

Three architectures discussed and tested to serve delta tables
1. Introduction
Delta tables in a medallion architecture are generally used to create data products. These data products are used for data science, data analytics, and reporting. However, a common question is to also expose data products via REST APIs. The idea is to embed these APIs in web apps with more strict performance requirements. Important questions are as follows:
- Is reading data from delta tables fast enough to serve web apps?
- Is a compute layer needed to make solution more scalable?
- Is a storage layer needed to achieve strict performance requirements?
To deep-dive on these questions, three architectures are evaluated as follows: architecture A — libraries in API, architecture B — compute layer, and architecture C — storage layer. See also image below.
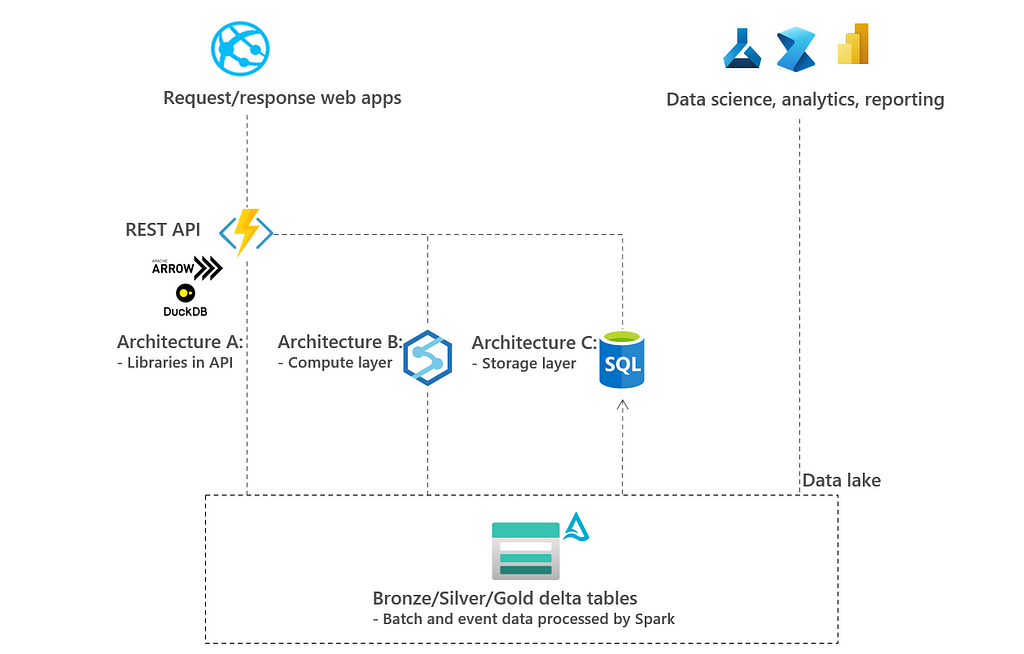
In the remainder of the blog post, the three architectures are described, deployed and tested. Then a conclusion is made.
2. Architecture description
2.1 Architecture A: Libraries in API using DuckDB and PyArrow
In this architecture, APIs are directly connecting to delta tables and there is no compute layer in between. This implies that data is analyzed by using the memory and compute of the API itself. To improve performance, Python libraries of embedded database DuckDB and PyArrow are used. These libraries make sure that only relevant data is loaded (e.g. only columns that are needed by the API).
