Key metrics to optimize your search engine

Table of Contents
- Introduction
- Precision@K
- Mean Average Precision (MAP)
- Mean Reciprocal Rank (MRR)
- Normalized Discounted Cumulative Gain (NDCG)
- Comparative Analysis
- Summary
- References
Disclaimer: The views expressed here are my own and do not necessarily reflect the views of my employer or any other organization. All images are by the author, except where indicated.
1. Introduction
Ensuring users find the information they need quickly and efficiently is paramount to a successful search experience. When users find what they’re looking for quickly and effortlessly, it translates into a positive experience.
Furthermore, the ranking position of relevant results also plays a crucial role — the higher they appear, the more valuable they are to the user. This translates to increased user engagement, conversions, and overall website satisfaction.
This article explores the key metrics used for evaluating Search Relevance and Ranking, empowering you to optimize your Search Engine and deliver a superior user experience.
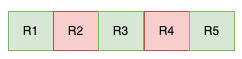
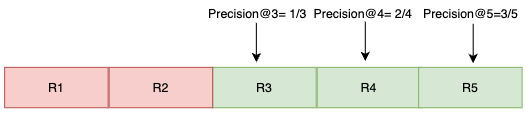
To demonstrate the concept of Search Relevance in a practical way, let’s consider a user searching for “pasta dishes” on a search engine. For simplicity, we’ll analyze the top five results returned by the engine. Relevant results will be denoted in green, while those deemed irrelevant will be highlighted in red (refer to Figure 1). We’ll use the Rn notation to represent the nth result.
2. Precision@K
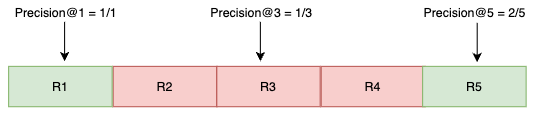
Precision@K measures how many results within the top K positions are relevant. We compute Precision for different values of K, as shown in Figure 2.
Precision@K = Number of relevant results within the top K positions / K
Precision@1 = 1/1
Precision@3 = 1/3
Precision@5 = 2/5
3. Mean Average Precision (MAP)
MAP considers the ranking order of relevant results.
Firstly, Precision@K is calculated for each of these relevant result positions. Then the Average Precision@K is obtained by summing up the Precision@K for each of these relevant result positions and dividing by the total number of relevant items in the top K results. For brevity, we will occasionally refer to Average Precision as AP in the discussion.
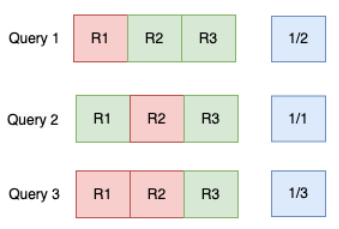
To gain a deeper understanding of how MAP evaluates ranking effectiveness, let’s explore illustrative examples across three distinct search queries. These examples will highlight how the order in which results are presented influences the MAP score.
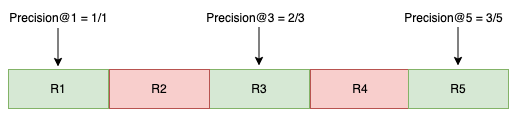
AP@5_Query_1 = (Precision@1 + Precision@3 + Precision@5) / 3
AP@5_Query_1 = (1 + 0.67 + 0.6) / 3 = 0.76
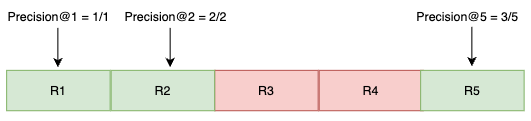
AP@5_Query_2 = (Precision@1 + Precision@2 + Precision@5) / 3
AP@5_Query_2 = (1 + 1 + 0.6) / 3 = 0.87
AP@5_Query_3 = (Precision@3 + Precision@4 + Precision@5) / 3
AP@5_Query_3 = (0.33 + 0.5 + 0.6) / 3 = 0.47
The results for Query 2 exhibit the highest Average Precision@5, indicating that the most relevant items are positioned at the beginning of the ranked list.
MAP = Mean of Average Precision across all queries in the dataset.
