

How to Create an LLM-Powered app to Convert Text to Presentation Slides: GenSlide — A Step-by-step Guide
In this post, I am going to share how you can create a simple yet powerful application that uses LLMs to convert your written content into concise PowerPoint slides. The good part: You even run your own LLM service, so
- you keep your data private, and
- no cost to call LLM APIs.
Getting Started
Reaching the power of GenSlide is straightforward. Follow these steps to set up and run this tool on your machine.
Step 1: Create project folder
Begin by creating the project folder in your local machine:
mkdir GenSlide
After completing all the steps, the final file structure would look like this:
GenSlide
├── frontend
│ ├── llm_call.py
│ ├── slide_deck.py
│ ├── slide_gen.py
│ └── ui.py
├── llm-service
│ ├── consts.py
│ └── gpt.py
└── requirements.txt
The first file we create contains packages list. Create a file named requirements.txt. Add the following package dependencies to the file.
pillow==10.3.0
lxml==5.2.2
XlsxWriter==3.2.0
python-pptx==0.6.23
gpt4all==2.7.0
Flask==2.2.5
Flask-Cors==4.0.0
streamlit==1.34.0
Specifically, we’re leveraging the gpt4all package to run a large language model (LLM) server on a local machine. To dive deeper into gpt4all, refer to their official documentation.
We also use streamlit package to create the user interface.
Step 2: Setting Up the Environment
Next, create a virtual environment and install the necessary packages:
python -m venv ./venv
source ./venv/bin/activate
pip install -r requirements.txt
Note: Ensure that you are using a Python version other than 3.9.7, as streamlit is incompatible with that version. For this tutorial I used Python version 3.12.
Step 3: Implement LLM Service
Our LLM service should be able to receive a text as input and generate a summary of the key points of the text as output. It should organize the output in a list of JSON objects. We’ll specify these details in the prompt definition. Let’s first create a folder for LLM service.
mkdir llm-service
We arrange the implementation into two .py files in this folder.
- consts.py
Here we need to define the name of LLM model we want to use. You can see the list of models that can be used here: https://docs.gpt4all.io/gpt4all_python/home.html#load-llm. Meta’s Llama model performs good for this task.
LLM_MODEL_NAME = "Meta-Llama-3-8B-Instruct.Q4_0.gguf"
We also define the prompt message here that includes the instructions to the LLM as well as some examples of the desired output. We ask the output to be in JSON format, so it would be easier for us to process and create a presentation.
PROMPT = """
Summarize the input text and arrange it in an array of JSON objects to to be suitable for a powerpoint presentation.
Determine the needed number of json objects (slides) based on the length of the text.
Each key point in a slide should be limited to up to 10 words.
Consider maximum of 5 bullet points per slide.
Return the response as an array of json objects.
The first item in the list must be a json object for the title slide.
This is a sample of such json object:
{
"id": 1,
"title_text": "My Presentation Title",
"subtitle_text": "My presentation subtitle",
"is_title_slide": "yes"
}
And here is the sample of json data for slides:
{"id": 2, title_text": "Slide 1 Title", "text": ["Bullet 1", "Bullet 2"]},
{"id": 3, title_text": "Slide 2 Title", "text": ["Bullet 1", "Bullet 2", "Bullet 3"]}
Please make sure the json object is correct and valid.
Don't output explanation. I just need the JSON array as your output.
"""
2. gpt.py
Here we want to create a Flask application that receives HTTP POST requests from the clients and call the LLM model to extract the summary in a JSON representation.
First things first; import dependencies.
from flask import Flask, request
from flask_cors import CORS
import traceback
import logging
import os
from consts import LLM_MODEL_NAME, PROMPT
from gpt4all import GPT4All
Define the host IP, port, Flask app and allow Cross-Origin Resource Sharing.
logger = logging.getLogger()
HOST = '0.0.0.0'
PORT = 8081
app = Flask(__name__)
CORS(app)
Define a base folder to store the LLM model. Here with “MODEL_PATH” environment variable we overwrite the default location of models set by gpt4all. Now the models will be stored in the project folder under “gpt_models/gpt4all/”. When GPT4All class is instantiated for the first time, it will look for the model_name in the model_path (it’s argument), if not found, will look into MODEL_PATH. If not found, it will start to download the model.
try:
base_folder = os.path.dirname(__file__)
base_folder = os.path.dirname(base_folder)
gpt_models_folder = os.path.join(base_folder, "gpt_models/gpt4all/")
if not os.path.exists(gpt_models_folder):
os.makedirs(gpt_models_folder, exist_ok=True)
model_folder = os.environ.get("MODEL_PATH", gpt_models_folder)
llm_model = GPT4All(model_name=LLM_MODEL_NAME, model_path=model_folder)
except Exception:
raise ValueError("Error loading LLM model.")
