

From concepts to practical code snippets for effective testing
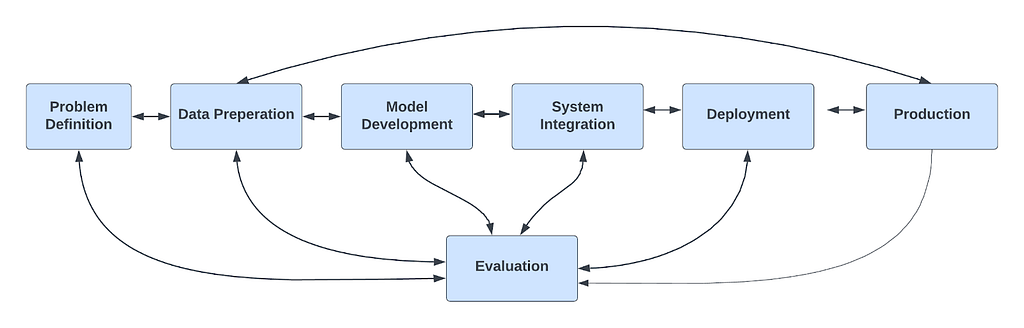
Testing in software development is crucial as it safeguards the value delivered to your customers. Delivering a successful product isn’t a one-time effort; it’s an ongoing process. To ensure continuous delivery, we must define success, curate the data, and then train and deploy our models while continuously monitoring and testing our work.
To deliver continuously, we must Define success, curate the data, and then train and deploy our models while continuously monitoring and testing our work. “Trust” in ML Systems requires more than just testing; it must be integrated into the entire lifecycle (as shown in another blog of mine).
Before diving into the detailed sections, here’s a quick TL;DR for everyone, followed by more in-depth information tailored for ML practitioners.
TL;DR
Testing machine learning is hard because it’s probabilistic by nature, and must account for diverse data and dynamic real-world conditions.
You should start with a basic CI pipeline. Focus on the most valuable tests for your use case: Syntax Testing, Data Creation Testing, Model Creation Testing, E2E Testing, and Artifact Testing. Most of the time the most valuable test is E2E Testing.
To understand what value each kind of test brings we define the following table:
To be effective in testing machine learning models, it’s important to follow some best practices that are unique to ML testing, as it differs significantly from regular software testing.
Now that you’ve got the quick overview, let’s dive deeper into the details for a comprehensive understanding.
Why Testing ML is Hard
Testing machine learning systems introduces unique complexities and challenges:
- Data Complexity: Handling data effectively is challenging; it needs to be valid, accurate, consistent, and timely, and it keeps changing.
- Resource-Intensive Processes: Both the development and operation of ML systems can be costly and time-consuming, demanding significant computational and financial resources.
- Complexity: ML systems include many components, and there are a lot of places things can go wrong. In addition, integration often requires proper communication.
- System Dynamics and Testing Maturity: Machine learning systems are prone to frequent changes and silent failures.
- Probabilistic Nature: Machine learning models often produce outputs that are not deterministic. In addition, the data fetched may not be deterministic.
- Specialized Hardware Requirements: ML systems often require advanced hardware setups, such as GPUs.
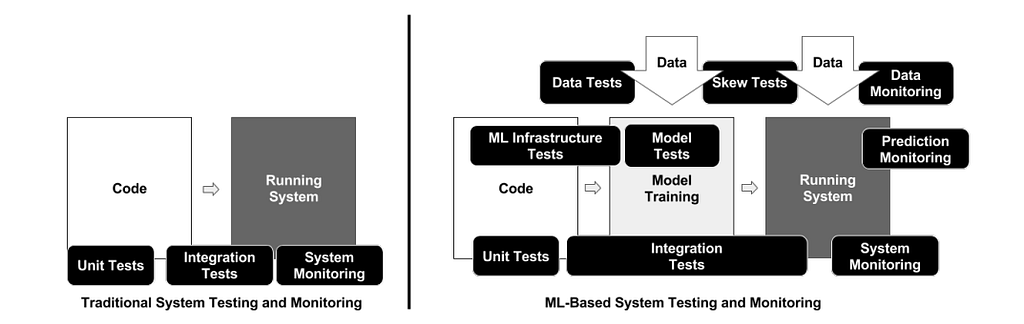
How to Start
Always start with setting up the CI workflow, as it’s straightforward and reduces the barrier to testing. Setting up CI involves automating your build and test processes, ensuring that code changes are continuously integrated and tested. This automation makes the process more consistent and helps avoid many potential issues.
