

Optimizing data transfer for enterprise data lakes
1. Introduction
Azure Data Factory (ADF) is a popular tool for moving data at scale, particularly in Enterprise Data Lakes. It is commonly used to ingest and transform data, often starting by copying data from on-premises to Azure Storage. From there, data is moved through different zones following a medallion architecture. ADF is also essential for creating and restoring backups in case of disasters like data corruption, malware, or account deletion.
This implies that ADF is used to move large amounts of data, TBs and sometimes even PBs. It is thus important to optimize copy performance and so to limit throughput time. A common way to improve ADF performance is to parallelize copy activities. However, the parallelization shall happen where most of the data is and this can be challenging when the data lake is skewed.
In this blog post, different ADF parallelization strategies are discussed for data lakes and a project is deployed. The ADF solution project can be found in this link: https://github.com/rebremer/data-factory-copy-skewed-data-lake.
2. Data lake data distribution
Data Lakes come in all sizes and manners. It is important to understand the data distribution within a data lake to improve copy performance. Consider the following situation:
- An Azure Storage account has N containers.
- Each container contains M folders and m levels of sub folders.
- Data is evenly distributed in folders N/M/..
See also image below:
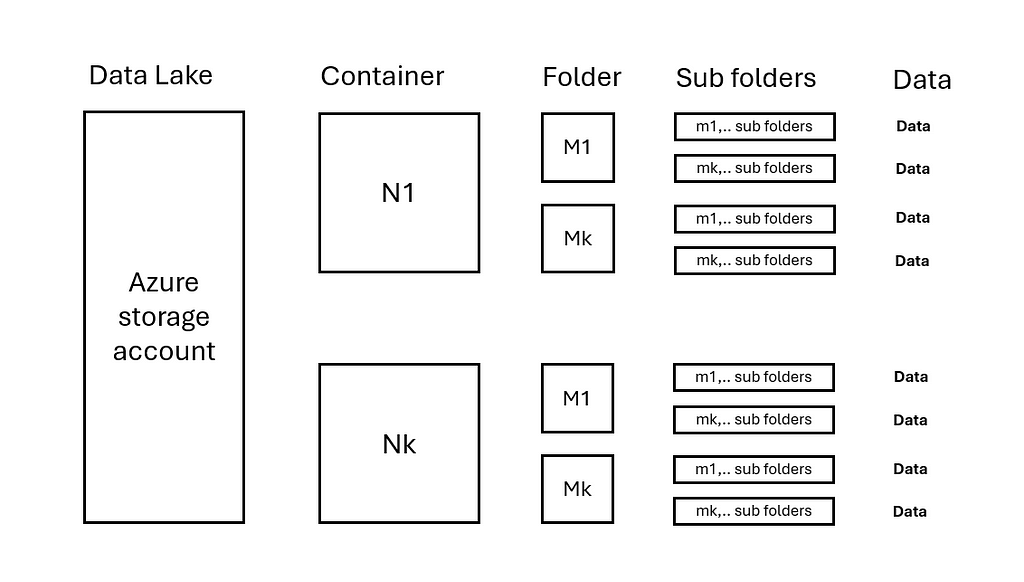
In this situation, copy activities can be parallelized on each container N. For larger data volumes, performance can be further enhanced by parallelizing on folders M within container N. Subsequently, per copy activity it can be configured how much Data Integration Units (DIU) and copy parallelization within a copy activity is used.
Now consider the following extreme situation that the last folder Nk and Mk has 99% of data, see image below:
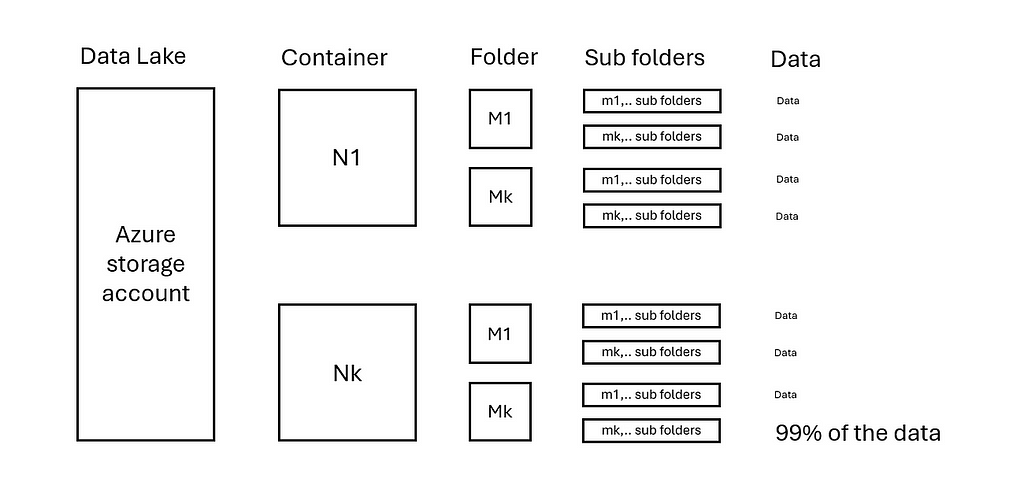
This implies that parallelization shall be done on the sub folders in Nk/Mk where the data is. More advanced logic is then needed to pinpoint the exact data locations. An Azure Function, integrated within ADF, can be used to achieve this. In the next chapter a project is deployed and are the parallelization options discussed in more detail.
