

OpenAI’s new o1-preview is way too expensive for how it performs on the results
Many of my customers ask for advice on which LLM (Large Language Model) to use for building products tailored to Dutch-speaking users. However, most available benchmarks are multilingual and don’t specifically focus on Dutch. As a machine learning engineer and PhD researcher into machine learning at the University of Amsterdam, I know how crucial benchmarks have been to the advancement of AI — but I also understand the risks when benchmarks are trusted blindly. This is why I decided to experiment and run some Dutch-specific benchmarking of my own.
In this post, you’ll find an in-depth look at my first attempt at benchmarking several large language models (LLMs) on real Dutch exam questions. I’ll guide you through the entire process, from gathering over 12,000 exam PDFs to extracting question-answer pairs and grading the models’ performance automatically using LLMs. You’ll see how models like o1-preview, o1-mini, GPT-4o, GPT-4o-mini, and Claude-3 performed across different Dutch educational levels, from VMBO to VWO, and whether the higher costs of certain models lead to better results. This is just a first go at the problem, and I may dive deeper with more posts like this in the future, exploring other models and tasks. I’ll also talk about the challenges and costs involved and share some insights on which models offer the best value for Dutch-language tasks. If you’re building or scaling LLM-based products for the Dutch market, this post will provide valuable insights to help guide your choices as of September 2024.
It’s becoming more common for companies like OpenAI to make bold, almost extravagant claims about the capabilities of their models, often without enough real-world validation to back them up. That’s why benchmarking these models is so important — especially when they’re marketed as solving everything from complex reasoning to nuanced language understanding. With such grand claims, it’s vital to run objective tests to see how well they truly perform, and more specifically, how they handle the unique challenges of the Dutch language.
I was surprised to find that there hasn’t been extensive research into benchmarking LLMs for Dutch, which is what led me to take matters into my own hands on a rainy afternoon. With so many institutions and companies relying on these models more and more, it felt like the right time to dive in and start validating these models. So, here’s my first attempt to start filling that gap, and I hope it offers valuable insights for anyone working with the Dutch-language.
Why Dutch-Specific Benchmarks Matter
Many of my customers work with Dutch-language products, and they need AI models that are both cost-effective and highly performant in understanding and processing Dutch. Although large language models (LLMs) have made impressive strides, most of the available benchmarks focus on English or multilingual capabilities, often neglecting the nuances of smaller languages like Dutch. This lack of focus on Dutch is significant because linguistic differences can lead to large performance gaps when a model is asked to understand non-English texts.
Five years ago, NLP — deep learning models for Dutch were far from mature (Like the first versions of BERT). At the time, traditional methods like TF-IDF paired with logistic regression often outperformed early deep-learning models on Dutch language tasks I worked on. While models (and datasets) have since improved tremendously, especially with the rise of transformers and multilingual pre-trained LLMs, it’s still critical to verify how well these advances translate to specific languages like Dutch. The assumption that performance gains in English carry over to other languages isn’t always valid, especially for complex tasks like reading comprehension.
That’s why I focused on creating a custom benchmark for Dutch, using real exam data from the Dutch “Nederlands” exams (These exams enter the public domain after they have been published). These exams don’t just involve simple language processing; they test “begrijpend lezen” (reading comprehension), requiring students to understand the intent behind various texts and answer nuanced questions about them. This type of task is particularly important because it’s reflective of real-world applications, like processing and summarizing legal documents, news articles, or customer queries written in Dutch.
By benchmarking LLMs on this specific task, I wanted to gain deeper insights into how models handle the complexity of the Dutch language, especially when asked to interpret intent, draw conclusions, and respond with accurate answers. This is crucial for businesses building products tailored to Dutch-speaking users. My goal was to create a more targeted, relevant benchmark to help identify which models offer the best performance for Dutch, rather than relying on general multilingual benchmarks that don’t fully capture the intricacies of the language.


How the Benchmarking Works
Let me walk you through how I built and executed this benchmark:
- PDF Collection: I began by collecting over 12,000 PDFs from Dutch state exams. These exams include reading passages and questions that test a student’s ability to comprehend and interpret written Dutch.
- Data Extraction: Next, I extracted the relevant information from the PDFs using LLMs, turning the text into structured question-answer (Q&A) pairs. For example, a typical question from a PDF might look like this: “Wat is de hoofdgedachte van de schrijver in alinea 3 van tekst 2?” After extraction, this question becomes a structured Q&A pair like this: Question: What is the main idea of the author in paragraph 3?
