Nikola Milosevic (Data Warrior)
An open-source initiative to help you deploy generative search based on your local files and self-hosted (Mistral, Llama 3.x) or commercial LLM models (GPT4, GPT4o, etc.)
I have previously written about building your own simple generative search, as well as on the VerifAI project on Towards Data Science. However, there has been a major update worth revisiting. Initially, VerifAI was developed as a biomedical generative search with referenced and AI-verified answers. This version is still available, and we now call it VerifAI BioMed. It can be accessed here: https://app.verifai-project.com/.
The major update, however, is that you can now index your local files and turn them into your own generative search engine (or productivity engine, as some refer to these systems based on GenAI). It can serve also as an enterprise or organizational generative search. We call this version VerifAI Core, as it serves as the foundation for the other version. In this article, we will explore how you can in a few simple steps, deploy it and start using it. Given that it has been written in Python, it can be run on any kind of operating system.
Architecture
The best way to describe a generative search engine is by breaking it down into three parts (or components, in our case):
- Indexing
- Retrieval-Augmented Generation (RAG) Method
- VerifAI contains an additional component, which is a verification engine, on top of the usual generative search capabilities
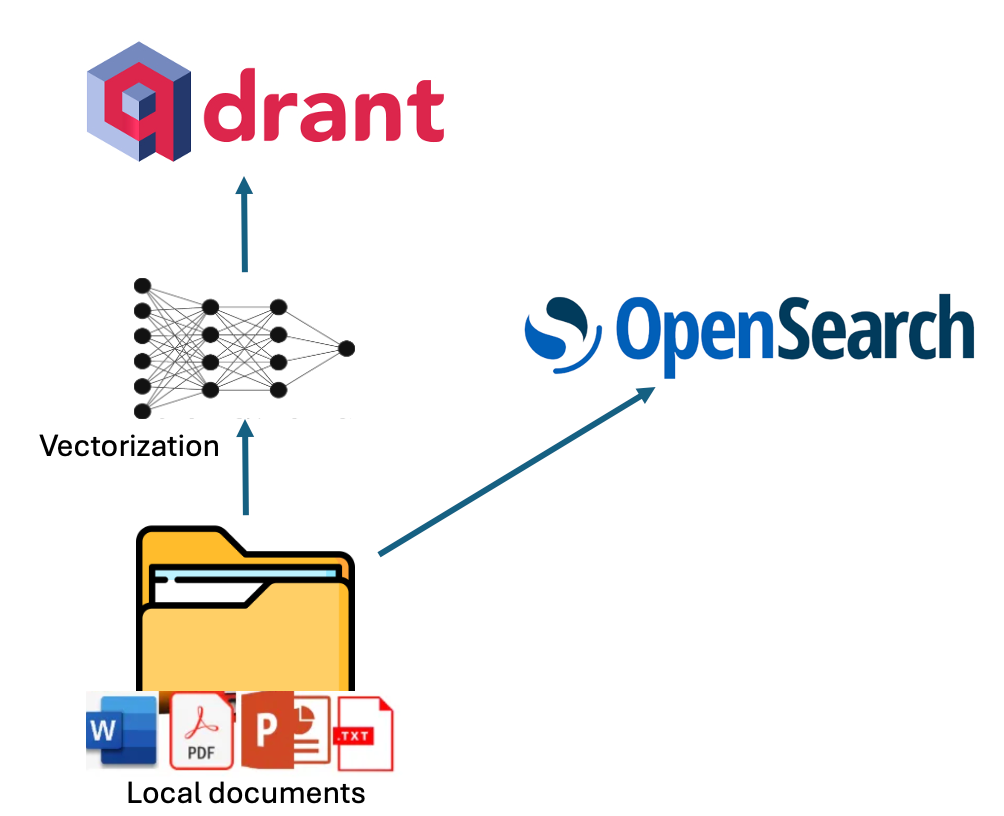
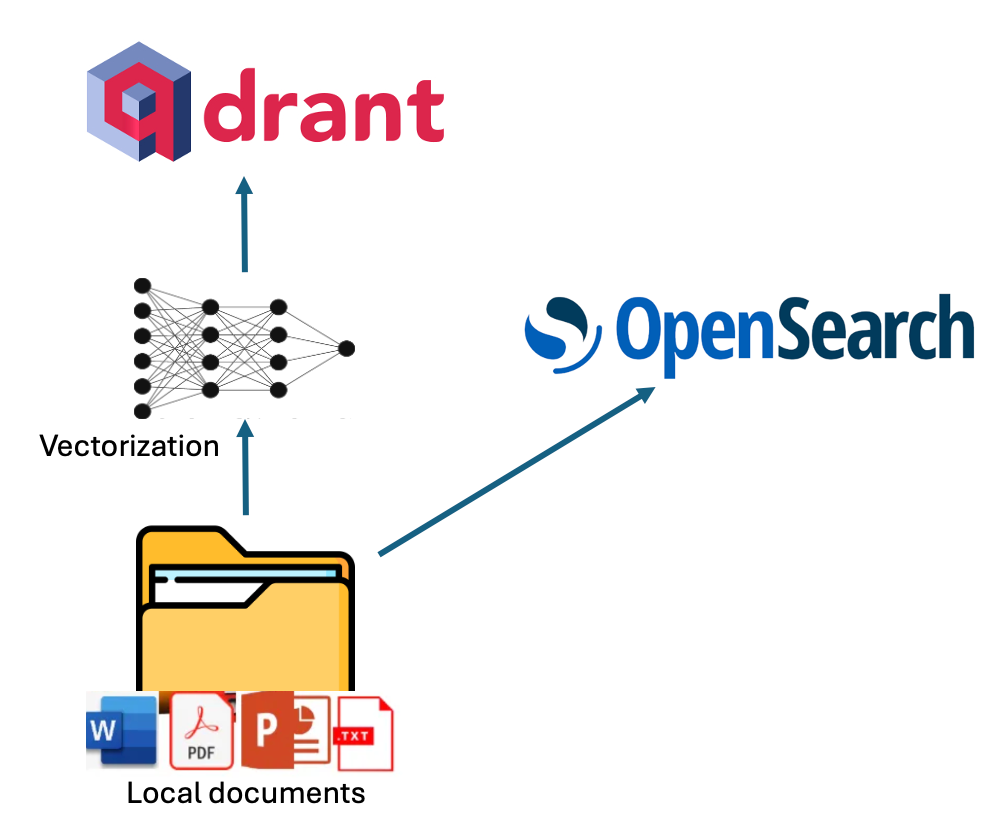