3. Parallelization strategy in ADF project
In this part, the project is deployed and a copy test is run and discussed. The entire project can be found in project: https://github.com/rebremer/data-factory-copy-skewed-data-lake.
3.1 Deploy project
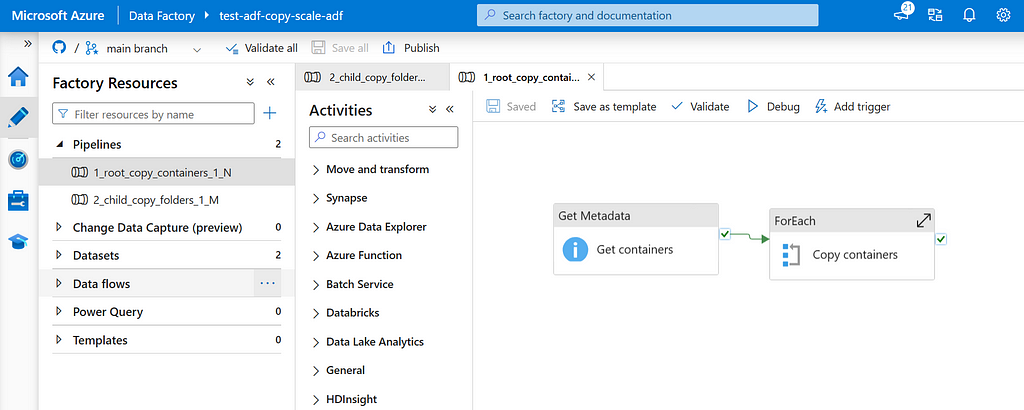
Run the script deploy_adf.ps1. In case ADF is successfully deployed, there are two pipelines deployed:
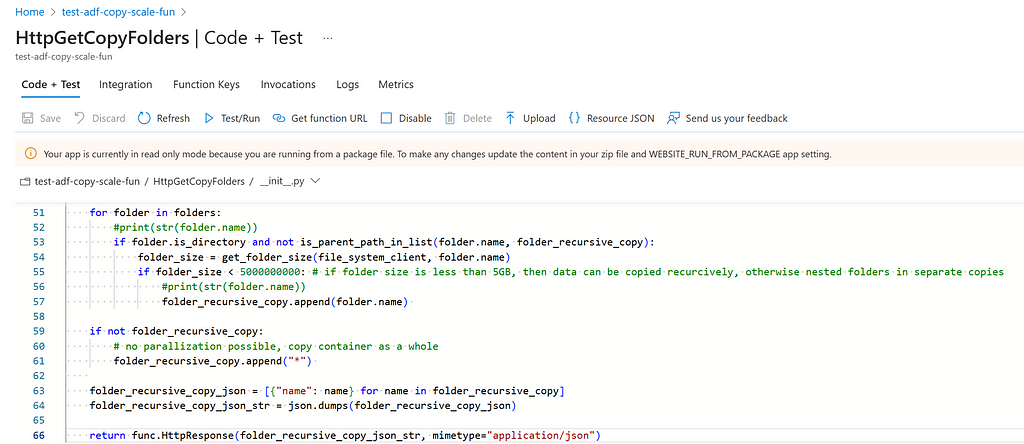
Subsequently, run the script deploy_azurefunction.ps1. In case the Azure Function is successfully deployed, the following code is deployed.
To finally run the project, make sure that the system assigned managed identity of the Azure Function and Data Factory can access the storage account where the data is copied from and to.
3.2 Parallelization used in project
After the project is deployed, it can be noticed that the following tooling is deployed to improve the performance using parallelization.