The good news is that this process is quite repetitive and can be easily automated. Pre-commit will handle executing the syntax validation process, ensuring that your code “compiles”. Meanwhile, pytest will run the tests to verify that your code behaves as expected.
Here’s a code snippet for a GitHub Action that sets up this workflow:
Now that we have a running CI pipeline, we can explore which tests we should run according to the tests’ value.
You can start small and gradually expand your tests as you discover bugs, adding tests for each issue you encounter. As long as the CI pipeline is in place, the main barrier to testing is simply knowing what to test.
Syntax Testing
When executing machine learning code, it’s important to verify syntax-related elements early in the development process to identify potential issues before they escalate. Given that machine learning workflows typically consist of a mix of Python code, SQL queries, and configuration files, each component demands specific validation checks:
Python Code Validation
Validating Python code through syntax checks using AST and type checks using MyPy helps prevent runtime errors and functional discrepancies that could impact the entire machine-learning pipeline.
Here’s a code snippet for pre-commit to test Python syntax and typing.
SQL Query Validation
Validating SQL queries is crucial for ensuring that data retrieval processes are structured correctly and are free from errors. For static checks like syntax, tools like SQLFluff can be integrated with pre-commit hooks to automatically lint SQL code.
Here’s a code snippet for pre-commit to test SQL syntax.
However, to handle runtime issues such as verifying the existence of a column, we would need to use the EXPLAIN statement on all SQL. This is effective as it only plans the queries but does not execute them. If a query is invalid, the EXPLAIN command will fail. This method is supported by most SQL dialects but requires database connectivity to execute.
Here’s a code snippet to test SQL syntax and metadata using pytest.
Configuration File Validation
Ensuring the validity of configuration files is critical as they often control the operational parameters of a machine learning model, typically in JSON or YAML formats. For basic validation, it’s essential to check that these files are syntactically correct.
Here’s a code snippet for pre-commit to test YAML and JSON syntax.
However, syntax validation alone is insufficient. It’s crucial to also ensure that the settings—like hyperparameters, input/output configurations, and environmental variables—are suitable for your application. Using a tool like cerberus via pytest enables comprehensive validation against a predefined schema, ensuring that the configurations are correct and practical.
By testing the syntax of code, queries, and configurations, developers can substantially enhance the stability and reliability of machine learning systems, enabling smoother deployments and operations.
I’d suggest incorporating these checks into every project. They’re pretty straightforward to replicate and can help you avoid many unnecessary issues. Plus, they’re essentially copy-paste, making them easy to implement.
Data Creation Testing
Data Creation Testing ensures your feature engineering work correctly, following the idea of “garbage in, garbage out”.
In software testing, various methods such as unit tests, property-based testing, component tests, and integration tests each have their own strengths and weaknesses. We will explore each of these strategies in more detail shortly.
We will explore all the testing options by starting with an example from the Titanic dataset, where we calculate get_family_size, where family size is based on the number of parents and siblings.
Data Creation Unit Tests
Tests are used for validating the business logic of individual functions, primarily focusing on optimal scenarios, or “happy paths,” but they also help identify issues in less ideal scenarios, known as “paths of sorrow.”
