

Background
You have probably seen AI generate images, such as these four corgis.
Maybe you have also seen AI generate sounds, such as these corgi barking sounds:
What if I told you these two generations are the exact same thing? Watch and listen for yourself!
Now, you might be confused about what I mean when I say “they are the same thing”. But do not worry; you will soon understand!
In May 2024, three researchers from the University of Michigan released a paper titled“Images that Sound: Composing Images and Sounds on a Single Canvas”.
In this post, I will explain
- What it means to generate “Images that Sound” and how this connects with previous work from humans
- How this model works on a technical level, presented in an easy-to-understand manner
- Why this paper challenges our understanding of what AI can and should do
What are Images that Sound?
To answer this question, we need to understand two terms:
- Waveform
- Spectrogram
In the real world, sound is produced by vibrating objects creating acoustic waves (changes in air pressure over time). When sound is captured through a microphone or generated by a digital synthesizer, we can represent this sound wave as a waveform:
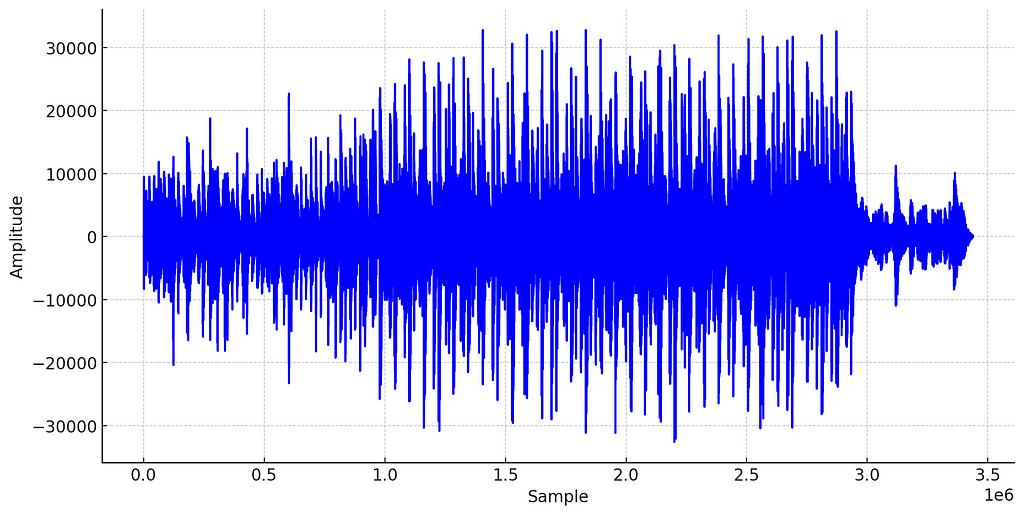
The waveform is useful for recording and playing audio, but it is typically avoided for music analysis or machine learning with audio data. Instead, a much more informative representation of the signal, the spectrogram, is used.
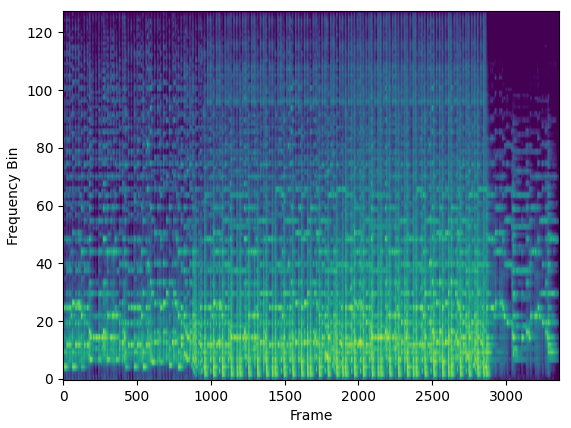
The spectrogram tells us which frequencies are more or less pronounced in the sound across time. However, for this article, the key thing to note is that a spectrogram is an image. And with that, we come full circle.
When generating the corgi sound and image above, the AI creates a sound that, when transformed into a spectrogram, looks like a corgi.
This means that the output of this AI is both sound and image at the same time.
How Does AI Generate These Artworks?
Even though you now understand what is meant by an image that sounds, you might still wonder how this is even possible. How does the AI know which sound would produce the desired image? After all, the waveform of the corgi sound looks nothing like a corgi.