- Root pipeline: Root pipeline that lists containers N on storage account and triggers child pipeline for each container.
- Child pipeline: Child pipeline that lists folders M in a container and triggers recursive copy activity for each folder.
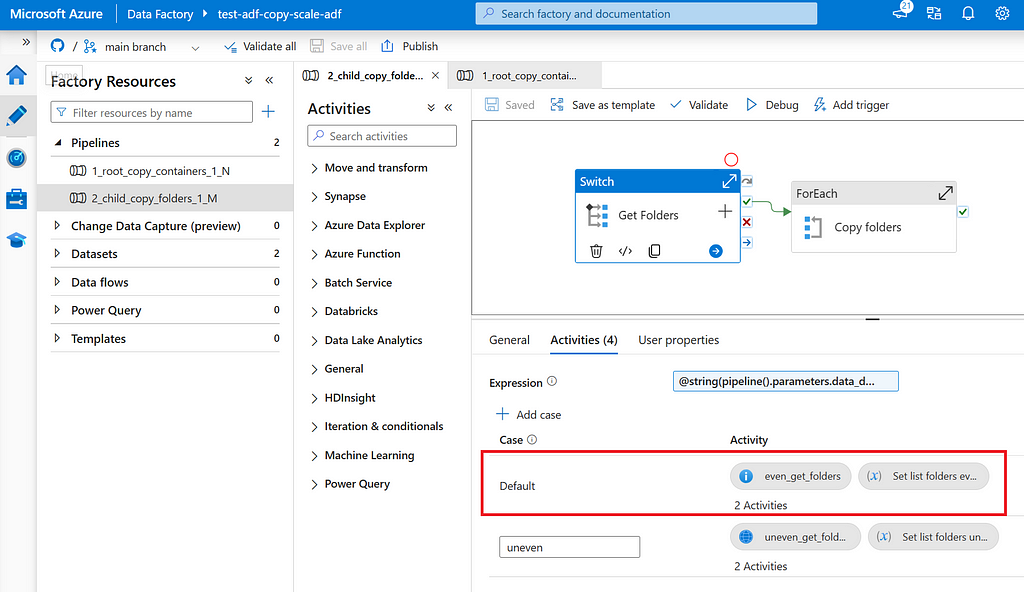
- Switch: Child pipeline uses a switch to decide how list folders shall be determined. For case “default” (even), Get Metadata is used, for case “uneven” an Azure Function is used.
- Get Metadata: List all root folders M in a given container N.
- Azure Function: List all folders and sub folders that contain no more than X GB of data and shall be copied as a whole.
- Copy activity: Recursively copy for all data from a given folder.
- DIU: Number of Data Integration Units per copy activity.
- Copy parallelization: Within a copy activity, number of parallel copy threads that can be started. Each thread can copy a file, maximum of 50 threads.
In the uniformly distributed data lake, data is evenly distributed over N containers and M folders. In this situation, copy activities can just be parallelized on each folder M. This can be done using a Get Meta Data to list folders M, For Each to iterate over folders and copy activity per folder. See also image below.
Using this strategy, this would imply that each copy activity is going to copy an equal amount of data. A total of N*M copy activities will be run.
In the skewed distributed data lake, data is not evenly distributed over N containers and M folders. In this situation, copy activities shall be dynamically determined. This can be done using an Azure Function to list the data heavy folders, then a For Each to iterate over folders and copy activity per folder. See also image below.
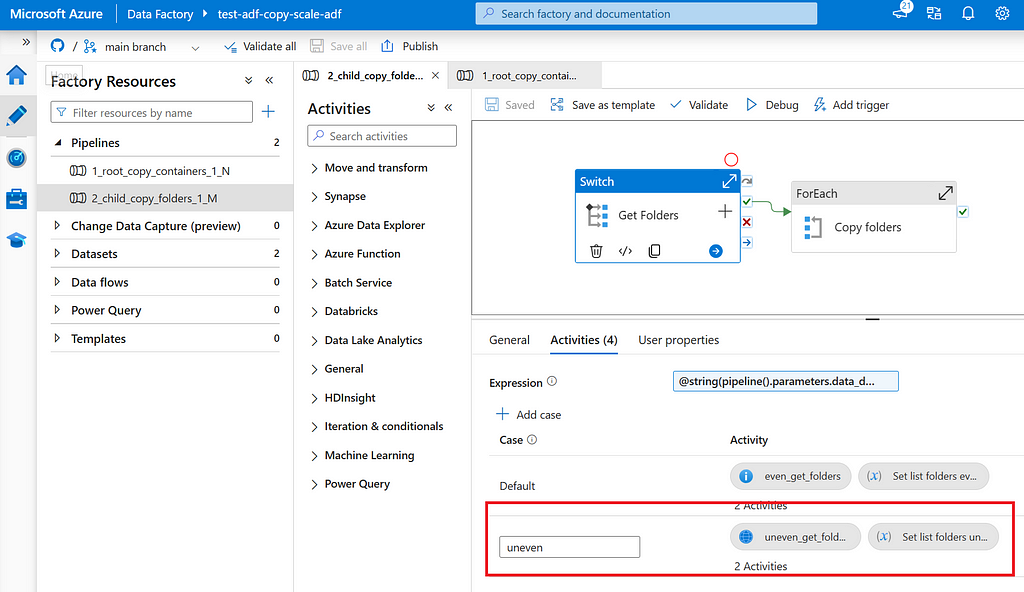
Using this strategy, copy activities are dynamically scaled in data lake where data can be found and parallelization is thus needed most. Although this solution is more complex than the previous solution since it requires an Azure Function, it allows for copying skewed distributed data.