Correct Answer: The author argues that technological advancements bring both positive and negative consequences (2 points) - Model selection: The selection of models in this benchmark includes a mix of well-known LLMs, ranging from smaller, more cost-efficient models like o1-mini and gpt-4o-mini, to more expensive options like o1-preview. These models were tested on Dutch-language tasks to assess their ability to handle reading comprehension (“begrijpend lezen”) tasks from the Dutch “Nederlands” exam. Notably, Claude-3–5-sonnet and Claude-3-haiku were also included, providing insight into how AI models from Anthropic stack up against the GPT family. I selected several models to do this initial benchmark with, definitely not extensive enough yet. Let me know if you would want me to add more in the future!
- Question answering: The fun part! I hooked up the APIs of the LLMs and gave them a question with corresponding texts and let them answer the questions. It became less fun when the more expensive models kicked in and my credit card started informing me it was not very excited about these endeavors. The lengths I go through for my readers!
- Automated Grading: Using a prompt that knows the correct answer I ask for an objective decision if the required answer is in the answer given by the LLM. With this method, the LLM-generated answers are compared to the correct answers from the official answer sheets. Each question is scored based on how closely the model’s answer matches the correct one.
- Scoring & Reporting: After grading, the models are evaluated on how many points they earned relative to the maximum possible points for each exam. This scoring gives a clear idea of which models perform well and which struggle with Dutch reading comprehension tasks.
It’s a bit surreal when you think about it — LLMs benchmarking other LLMs, graded by LLMs, without a human in sight (except me, writing the code to let them do this on a rainy afternoon). This method allows for scalable and automated comparisons, but it’s not without limitations. While this approach gives a strong basis for comparing models, it’s not the final word. Still, I wanted to put together something to gain insight into how these models perform in the context of the Dutch language specifically.
The API Cost Dilemma
Running these benchmarks came at a significant cost. Processing full-text exam questions with every request quickly consumed tokens, and I ended up spending over €100 in API fees just for this initial round of testing. This forced some limitations on how many questions I could process with the different models, but it was still enough to uncover some valuable insights.
If any Dutch institutions are interested in collaborating on more extensive benchmarking efforts, I’d be eager to work together to scale this project. By expanding the scope, we could dive deeper into a wider range of exams, significantly increase the number of questions answered, and benchmark a broader selection of models. This would provide even more comprehensive insights into model performance help refine our understanding of how various LLMs handle Dutch-language tasks across different educational levels and complexities and help companies pick the best LLM and not the best marketing.
I conducted two separate benchmarks: one with smaller, cheaper models, and another with larger, more expensive models until I hit my daily API limits. The number of exam questions used was 329 for the cheaper models and 104 for the more expensive “titans.” To put this in perspective, this would be equivalent to a human taking approximately 4 to 13 full exams.
Here’s a breakdown of the model pricing (as of September 25th, via LLM Price Check):
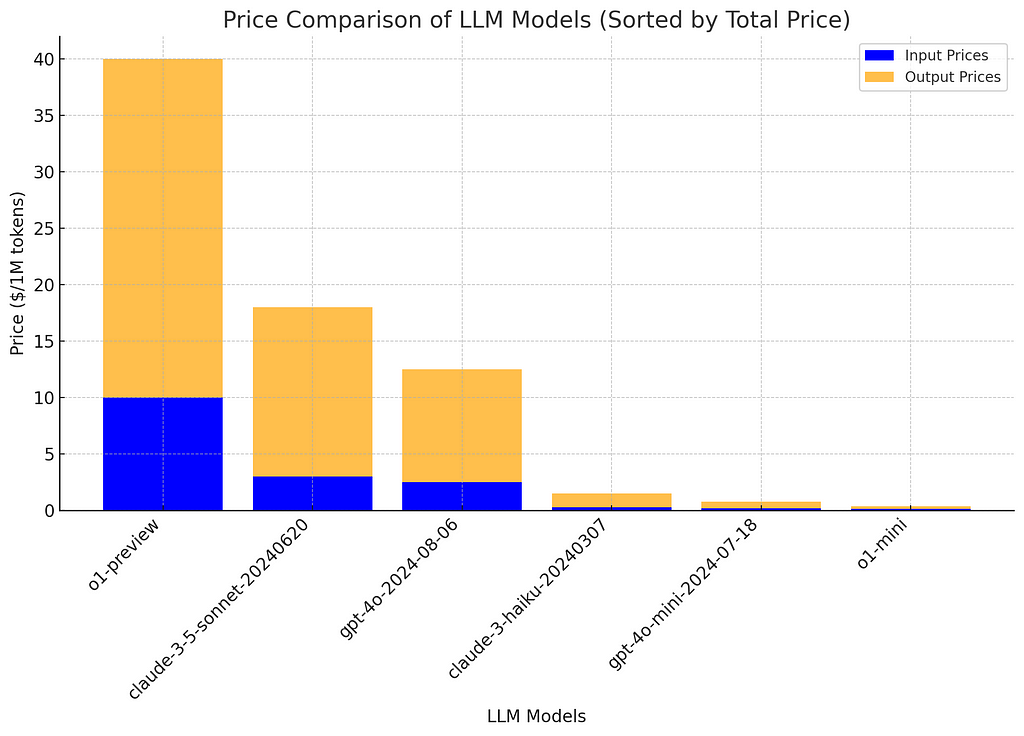
- “o1-preview” costs $10 per million tokens for input and $30 for output.