Here is an example of a unit test that checks the get_family_size functionality:
In different modalities, including vision, NLP, and generative AI, unit tests are used a bit differently. For example, in NLP and large language models (LLMs), testing the tokenizer is critical as it ensures accurate text processing by correctly splitting text into meaningful units. In image recognition, tests can check the model’s ability to handle object rotation and varying lighting conditions.
However, unit tests alone are not enough because they focus on specific functions and miss side effects or interactions with other components. While great for checking logical code blocks like loops and conditions, their narrow scope, often using test doubles, can overlook behavior changes in areas not directly tested.
Data Creation Property-Based Testing
Property-based testing is a testing approach where properties or characteristics of input data are defined, and test cases are automatically generated to check if these properties hold true for the system under test.
Property-based testing ensures the system does not encounter issues with extreme or unusual inputs. This method can uncover problems that example-based tests might miss.
Some good/common properties you should test:
- The code does not crash. This one is extremely effective.
- Equivalent functions return the same results.
- Great expectation Invariants.
- Correct schemas.
- Other properties like Idempotent, commutative, associative, etc.
Here is an example of a property-based test that ensures get_family_size behaves correctly under a range of edge cases and input variations:
Property tests, while powerful, often overlook the complexities of software dependencies, interdependencies, and external systems. Running in isolation, they may miss interactions, state, and real-world environmental factors.
Data Creation Component Tests
Component testing validates individual parts of a software system in isolation to ensure they function correctly before integration. Excel helps uncover unusual user behaviors and edge cases that unit and property tests might miss, representing the system’s status closely and anticipating ‘creative’ user interactions.
To keep these tests maintainable and fast, data samples are used. One should choose the right source data and sample sizes required.
Here is an example of a component test that ensures get_family_size behaves correctly on real data, with real dependencies:
Picking Production or Staging for Data Creation
To keep data volumes manageable, modify your queries or dataset for continuous integration (CI) by injecting a LIMIT clause or an aggressive WHERE clause.
Choosing a staging environment for more controlled, smaller-volume tests is often the best approach. This environment offers easier reproducibility and fewer privacy concerns. However, since it is not production, you must verify that the staging and production schemas are identical.
The following code snippet verify production Athena table has the same schema as staging Athena table.
Choose production to see how features operate with real user data. This environment provides a full-fledged view of system performance and user interaction.
Data Creation Integration Tests
While component tests provide a focused view, a broader perspective is sometimes necessary. Integration tests evaluate the cooperation between different modules, ensuring they function together seamlessly.
The goal of integration testing is to ensure that the pipeline makes sense, not necessarily to verify every small detail for correctness, so avoid brittle assertion sections.
Here is an example of an integration test that ensures feature_engineering behaves correctly on real data, with real dependencies:
Using property tests for a wide portion of feature engineering processes (like integration tests) is not ideal. These tests often require extensive setup and maintenance, and their complexity increases significantly.
Here is an example to show how complicated property-based testing can become:
Data Creation Testing Strategy
Choosing the right testing strategy is crucial for ensuring robust and maintainable code. Here’s a breakdown of when and how to use different types of tests:
- Unit Tests: unit tests are ideal for validating individual functions. They can be fragile, often requiring updates or replacements as the code evolves. While useful early on, their relevance may diminish as the project progresses.
- Property-Based Testing: Best for cases where edge cases could be critical and requirements are stable. These tests are designed to cover a wide range of inputs and validate behavior under theoretical conditions, which makes them robust but sometimes complex to maintain.
- Component Tests: These offer a practical balance, being easier to set up than property-based tests. Component tests effectively mimic real-world scenarios, and their relative simplicity allows for easier replication and adaptation. They provide a useful layer of testing that adapts well to changes in the system.
- Integration Tests: Positioned to confirm the overall system correctness, integration tests blend a high-level view with enough detail to aid in debugging. They focus on the interaction between system parts under realistic conditions, generally checking the properties of outputs rather than exact values. This approach makes integration tests less precise but easier to maintain, avoiding the trap of tests becoming too cumbersome.