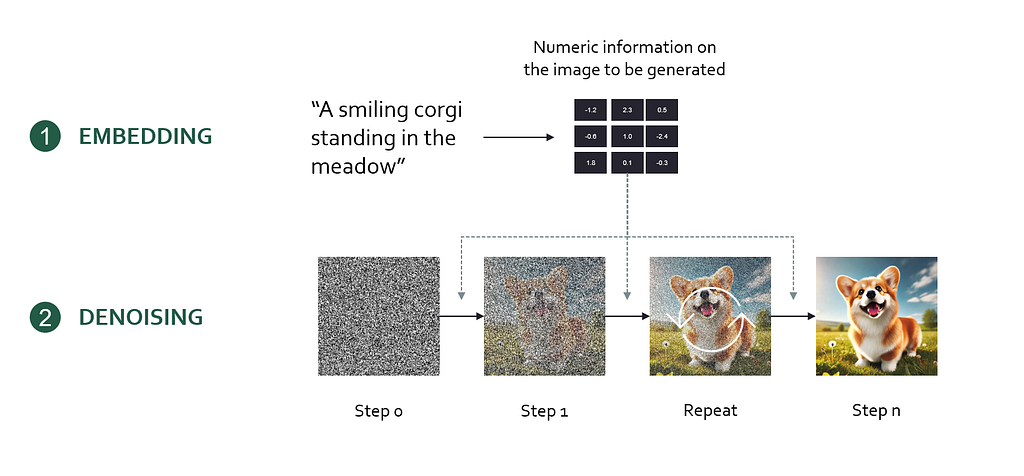
First, we need to understand one foundational concept: Diffusion models. Diffusion models are the technology behind image models like DALL-E 3 or Midjourney. In essence, a diffusion model encodes a user prompt into a mathematical representation (an embedding) which is then used to generate the desired output image step-by-step from random noise.
Here’s the workflow of creating images with a diffusion model
- Encode the prompt into an embedding (a bunch of numbers) using an artificial neural network
- Initialize an image with white noise (Gaussian noise)
- Progressively denoise the image. Based on the prompt embedding, the diffusion model determines an optimal, small denoising step that brings the image closer to the prompt description. Let’s call this the denoising instruction.
- Repeat denoising step until a noiseless, high-quality image is generated
To generate “images that sound”, the researchers used a clever technique by combining two diffusion models into one. One of the diffusion models is a text-to-image model (Stable Diffusion), and the other is a text-to-spectrogram model (Auffusion). Each of these models receives its own prompt, which is encoded into an embedding and determines its own denoising instruction.
However, multiple different denoising instructions are problematic, because the model needs to decide how to denoise the image. In the paper, the authors solve this problem by averaging the denoising instructions from both prompts, effectively guiding the model to optimize for both prompts equally.
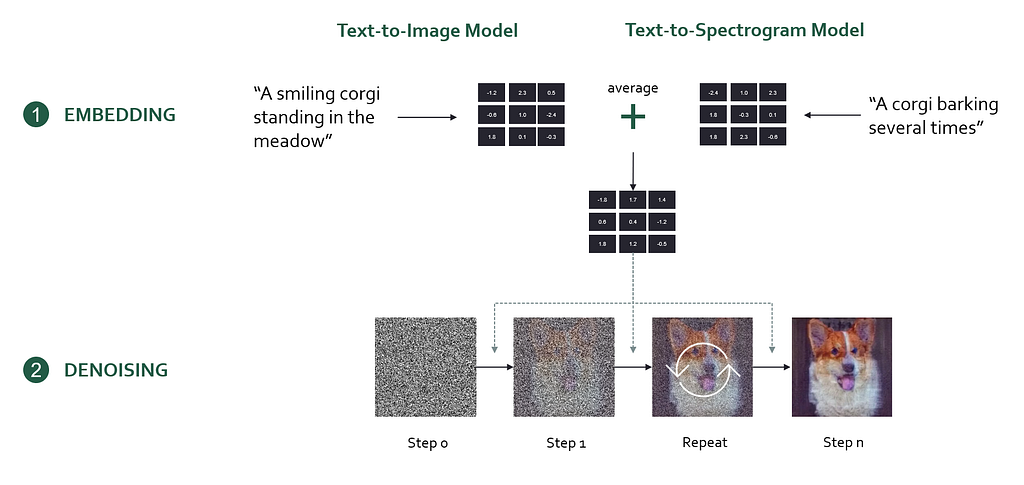
On a high level, you can think of this as ensuring the resulting image reflects both the image and audio prompt equally well. One downside of this is that the output will always be a mix of the two and not every sound or image coming out of the model will look/sound great. This inherent tradeoff significantly limits the model’s output quality.
How This Paper Challenges Our Understanding of AI
Is AI just Mimicking Human Intelligence?
AI is commonly defined as computer systems mimicking human intelligence (e.g. IMB, TechTarget, Coursera). This definition works well for sales forecasting, image classification, and text generation AI models. However, it comes with the inherent restriction that a computer system can only be an AI if it performs a task that humans have historically solved.