Indexing in VerifAI can be done by pointing its indexer script to a local folder containing files such as PDF, MS Word, PowerPoint, Text, or Markdown (.md). The script reads and indexes these files. Indexing is performed in dual mode, utilizing both lexical and semantic indexing.
For lexical indexing, VerifAI uses OpenSearch. For semantic indexing, it vectorizes chunks of the documents using an embedding model specified in the configuration file (models from Hugging Face are supported) and then stores these vectors in Qdrant. A visual representation of this process is shown in the diagram below.
When it comes to answering questions using VerifAI, the method is somewhat complex. User questions, written in natural language, undergo preprocessing (e.g., stopwords are excluded) and are then transformed into queries.
For OpenSearch, only lexical processing is performed (e.g., excluding stopwords), and the most relevant documents are retrieved. For Qdrant, the query is transformed into embeddings using the same model that was used to embed document chunks when they were stored in Qdrant. These embeddings are then used to query Qdrant, retrieving the most similar documents based on dot product similarity. The dot product is employed because it accounts for both the angle and magnitude of the vectors.
Finally, the results from the two engines must be merged. This is done by normalizing the retrieval scores from each engine to values between 0 and 1 (achieved by dividing each score by the highest score from its respective engine). Scores corresponding to the same document are then added together and sorted by their combined score in descending order.