Model Creation Testing
The next set of tests focuses on verifying whether the process of creating a model works properly. The distinction I make in this section, compared to tests related to artifacts, is that these tests do not require a lot of data and should be performed for every pull request.
There are many types of tests to ensure the correctness of model training. Below is a non-exhaustive list of some crucial tests you should consider.
Verify Training is Done Correctly
To verify correct training, track key indicators such as the loss function; a consistently decreasing loss signals effective learning. For example, signs of overfitting by comparing performance on training and validation.
The following code snippet validates that the training loss is monotonically decreasing:
The same strategy for verifying correct training applies to different modalities like NLP, LLM, and vision models.
Ability to Overfit
Test the model’s capacity to learn from a very small amount of data by making it overfit to this batch and checking for perfect alignment between predictions and labels. This is important because it ensures that the model can effectively learn patterns and memorize data, which is a fundamental aspect of its learning capability.
The following tests validate that given enough signal the model can learn:
The same strategy for verifying correct training applies to different modalities like NLP, LLM, and vision models.
GPU/CPU Consistency
Confirming that the model provides consistent output and performance on different computing platforms is crucial for reliability and reproducibility. This ensures that the model performs as expected across various environments, maintaining user trust and delivering a robust machine-learning solution.
The following code snippet validate that the model gives the same predictions for CPU and GPU versions:
The same strategy for verifying correct training applies to different modalities like NLP, LLM, and vision models.
Training is Reproducible
Ensuring the model training process can be consistently replicated is crucial for reliability and credibility. It facilitates debugging and aids collaboration and transparency.
The following code snippet validates the model training is reproducible:
The same strategy for verifying correct training applies to different modalities like NLP, LLM, and vision models.
These tests run on small data to provide a sanity check that the model’s basic functionality makes sense. Further validation and evaluation on larger datasets are necessary to ensure the model delivers real value and performs well in production in the following section.
4. E2E Testing
E2E testing in machine learning involves testing the combined parts of a pipeline to ensure they work together as expected. This includes data pipelines, feature engineering, model training, and model serialization and export. The primary goal is to ensure that modules interact correctly when combined and that system and model standards are met.
Conducting E2E tests reduces the risk of deployment failures and ensures effective production operation. It’s important to keep the assertion section not brittle, the goal of the integration test is to make sure the pipeline makes sense, not that it’s correct.
Integration testing ensures cohesion by verifying that different parts of the machine learning workflow. It detects system-wide issues, such as data format inconsistencies and compatibility problems, and verifies end-to-end functionality, confirming that the system meets overall requirements from data collection to model output.
Since machine learning systems are complex and brittle, You should add integration tests as early as possible.
The following snippet is integration tests of the entire ML pipeline:
Integration tests require careful planning due to their complexity and resource demands and execution time. Even for integration tests, smaller ones are better. These tests can be complex to set up and maintain, especially as systems scale and evolve.
5. Artifact Testing
Once the model has been trained on a sufficiently large dataset, it is crucial to validate and evaluate the resulting model artifact. This section focuses on ensuring that the trained model not only functions correctly but also delivers meaningful and valuable predictions. Comprehensive validation and evaluation processes are necessary to confirm the model’s performance, robustness, and ability to generalize to new, unseen data.
There are many types of tests to ensure the correctness of model training. Below is a non-exhaustive list of some crucial tests you should consider.
Model Inference Latency
Measure how long the model takes to make predictions to ensure it meets performance criteria. In scenarios like Adtech, fraud detection, and e-commerce, the model must return results within a few milliseconds; otherwise, it cannot be used.
The following code snippet validates that model latency is acceptable:
The same strategy for verifying correct training applies to different modalities like NLP, LLM, and vision models.
Metamorphic Testing Invariance Tests
Metamorphic testing involves creating tests that verify the consistency of a model’s behavior under certain transformations of the input data. Invariance tests are a specific type of metamorphic testing that focuses on the model’s stability by ensuring that changes in inputs that should be irrelevant do not affect the outputs.