MAP@5 = (AP@5_Query_1 + AP@5_Query_2 + AP@5_Query_3) / Number of queries
MAP@5 of the dataset = (0.76 + 0.87 + 0.47) / 3 = 0.7
This calculation treats all queries as equally important. However, if some queries are more critical, different weighting methods can be used within the MAP process to prioritize them.
4. Mean Reciprocal Rank (MRR)
MRR considers only the rank of the first relevant result found in the list.
K = Rank of first relevant result
Reciprocal Score = 1 / K
MRR is the average reciprocal score across multiple queries. If there is no relevant result, then the rank of the first relevant result is considered to be infinity. Therefore, the reciprocal score becomes 0.
The reciprocal score of a relevant result is an inverse function of its rank.
MRR of the dataset = (0.5 + 1 + 0.33) / 3 = 0.61
5. Normalized Discounted Cumulative Gain (NDCG)
NDCG takes into account the graded relevance of results. The relevance of each result is represented by a score (also known as a “grade”). The value of NDCG is determined by comparing the relevance of the results returned by a search engine to the relevance of the results that a hypothetical “ideal” search engine would return.
Let’s assume we’ve got a relevance/grading scale of 1–5, with 5 being the highest score and 1 being the lowest score. We search for “pasta dishes” and manually grade the search results by providing them with a relevance score, as shown in Figure 7. In our example, R3 is the most relevant result, with a score of 5.

Cumulative Gain@5 = 4 + 1 + 5 + 1 + 3 = 14
Cumulative gain does not take ranking into consideration.
Discounted Cumulative Gain@K = A logarithmic discount is applied that helps assign lower gain when relevant items appear further down in the ranked list, as shown in Figure 8.
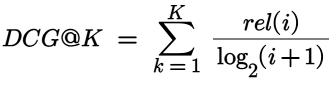
Where rel(i) is the relevance score of the result at position i.
DCG@K = 4/1 + 1/1.585 + 5/2 + 1/2.322+ 3/2.585 = 8.72
The absolute value of DCG depend on the number of results in the list and the relevance scores assigned. In order to address this, DCG can be normalized. To get the normalized DCG (NDCG), we divide the DCG by the ideal DCG (IDCG) for the given result set, as shown in Figure 9. IDCG considers the same relevance scores, but calculates the DCG assuming the absolute best ranking order for those results. The best ranking order for the above example would be: R3 → R1 → R5 → R2 → R4.