- “o1-mini,” on the other hand, costs only $0.10 per million tokens for input and $0.25 for output.
This means “o1-preview” is approximately 114 times more expensive than “o1-mini.” The key question, then, is whether the extra cost translates into better performance, and if so, by how much. So, is it worth the extra cost?
Benchmarking the Models: Fast, Cheap, and… Better?
Since the launch of o1-preview, I’ve been skeptical about its performance, as it seemed slower and significantly more expensive compared to other models. So, I was eager to see how it would perform in this benchmark.
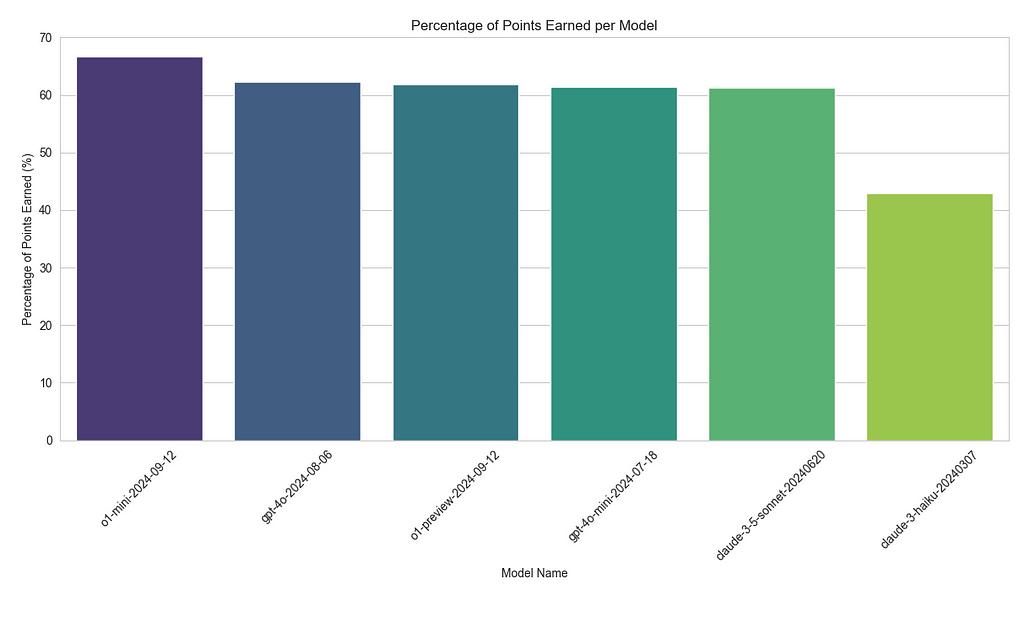
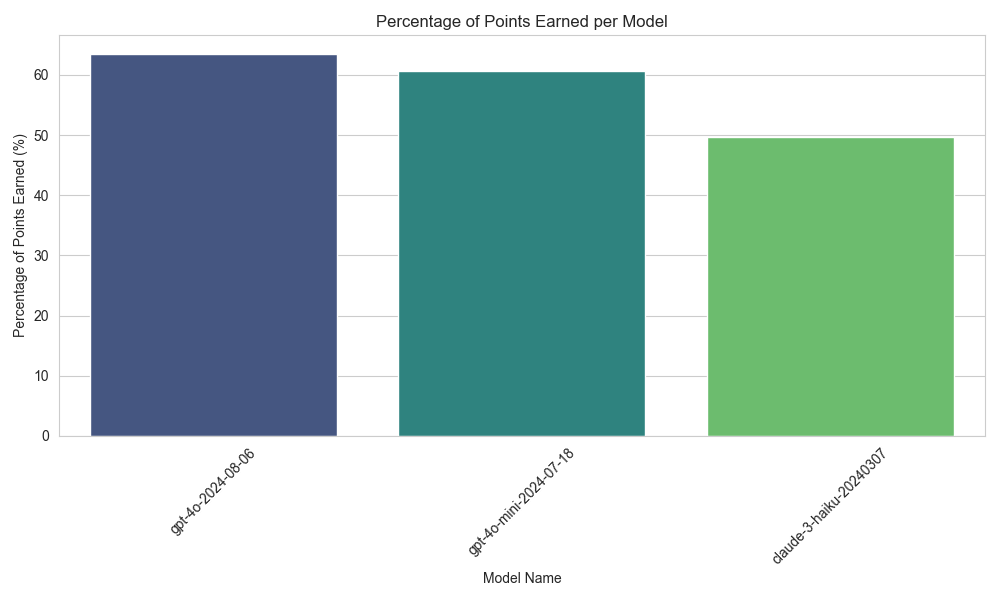
Interestingly, the o1-mini model actually outperformed more expensive options like GPT-4o and o1-preview. Specifically, o1-mini earned 66.75% of the possible points, compared to 62.32% for GPT-4O and 61.91% for o1-preview. Based on these results, I’m now considering shifting from GPT-4O-mini, which earned 61.36%, to o1-mini for Dutch language tasks, as it offers better performance at a significantly lower cost.
Here’s how the other models fared:
- Claude-3–5-sonnet earned 61.28%, while
- Claude-3-haiku lagged behind, with only 42.91%.
Seems like going for the Claude models will cause less performant products that are also more expensive.
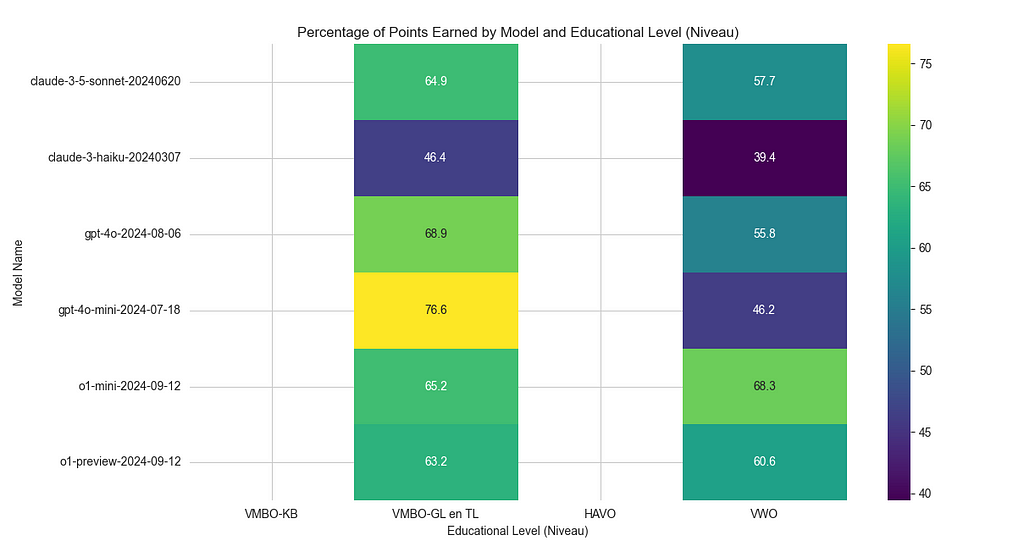
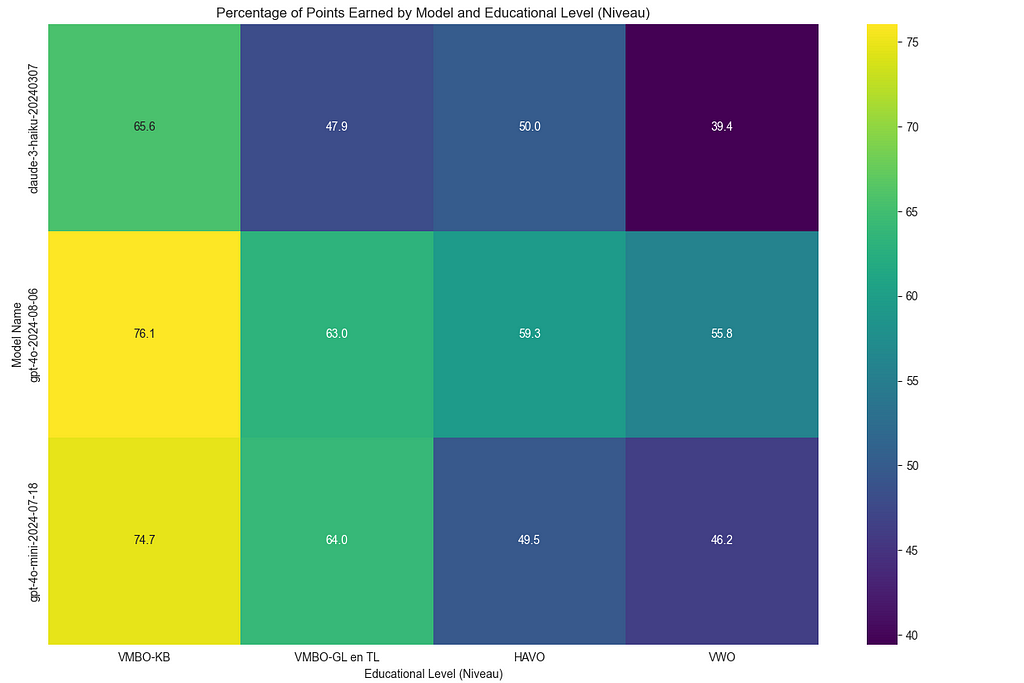