The following code snippet aims to make sure a change in a column that should not affect the model prediction, actually doesn’t affect the model prediction:
It can be useful for other modalities as well. In NLP, an invariance metamorphic test could verify that adding punctuation or stopwords to a sentence does not alter the sentiment analysis outcome. In LLM applications, a test could ensure that rephrasing a question without changing its meaning does not affect the generated answer. In vision, an invariance test might check that minor changes in background color do not impact the image classification results.
Metamorphic Testing Directional Tests
Metamorphic testing involves creating tests that verify the consistency of a model’s behavior under certain transformations of the input data. Directional tests, a subset of metamorphic testing, focus on ensuring that changes in relevant inputs lead to predictable logic in one direction in the outputs.
The following code snippet aims to make sure a change that travelers that paid mode will have better chances of surviving according to model prediction:
It can be useful for other modalities as well, In NLP, a directional metamorphic test could involve verifying that increasing the length of a coherent text improves the language model’s perplexity score. In LLM applications, a test could ensure that adding more context to a question-answering prompt leads to more accurate and relevant answers.
Model Learnt Reasonably
Ensure that the model achieves acceptable performance across the entire dataset, closely related to model evaluation, verifying its overall effectiveness and reliability.
The following code snippet that validates model performance is acceptable:
It’s pretty common to have high-priority segments that need targeted testing to ensure comprehensive model evaluation. Identifying important use cases and testing them separately is crucial to make sure that a model update does not compromise them. For instance, in a cancer detection scenario, certain types of cancer, such as aggressive or late-stage cancers, maybe more critical to detect accurately than more treatable forms.
The same strategy for verifying correct training applies to different modalities like NLP, LLM, and vision models.
Best Practices for ML Testing
- Automate Tests: this will ensure consistency and save time later.
- Be Pragmatic: Perfect coverage isn’t necessary; each project has its own tolerance for errors.
- Avoid testing fatigue and understand the blast radius.
- Don’t Test External Libraries
- Configurable Parameters: Code should be composable. To test code, you want the DataFrame to be injectable to the test, and so on.
- Tests Should Run in Reasonable Time: Use small, simple data samples. If your test requires substantial time, consider when to run it. For example, it’s useful to create tests that can be executed manually or scheduled.
The following code snippet makes the CI run on demand and once a day:
- Contract Validation and Documentation: Increase the use of assertions within your code to actively check for expected conditions (active comments), reducing the reliance on extensive unit testing.
- Prioritize Integration Tests: While unit tests are crucial, integration tests ensure that components work together smoothly. Remember, the biggest lie in software development is, “I finished 99% of the code, I just need to integrate it.”
- Continuous improvement: When you encounter errors in production or during manual testing, include them in your testing suite.
- Avoid Mocking Your Functions: Mocking your functions can lead to more work and a lot of false alarms.
- Tests Should Aim to Represent Real Scenarios.
- Aim for Maintainable and Reliable Tests: Address flaky tests that fail inconsistently. Flakiness is not linear; even a small percentage of failures can significantly impact overall reliability.
- Each Type of Test Has its Own Properties: This table outlines the properties, advantages, and disadvantages of each testing strategy. While the table remains unchanged, the properties of each test may vary slightly depending on the use case.
Last words
In this article, we discussed the challenges of testing machine learning models.
I hope I was able to share my enthusiasm for this fascinating topic and that you find it useful. Feel free to reach out to me via email or LinkedIn.
Thanks to Almog Baku and Ron Itzikovitch for reviewing this post and making it much clearer.
The following testing resources are great :
– Don’t Mock Machine Learning Models In Unit Tests
– How to Test Machine Learning Code and Systems
– Effective testing for machine learning systems
– Metamorphic Testing of Machine-Learning Based Systems
How to Test Machine Learning Systems was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
Originally appeared here:
How to Test Machine Learning Systems
Go Here to Read this Fast! How to Test Machine Learning Systems