IDCG@K = 5/1 + 4/1.585 + 3/2 + 1/2.322 + 1/2.585 = 9.83
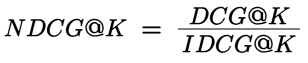
NDCG@K = 8.72/9.83 = 0.88
NDCG accounts for the graded relevance of results, providing a more nuanced understanding of Search Ranking Quality.
6. Comparative Analysis
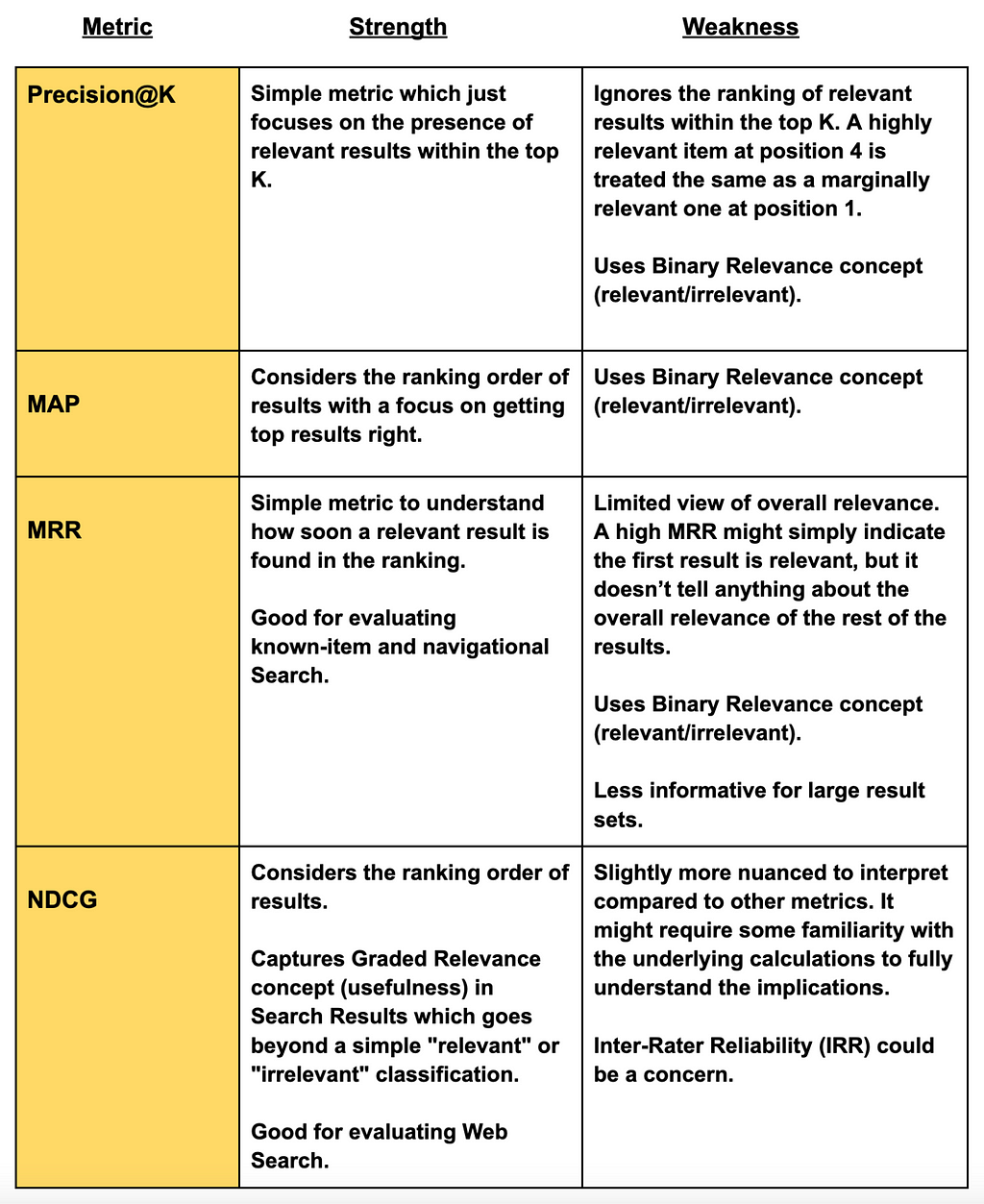
In addition to the above metrics, the Spearman Correlation Coefficient and Kendall Tau Distance can be employed to assess the similarity of ranked lists. For measuring user engagements, Click-Through Rate (CTR) is a key metric that reflects the percentage of users who have clicked on a result after it’s displayed. For more information on these metrics, please consult the Wikipedia resources listed in the References section.
7. Summary

Following our exploration of four distinct metrics for search quality evaluation, we conducted a comparative analysis to understand the strengths and weaknesses of each approach. This naturally leads us to the critical question: Which metric is most suitable for evaluating the Relevance and Ranking of your Search Engine Results? The optimal metric selection depends on your specific requirements.
For a comprehensive understanding of the quality of your Search Engine, it is often beneficial to consider a combination of these metrics rather than relying on a single measure.
8. References:
- https://en.wikipedia.org/wiki/Evaluation_measures_(information_retrieval)
- https://en.wikipedia.org/wiki/Mean_reciprocal_rank
- https://en.wikipedia.org/wiki/Kendall_tau_distance
- https://en.wikipedia.org/wiki/Discounted_cumulative_gain
- https://en.wikipedia.org/wiki/Spearman%27s_rank_correlation_coefficient
- https://web.stanford.edu/class/cs276/handouts/EvaluationNew-handout-6-per.pdf
- https://www.coursera.org/lecture/recommender-metrics/rank-aware-top-n-metrics-Wk98r
- https://www.evidentlyai.com/ranking-metrics/ndcg-metric
- https://en.wikipedia.org/wiki/Inter-rater_reliability
- https://en.wikipedia.org/wiki/Click-through_rate
How to Evaluate Search Relevance and Ranking was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
Originally appeared here:
How to Evaluate Search Relevance and Ranking
Go Here to Read this Fast! How to Evaluate Search Relevance and Ranking