activations = self.compute_activations(model=model, features=features)
layers_snnl = []
for key, value in activations.items():
value = value[:, : self.code_units]
distance_matrix = self.pairwise_cosine_distance(features=value)
pairwise_distance_matrix = self.normalize_distance_matrix(
features=value, distance_matrix=distance_matrix
)
pick_probability = self.compute_sampling_probability(
pairwise_distance_matrix
)
summed_masked_pick_probability = self.mask_sampling_probability(
labels, pick_probability
)
snnl = torch.mean(
-torch.log(self.stability_epsilon + summed_masked_pick_probability)
)
layers_snnl.append(snnl)
snn_loss = torch.stack(layers_snnl).sum()
train_loss = torch.add(primary_loss, torch.mul(self.factor, snn_loss))
return train_loss, primary_loss, snn_loss
Visualizing Disentangled Representations
We trained an autoencoder with the soft nearest neighbor loss, and visualize its learned disentangled representations. The autoencoder had (x-500–500–2000-d-2000–500–500-x) units, and was trained on a small labelled subset of the MNIST, Fashion-MNIST, and EMNIST-Balanced datasets. This is to simulate the scarcity of labelled examples since autoencoders are supposed to be unsupervised models.

We only visualized an arbitrarily chosen 10 clusters for easier and cleaner visualization of the EMNIST-Balanced dataset. We can see in the figure above that the latent code representation became more clustering-friendly by having a set of well-defined clusters as indicated by cluster dispersion and correct cluster assignments as indicated by cluster colors.
Closing Remarks
In this article, we dissected the soft nearest neighbor loss function as to how we could implement it in PyTorch.
The soft nearest neighbor loss was first introduced by Salakhutdinov & Hinton (2007) where it was used to compute the loss on the latent code (bottleneck) representation of an autoencoder, and then the said representation was used for downstream kNN classification task.
Frosst, Papernot, & Hinton (2019) then expanded the soft nearest neighbor loss by introducing a temperature factor and by computing the loss across all layers of a neural network.
Finally, we employed an annealing temperature factor for the soft nearest neighbor loss to further improve the learned disentangled representations of a network, and also speed up the disentanglement process (Agarap & Azcarraga, 2020).
The full code implementation is available in GitLab.
References
- Agarap, Abien Fred, and Arnulfo P. Azcarraga. “Improving k-means clustering performance with disentangled internal representations.” 2020 International Joint Conference on Neural Networks (IJCNN). IEEE, 2020.
- Chapelle, Olivier, Bernhard Scholkopf, and Alexander Zien. “Semi-supervised learning (chapelle, o. et al., eds.; 2006)[book reviews].” IEEE Transactions on Neural Networks 20.3 (2009): 542–542.
- Frosst, Nicholas, Nicolas Papernot, and Geoffrey Hinton. “Analyzing and improving representations with the soft nearest neighbor loss.” International conference on machine learning. PMLR, 2019.
- Goldberger, Jacob, et al. “Neighbourhood components analysis.” Advances in neural information processing systems. 2005.
- He, Kaiming, et al. “Deep residual learning for image recognition.” Proceedings of the IEEE conference on computer vision and pattern recognition. 2016.
- Hinton, G., et al. “Neighborhood components analysis.” Proc. NIPS. 2004.
- Krizhevsky, Alex, Ilya Sutskever, and Geoffrey E. Hinton. “Imagenet classification with deep convolutional neural networks.” Advances in neural information processing systems 25 (2012).
- Roweis, Sam T., and Lawrence K. Saul. “Nonlinear dimensionality reduction by locally linear embedding.” science 290.5500 (2000): 2323–2326.
- Salakhutdinov, Ruslan, and Geoff Hinton. “Learning a nonlinear embedding by preserving class neighbourhood structure.” Artificial Intelligence and Statistics. 2007.
- Simonyan, Karen, and Andrew Zisserman. “Very deep convolutional networks for large-scale image recognition.” arXiv preprint arXiv:1409.1556 (2014).
- Van der Maaten, Laurens, and Geoffrey Hinton. “Visualizing data using t-SNE.” Journal of machine learning research 9.11 (2008).
Implementing Soft Nearest Neighbor Loss in PyTorch was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
Originally appeared here:
Implementing Soft Nearest Neighbor Loss in PyTorch
Go Here to Read this Fast! Implementing Soft Nearest Neighbor Loss in PyTorch