In the real world, there exist a high (likely infinite) number of problems solvable through intelligence. While human intelligence has cracked some of these problems, most remain unsolved. Among these unsolved problems, some are known (e.g. curing cancer, quantum computing, the nature of consciousness) and others are unknown. If your goal is to tackle these unsolved problems, mimicking human intelligence does not appear to be an optimal strategy.
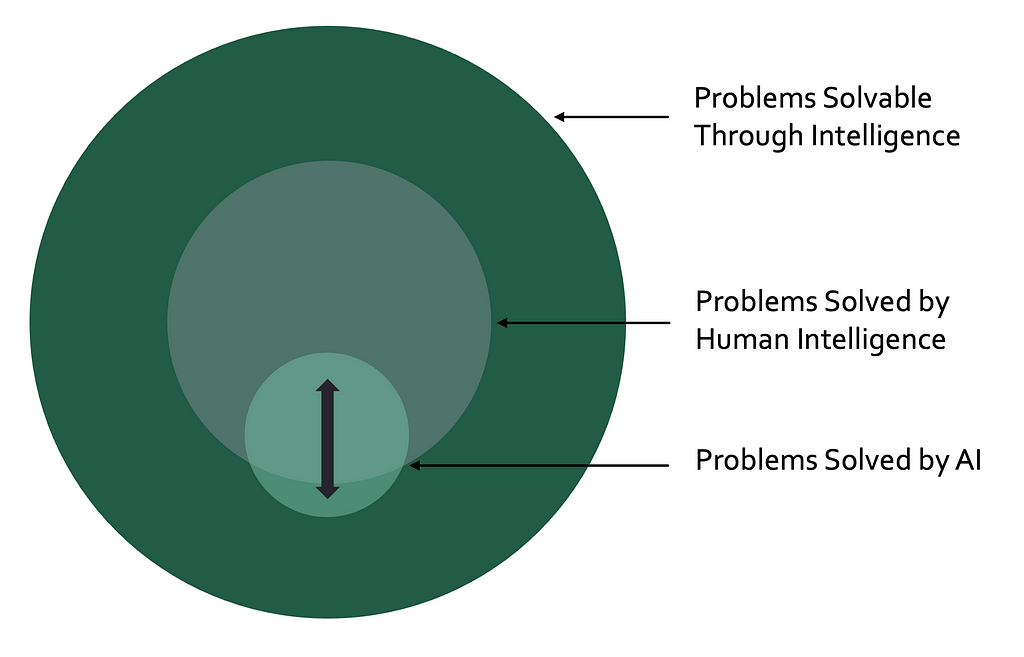
Following the definition above, a computer system that discovers a cure for cancer without mimicking human intelligence would not be considered AI. This is clearly counterintuitive and counterproductive. I do not intend to start a debate on “the one and only definition”. Instead, I want to emphasize that AI is much more than an automation tool for human intelligence. It has the potential to solve problems that we did not even know existed.
Can Spectrogram Art be Generated with Human Intelligence?
In an article on Mixmag, Becky Buckle explores the “history of artists concealing visuals within the waveforms of their music”. One impressive example of human spectrogram art is the song “∆Mᵢ⁻¹=−α ∑ Dᵢ[η][ ∑ Fjᵢ[η−1]+Fextᵢ [η⁻¹]]” by the British musician Aphex Twin.

Another example is the track “Look” from the album “Songs about my Cats” by the Canadian musician Venetian Snares.
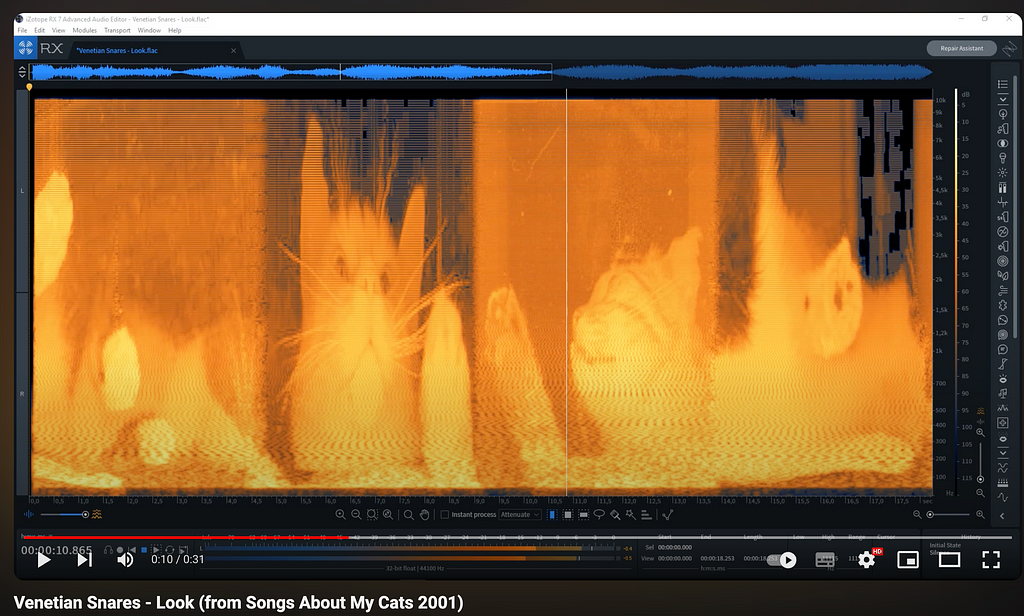
While both examples show that humans can encode images into waveforms, there is a clear difference to what “Images that Sound” is capable of.