The performance breakdown also showed that all of these models handled VMBO-level exams more easily but struggled with the more complex VWO-level questions — something expected given the increasing difficulty of the exams. This highlights the value of using a more cost-effective model like o1-mini, which not only performs well across a variety of tasks but also delivers strong results on more advanced educational content.
Handling Different Exam Levels: The exams are divided into different educational levels, such as VMBO, HAVO, and VWO. My system tracks how well models perform across these different levels. Unsurprisingly, the models did better on simpler VMBO-level questions and struggled more with complex VWO-level questions.
Limitations and Next Steps
It’s important to mention that it’s possible some of these Dutch exam texts may have been part of the training data for certain LLMs, which could have impacted the results. However, these benchmarks still offer valuable insights for developers working on Dutch-language products.
That said, the number of questions processed so far is relatively low. In future iterations, I plan to run more comprehensive benchmarks to generate even deeper insights into the models’ performance.
This approach to benchmarking can be extended to other subjects, and I also filtered out pure-text questions. Setting up a benchmark for multimodal models, which can analyze images alongside text, would be particularly interesting since many exams, such as history and geography, involve visual elements like charts, maps, or diagrams.
In the future, this method could easily be applied to other Dutch courses such as Biologie, Natuurkunde, Scheikunde, Wiskunde A/B/C, Aardrijkskunde, Bedrijfseconomie, Economie, Filosofie, Geschiedenis, Maatschappijwetenschappen, Kunst, Muziek, Tehatex, and languages like Arabisch, Duits, Engels, Frans, Fries, Grieks, Latijn, Russisch, Spaans, and Turks. Extending this to subjects like Natuur- en scheikunde 1 & 2, Wiskunde, Maatschappijleer, and even the arts (e.g., Dans, Drama, Beeldende vakken) would provide a broad view of model performance across diverse disciplines.
If you’re interested in supporting this project, feel free to reach out or buy me a coffee! The code I’ve developed is scalable and can handle a much larger range of Dutch exams and topics with the right resources. Collaborating to explore these additional subjects and multimodal benchmarks would open up even deeper insights into how AI models can perform in Dutch education.
Final Thoughts
If you want help with building or scaling AI or machine learning products responsibly, or if you’re curious about which LLMs perform best in specific languages like Dutch, I’d be happy to help through my company, The AI Factory. Feel free to reach out! Feel free to contact me, and if you found this benchmarking useful, follow me on LinkedIn for updates on future AI and performance insights.
I Spent My Money on Benchmarking LLMs on Dutch Exams So You Don’t Have To was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
Originally appeared here:
I Spent My Money on Benchmarking LLMs on Dutch Exams So You Don’t Have To
Go Here to Read this Fast! I Spent My Money on Benchmarking LLMs on Dutch Exams So You Don’t Have To