3.3: Parallelization performance test
To compare the performance of different parallelization options, a simple test is set up as follows:
- Two storage accounts and 1 ADF instance using an Azure IR in region westeurope. Data is copied from source to target storage account.
- Source storage account contains three containers with 0.72 TB of data each spread over multiple folders and sub folders.
- Data is evenly distributed over containers, no skewed data.
Test A: Copy 1 container with 1 copy activity using 32 DIU and 16 threads in copy activity (both set to auto) => 0.72 TB of data is copied, 12m27s copy time, average throughput is 0.99 GB/s
Test B: Copy 1 container with 1 copy activity using 128 DIU and 32 threads in copy activity => 0.72 TB of data is copied, 06m19s copy time, average throughput is 1.95 GB/s.
Test C: Copy 1 container with 1 copy activity using 200 DIU and 50 threads (max) => test aborted due to throttling, no performance gain compared to test B.
Test D: Copy 2 containers with 2 copy activities in parallel using 128 DIU and 32 threads for each copy activity => 1.44 TB of data is copied, 07m00s copy time, average throughput is 3.53 GB/s.
Test E: Copy 3 containers with 3 copy activities in parallel using 128 DIU and 32 threads for each copy activity => 2.17 TB of data is copied, 08m07s copy time, average throughput is 4.56 GB/s. See also screenshot below.

In this, it shall be noticed that ADF does not immediately start copying since there is a startup time. For an Azure IR this is ~10 seconds. This startup time is fixed and its impact on throughput can be neglected for large copies. Also, maximum ingress of a storage account is 60 Gbps (=7.5 GB/s). There cannot be scaled above this number, unless additional capacity is requested on the storage account.
The following takeaways can be drawn from the test:
- Significant performance can already be gained by increasing DIU and parallel settings within copy activity.
- By running copy pipelines in parallel, performance can be further increased.
- In this test, data was uniformly distributed across two containers. If the data had been skewed, with all data from container 1 located in a sub folder of container 2, both copy activities would need to target container 2. This ensures similar performance to Test D.
- If the data location is unknown beforehand or deeply nested, an Azure Function would be needed to identify the data pockets to make sure the copy activities run in the right place.
4. Conclusion
Azure Data Factory (ADF) is a popular tool to move data at scale. It is widely used for ingesting, transforming, backing up, and restoring data in Enterprise Data Lakes. Given its role in moving large volumes of data, optimizing copy performance is crucial to minimize throughput time.
In this blog post, we discussed the following parallelization strategies to enhance the performance of data copying to and from Azure Storage.
- Within a copy activity, utilize standard Data Integration Units (DIU) and parallelization threads within a copy activity.
- Run copy activities in parallel. If data is known to be evenly distributed, standard functionality in ADF can be used to parallelize copy activities across each container (N) and root folder (M).
- Run copy activities where the data is. In case this is not known on beforehand or deeply nested, an Azure Function can be leveraged to locate the data. However, incorporating an Azure Function within an ADF pipeline adds complexity and should be avoided when not needed.
Unfortunately, there is no silver bullet solution and it always requires analyses and testing to find the best strategy to improve copy performance for Enterprise Data Lakes. This article aimed to give guidance in choosing the best strategy.
How to Parallelize Copy Activities in Azure Data Factory was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
Originally appeared here:
How to Parallelize Copy Activities in Azure Data Factory
Go Here to Read this Fast! How to Parallelize Copy Activities in Azure Data Factory