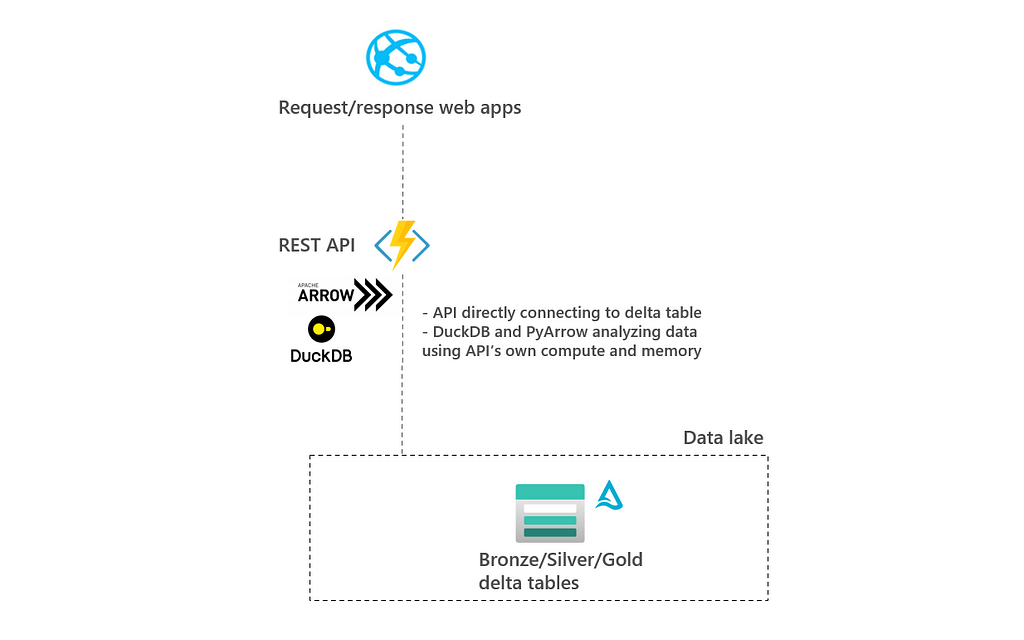
The pro of this architecture is that data does not have to be duplicated and there is no layer needed in between the API and the delta tables. This means less moving parts.
The con of this architecture is that it’s harder to scale and all of the work needs to be done in the compute and memory of the API itself. This is especially challenging if a lot of data needs to be analyzed. This can come from many records, large columns and/or a lot of concurrent requests.
2.2 Architecture B: Compute layer using Synapse, Databricks, or Fabric
In this architecture, APIs are connecting to a compute layer and not directly to the delta tables. This compute layer fetches data from delta tables and then analyzes the data. The compute layer can be Azure Synapse, Azure Databricks, or Microsoft Fabric and typically scales well. The data is not duplicated to the compute layer, though caching can be applied in the compute layer. In the remaining of this blog there is tested with Synapse Serverless.
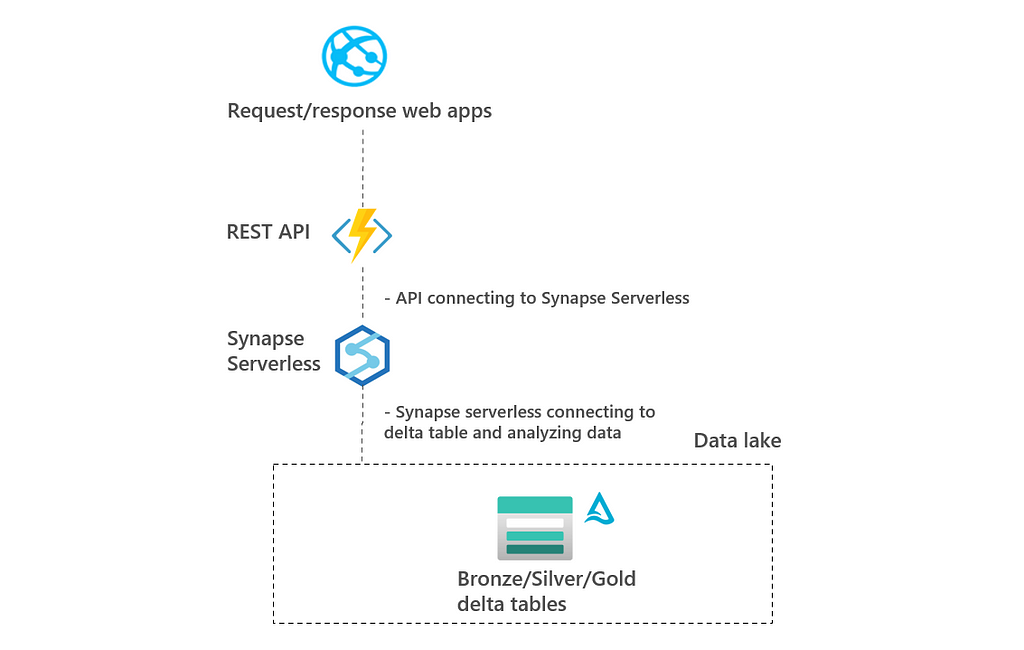
The pro of this architecture is that the data does not have to be duplicated and the architecture scales well. Furthermore, it can be used to crunch large datasets.