Using the retrieved documents, a prompt is built. The prompt contains instructions, the top documents, and the user’s question. This prompt is then passed to the large language model of choice (which can be specified in the configuration file, or, if no model is set, defaults to our locally deployed fine-tuned version of Mistral). Finally, a verification model is applied to ensure there are no hallucinations, and the answer is presented to the user through the GUI. The schematic of this process is shown in the image below.

Installing the necessary libraries
To install VerifAI Generative Search, you can start by cloning the latest codebase from GitHub or using one of the available releases.
git clone https://github.com/nikolamilosevic86/verifAI.git
When installing VerifAI Search, it is recommended to start by creating a clean Python environment. I have tested it with Python 3.6, but it should work with most Python 3 versions. However, Python 3.10+ may encounter compatibility issues with certain dependencies.
To create a Python environment, you can use the venv library as follows:
python -m venv verifai
source verifai/bin/activate
After activating the environment, you can install the required libraries. The requirements file is located in the verifAI/backend directory. You can run the following command to install all the dependencies:
pip install -r requirements.txt
Configuring system
The next step is configuring VerifAI and its interactions with other tools. This can be done either by setting environment variables directly or by using an environment file (the preferred option).
An example of an environment file for VerifAI is provided in the backend folder as .env.local.example. You can rename this file to .env, and the VerifAI backend will automatically read it. The file structure is as follows:
SECRET_KEY=6293db7b3f4f67439ad61d1b798242b035ee36c4113bf870
ALGORITHM=HS256
DBNAME=verifai_database
USER_DB=myuser
PASSWORD_DB=mypassword
HOST_DB=localhost
OPENSEARCH_IP=localhost
OPENSEARCH_USER=admin
OPENSEARCH_PASSWORD=admin
OPENSEARCH_PORT=9200
OPENSEARCH_USE_SSL=False
QDRANT_IP=localhost
QDRANT_PORT=6333
QDRANT_API=8da7625d78141e19a9bf3d878f4cb333fedb56eed9097904b46ce4c33e1ce085
QDRANT_USE_SSL=False
OPENAI_PATH=<model-deployment-path>
OPENAI_KEY=<model-deployment-key>
OPENAI_DEPLOYMENT_NAME=<name-of-model-deployment>
MAX_CONTEXT_LENGTH=128000
USE_VERIFICATION = True
EMBEDDING_MODEL="sentence-transformers/msmarco-bert-base-dot-v5"
INDEX_NAME_LEXICAL = 'myindex-lexical'
INDEX_NAME_SEMANTIC = "myindex-semantic"
Some of the variables are quite straightforward. The first Secret key and Algorithm are used for communication between the frontend and the backend.
Then there are variables configuring access to the PostgreSQL database. It needs the database name (DBNAME), username, password, and host address where the database is located. In our case, it is on localhost, on the docker image.
The next section is the configuration of OpenSearch access. There is IP (localhost in our case again), username, password, port number (default port is 9200), and variable defining whether to use SSL.
A similar configuration section has Qdrant, just for Qdrant, we use an API key, which has to be here defined.
The next section defined the generative model. VerifAI uses the OpenAI python library, which became the industry standard, and allows it to use both OpenAI API, Azure API, and user deployments via vLLM, OLlama, or Nvidia NIMs. The user needs to define the path to the interface, API key, and model deployment name that will be used. We are soon adding support where users can modify or change the prompt that is used for generation. In case no path to an interface is provided and no key, the model will download the Mistral 7B model, with the QLoRA adapter that we have fine-tuned, and deploy it locally. However, in case you do not have enough GPU RAM, or RAM in general, this may fail, or work terribly slowly.
You can set also MAX_CONTEXT_LENGTH, in this case it is set to 128,000 tokens, as that is context size of GPT4o. The context length variable is used to build context. Generally, it is built by putting in instruction about answering question factually, with references, and then providing retrieved relevant documents and question. However, documents can be large, and exceed context length. If this happens, the documents are splitted in chunks and top n chunks that fit into the context size will be used to context.