How is “Images that Sound” Different from Human Spectrogram Art?
If you listen to the above examples of human spectrogram art, you will notice that they sound like noise. For an alien face, this might be a suitable musical underscore. However, listening to the cat example, there seems to be no intentional relationship between the sounds and the spectrogram image. Human composers were able to generate waveforms that look like a certain thing when transformed to a spectrogram. However, to my knowledge, no human has been able to produce examples where the sound and images match, according to predefined criteria.
“Images that Sound” can produce audio that sounds like a cat and looks like a cat. It can also produce audio that sounds like a spaceship and looks like a dolphin. It is capable of producing intentional associations between the sound and image representation of the audio signal. In this regard, the AI exhibits non-human intelligence.
“Images that Sound” has no Use Case. That’s what Makes it Beautiful
In recent years, AI has mostly been portrayed as a productivity tool that can enhance economic outputs through automation. While most would agree that this is highly desirable to some extent, others feel threatened by this perspective on the future. After all, if AI keeps taking away work from humans, it might end up replacing the work we love doing. Hence, our lives could become more productive, but less meaningful.
“Images that Sound” contrasts this perspective and is a prime example of beautiful AI art. This work is not driven by an economic problem but by curiosity and creativity. It is unlikely that there will ever by an economic use case for this technology, although we should never say never…
From all the people I’ve talked to about AI, artists tend to be the most negative about AI. This is backed up by a recent study from the German GEMA, showing that over 60% of musicians “believe that the risks of AI use outweigh its potential opportunities” and that only 11% “believe that the opportunities outweigh the risks”.
More works similar to this paper could help artists understand that AI has the potential to bring more beautiful art into the world and that this does not have to happen at the cost of human creators.
Outlook: Other Creative Uses of AI for Art
Images that Sound has not been the first use case of AI that has the potential to create beautiful art. In this section, I want to showcase a few other approaches that will hopefully inspire you and make you think differently about AI.
Restoring Art

AI helps restore art by repairing damaged pieces precisely, ensuring historical works last longer. This mix of technology and creativity keeps our artistic heritage alive for future generations. Read more.
Bringing Paintings to Live
AI can animate photos to create realistic videos with natural movements and lip-syncing. This can make historical figures or artworks like the Mona Lisa move and speak (or rap). While this technology is certainly dangerous in the context of deep fakes, applied to historical portraits, it can create funny and/or meaningful art. Read more.
Turning Mono-Recordings to Stereo
AI has the potential to enhance old recordings by transforming their mono mix into a stereo mix. There are classical algorithmic approaches for this, but AI promises to make artificial stereo mixes sound more and more realistic. Read more here and here.
Conclusion
Images that Sound is one of my favorite papers of 2024. It uses advanced AI training techniques to achieve a purely artistic outcome that creates a new audiovisual art form. What is most fascinating is that this art form exists outside of human capabilities, as of this day. We can learn from this paper that AI is not barely a set of automation tools that mimick human behavior. Instead, AI can enrich the aesthetic experiences of our lives by enhancing existing art or creating entirely novel works and art forms. We are only starting to see the beginnings of the AI revolution and I cannot wait to shape and experience its (artistic) consequences.
About Me
I’m a musicologist and a data scientist, sharing my thoughts on current topics in AI & music. Here is some of my previous work related to this article:
- 3 Music AI Breakthroughs to Expect in 2024: https://towardsdatascience.com/3-music-ai-breakthroughs-to-expect-in-2024-2d945ae6b5fd
- How Meta’s AI Generates Music Based on a Reference Melody: https://medium.com/towards-data-science/how-metas-ai-generates-music-based-on-a-reference-melody-de34acd783
- AI Music Source Separation: How it Works and Why it is so Hard: https://medium.com/towards-data-science/ai-music-source-separation-how-it-works-and-why-it-is-so-hard-187852e54752
Find me on Medium and Linkedin!
Images that Sound: Creating Stunning Audiovisual Art with AI was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
Originally appeared here:
Images that Sound: Creating Stunning Audiovisual Art with AI
Go Here to Read this Fast! Images that Sound: Creating Stunning Audiovisual Art with AI