The con of this architecture is that an additional layer is needed between the API and the delta tables. This means that more moving parts have to be maintained and secured.
2.3 Architecture C: Optimized storage layer using Azure SQL or Cosmos DB
In this architecture, APIs are not connecting to delta tables, but to a different storage layer in which the delta tables are duplicated. The different storage layer can be Azure SQL or Cosmos DB. The storage layer can be optimized for fast retrieval of data. In the remainder of this blog there is tested with Azure SQL.
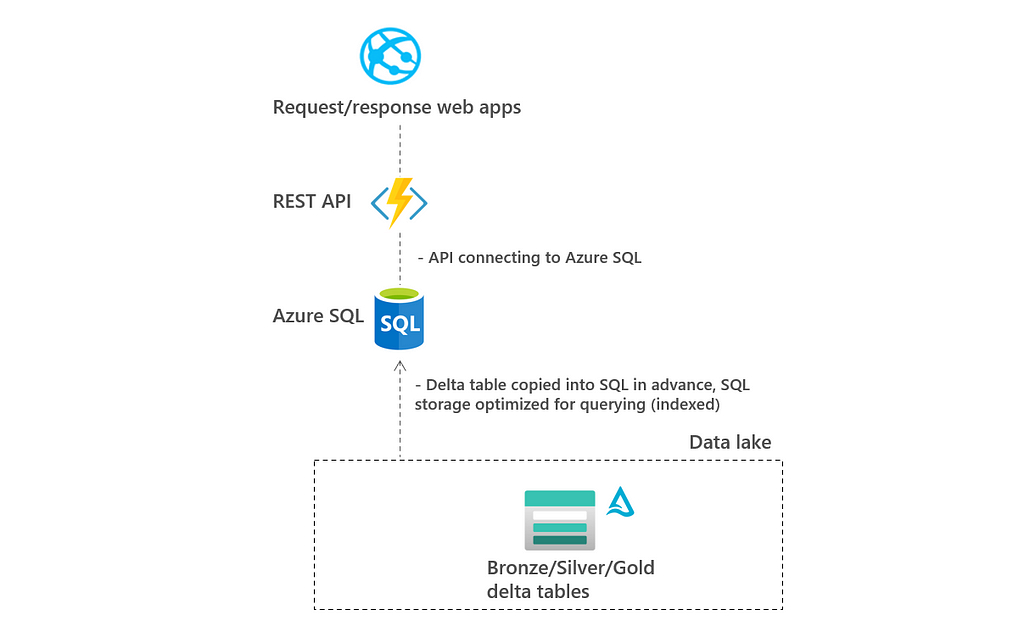
The pro of this architecture is that the storage layer can be optimized to read data fast using indexes, partitioning and materialized views. This is typically a requirement in scenarios of request-response web apps.
The con of this architecture is that data needs to be duplicated and an additional layer is needed between the API and the delta tables. This means that more moving parts need to be maintained and secured.
In the remainder of the blog the architectures are deployed and tested.
3. Deployment and testing of architectures
3.1 Deploying architectures
To deploy the architectures, a GitHub project is created that deploys the three solutions as discussed in the previous chapter. The project can be found in the link below:
https://github.com/rebremer/expose-deltatable-via-restapi
The following will be deployed when the GitHub project is executed:
- A delta table originating from standard test dataset WideWorldImporterdDW full. The test dataset consists of 50M records and 22 columns with 1 large description column.
- All architectures: Azure Function acting as API.
- Architecture B: Synapse Serverless acting as compute layer.
- Architecture C: Azure SQL acting as optimized storage layer.
Once deployed, tests can be executed. The tests are described in the next paragraph.
3.2 Testing architectures
To test the architecture, different types of queries and different scaling will be applied. The different type of queries can be described as follows:
- Look up of 20 records with 11 small columns (char, integer, datetime).