The next part contains the HuggingFace name of the model that is used for embeddings of documents in Qdrant. Finally, there are names of indexes both in OpenSearch (INDEX_NAME_LEXICAL) and Qdrant (INDEX_NAME_SEMANTIC).
As we previously said, VerifAI has a component that verifies whether the generated claim is based on the provided and referenced document. However, this can be turned on or off, as for some use-cases this functionality is not needed. One can turn this off by setting USE_VERIFICATION to False.
Installing datastores
The final step of the installation is to run the install_datastores.py file. Before running this file, you need to install Docker and ensure that the Docker daemon is running. As this file reads configuration for setting up the user names, passwords, or API keys for the tools it is installing, it is necessary to first make a configuration file. This is explained in the next section.
This script sets up the necessary components, including OpenSearch, Qdrant, and PostgreSQL, and creates a database in PostgreSQL.
python install_datastores.py
Note that this script installs Qdrant and OpenSearch without SSL certificates, and the following instructions assume SSL is not required. If you need SSL for a production environment, you will need to configure it manually.
Also, note that we are talking about local installation on docker here. If you already have Qdrant and OpenSearch deployed, you can simply update the configuration file to point to those instances.
Indexing files
This configuration is used by both the indexing method and the backend service. Therefore, it must be completed before indexing. Once the configuration is set up, you can run the indexing process by pointing index_files.py to the folder containing the files to be indexed:
python index_files.py <path-to-directory-with-files>
We have included a folder called test_data in the repository, which contains several test files (primarily my papers and other past writings). You can replace these files with your own and run the following:
python index_files.py test_data
This would run indexing over all files in that folder and its subfolders. Once finished, one can run VerifAI services for backend and frontend.
Running the generative search
The backend of VerifAI can be run simply by running:
python main.py
This will start the FastAPI service that would act as a backend, and pass requests to OpenSearch, and Qdrant to retrieve relevant files for given queries and to the deployment of LLM for generating answers, as well as utilize the local model for claim verification.
Frontend is a folder called client-gui/verifai-ui and is written in React.js, and therefore would need a local installation of Node.js, and npm. Then you can simply install dependencies by running npm install and run the front end by running npm start:
cd ..
cd client-gui/verifai-ui
npm install
npm start
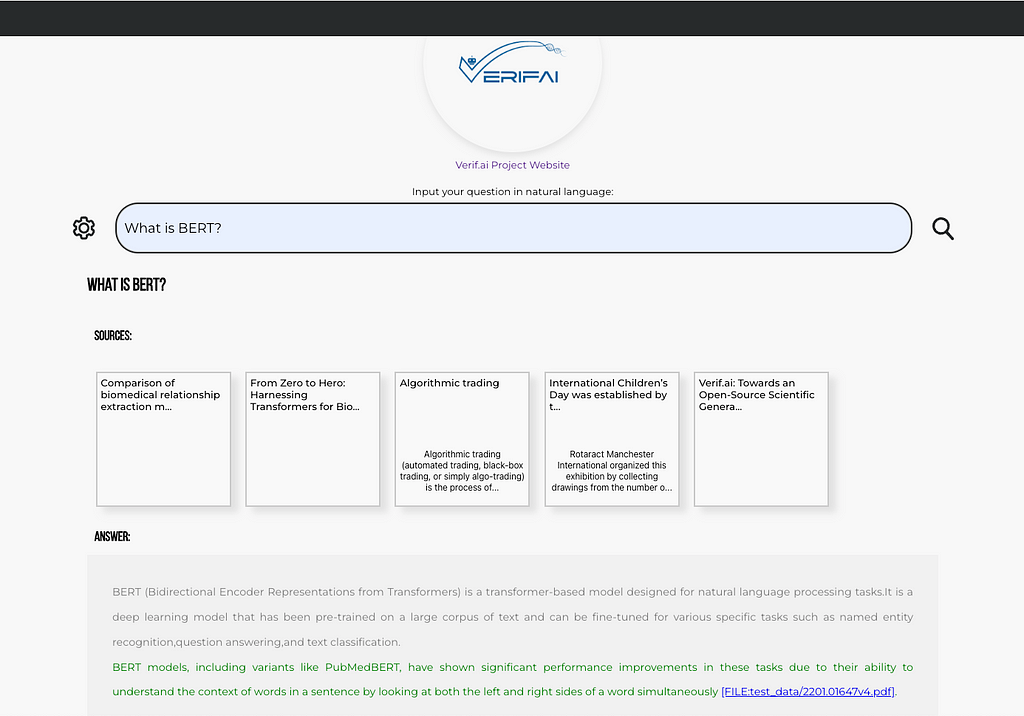
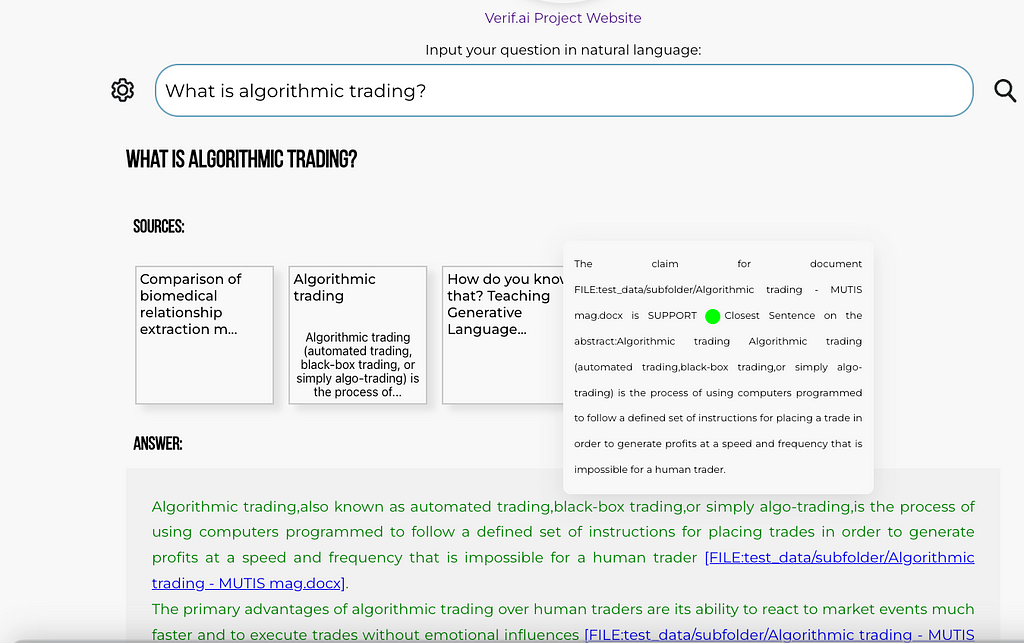
Finally, things should look somehow like this:
Contributing and future direction
So far, VerifAI has been started with the help of funding from the Next Generation Internet Search project as a subgrant of the European Union. It was started as a collaboration between The Institute for Artificial Intelligence Research and Development of Serbia and Bayer A.G.. The first version has been developed as a generative search engine for biomedicine. This product will continue to run at https://app.verifai-project.com/. However, lately, we decided to expand the project, so it can truly become an open-source generative search with verifiable answers for any files, that can be leveraged openly by different enterprises, small and medium companies, non-governmental organizations, or governments. These modifications have been developed by Natasa Radmilovic and me voluntarily (huge shout out to Natasa!).
However, given this is an open-source project, available on GitHub (https://github.com/nikolamilosevic86/verifAI), we are welcoming contributions by anyone, via pull requests, bug reports, feature requests, discussions, or anything else you can contribute with (feel free to get in touch — for both BioMed and Core (document generative search, as described here) versions website will remain the same — https://verifai-project.com). So we welcome you to contribute, start our project, and follow us in the future.
How to Easily Deploy a Local Generative Search Engine Using VerifAI was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
Originally appeared here:
How to Easily Deploy a Local Generative Search Engine Using VerifAI
Go Here to Read this Fast! How to Easily Deploy a Local Generative Search Engine Using VerifAI