- Look up of 20 records with 2 columns including a large description column that contains more than 500 characters per field.
- Aggregation of data using group by, having, max, average.
The queries are depicted below.
-- Query 1: Point look up 11 columns without large texts
SELECT SaleKey, TaxAmount, CityKey, CustomerKey, BillToCustomerKey, SalespersonKey, DeliveryDateKey, Package
FROM silver_fact_sale
WHERE CityKey=41749 and SalespersonKey=40 and CustomerKey=397 and TaxAmount > 20
-- Query 2: Description column with more than 500 characters
SELECT SaleKey, Description
FROM silver_fact_sale
WHERE CityKey=41749 and SalespersonKey=40 and CustomerKey=397 and TaxAmount > 20
-- Query 3: Aggregation
SELECT MAX(DeliveryDateKey), CityKey, AVG(TaxAmount)
FROM silver_fact_sale
GROUP BY CityKey
HAVING COUNT(CityKey) > 10
The scaling can be described as follows:
- For architecture A, the data processing will be done in the API itself. This means that the compute and memory of the API is used via its app service plan. These will be tested with both SKU Basic (1 core and 1.75 GB memory) and SKU P1V3 SKU (2 cores, 8 GB memory). For architecture B and C, this is not relevant, since the processing is done elsewhere.
- For architecture B, Synapse Serverless is used. Scaling will be done automatically.
- For architecture C, an Azure SQL database of standard tier is taken with 125 DTUs. There will be tested without an index and with an index on CityKey.
In the next paragraph the results are described.
3.3 Results
After deployment and testing the architectures, the results can be obtained. This is a summary of the results:

Architecture A cannot be deployed with SKU B1. In case it is SKU P1V3 is used, then results can be calculated within 15 seconds in case the column size is not too big. Notice that all data is analyzed in the API app service plan. If too much data is loaded (either via many rows, large columns and/or many concurrent requests), this architecture is hard to scale.
Architecture B using Synapse Serverless performs within 10–15 seconds. The compute is done on Synapse Serverless which is scaled automatically to fetch and analyze the data. Performance is consistent for all three types of queries.
Architecture C using Azure SQL performs best when indexes are created. For look up queries 1 and 2, the API responds in around 1 seconds. Query 3 requires a full table scan and there performance is more or less equal to other solutions.
3. Conclusion
Delta tables in a medallion architecture are generally used to create data products. These data products are used for data science, data analytics, and reporting. However, a common question is to also expose delta tables via REST APIs. In this blog post, three architectures are described with its pros and cons.
Architecture A: Libraries in API using DuckDB and PyArrow.
In this architecture, APIs are directly connecting to delta tables and there is no layer in between. This implies that all data is analyzed in memory and compute of the Azure Function.
- The pro of this architecture is that no additional resources are needed. This means less moving parts that need to be maintained and secured.
- The con of this architecture is that it does not scale well since all data needs to be analyzed in the API itself. Therefore, it shall only be used for small amounts of data.
Architecture B: Compute layer using Synapse, Databricks or Fabric.
In this architecture, APIs are connecting to a compute layer. This compute layer fetches and analyzes data from delta tables.
- The pro of this architecture is that it scales well and data is not duplicated. It works well for queries that do aggregations and crunch large datasets.
- The con of this architecture is that it is not possible to get responses within 5 seconds for look up queries consistently. Also, additional resources need to be secured and maintained.
Architecture C: Optimized storage layer using Azure SQL or Cosmos DB.
In this architecture, APIs are connecting to an optimized storage layer. Delta tables are duplicated to this storage layer in advance and the storage layer is used to fetch and analyze the data.
- The pro of this architecture is that it can be optimized for fast querying of look ups using indexes, partitioning, materialized views. This is often a requirement for request-response web apps.
- The con of this architecture is that data is duplicated to a different storage layer, which needs to be kept in sync. Also, additional resources need to be secured and maintained.
Unfortunately, there is no silver bullet solution. This article aimed to give guidance in choosing the best architecture to expose delta tables via REST APIs.
How to Expose Delta Tables via REST APIs was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
Originally appeared here:
How to Expose Delta Tables via REST APIs
Go Here to Read this Fast! How to Expose Delta Tables via REST APIs