Define a function to call the generate() function of the LLM model and return the response. We may set optional parameters such as temperature and max_tokens.
def generate_text(content):
prompt = PROMPT + f"n{content}"
with llm_model.chat_session():
output = llm_model.generate(prompt, temp=0.7, max_tokens=1024)
output = output.strip()
return output
Define a POST API to receive clients’ requests. Requests come in the form of JSON objects {“content”:”…”}. We will use this “content” value and call the generate_text() method defined above. If everything goes well, we send the output along with an 200 HTTP (OK) status code. Otherwise an “Error” message and status code 500 is returned.
@app.route('/api/completion', methods=['POST'])
def completion():
try:
req = request.get_json()
words = req.get('content')
if not words:
raise ValueError("No input word.")
output = generate_text(words)
return output, 200
except Exception:
logger.error(traceback.format_exc())
return "Error", 500
Run the Flask app.
if __name__ == '__main__':
# run web server
app.run(host=HOST,
debug=True, # automatic reloading enabled
port=PORT)
Step 4: Implement front end
Frontend is where we get the user’s input and interact with the LLM service and finally create the PowerPoint slides.
Inside the project folder, create a folder named frontend.
mkdir frontend
The implementation falls into 4 Python files.
- llm_call.py
This would be where we send the POST requests to the LLM server. We set our LLM server on localhost port 8081. We enclose the input text into a JSON object with the key “content”. The output of the call should be a JSON string.
import requests
URL = "http://127.0.0.1:8081"
CHAT_API_ENDPOINT = f"{URL}/api/completion"
def chat_completion_request(content):
headers = {'Content-type': 'application/json'}
data = {'content': content}
req = requests.post(url=CHAT_API_ENDPOINT, headers=headers, json=data)
json_extracted = req.text
return json_extracted
2. slide_deck.py
Here we use pptx package to create PowerPoint slides. The list of JSON objects contains the information to add slides to the presentation. For detailed information about pptx package refer to their documentation.
import os
from pptx import Presentation
from pptx.util import Inches
class SlideDeck:
def __init__(self, output_folder="generated"):
self.prs = Presentation()
self.output_folder = output_folder
def add_slide(self, slide_data):
prs = self.prs
bullet_slide_layout = prs.slide_layouts[1]
slide = prs.slides.add_slide(bullet_slide_layout)
shapes = slide.shapes
# Title
title_shape = shapes.title
title_shape.text = slide_data.get("title_text", "")
# Body
if "text" in slide_data:
body_shape = shapes.placeholders[1]
tf = body_shape.text_frame
for bullet in slide_data.get("text", []):
p = tf.add_paragraph()
p.text = bullet
p.level = 0
if "p1" in slide_data:
p = tf.add_paragraph()
p.text = slide_data.get("p1")
p.level = 1
if "img_path" in slide_data:
cur_left = 6
for img_path in slide_data.get("img_path", []):
top = Inches(2)
left = Inches(cur_left)
height = Inches(4)
pic = slide.shapes.add_picture(img_path, left, top, height=height)
cur_left += 1
def add_title_slide(self, title_page_data):
# title slide
prs = self.prs
title_slide_layout = prs.slide_layouts[0]
slide = prs.slides.add_slide(title_slide_layout)
title = slide.shapes.title
subtitle = slide.placeholders[1]
if "title_text" in title_page_data:
title.text = title_page_data.get("title_text")
if "subtitle_text" in title_page_data:
subtitle.text = title_page_data.get("subtitle_text")
def create_presentation(self, title_slide_info, slide_pages_data=[]):
try:
file_name = title_slide_info.get("title_text").
lower().replace(",", "").replace(" ", "-")
file_name += ".pptx"
file_name = os.path.join(self.output_folder, file_name)
self.add_title_slide(title_slide_info)
for slide_data in slide_pages_data:
self.add_slide(slide_data)
self.prs.save(file_name)
return file_name
except Exception as e:
raise e
3. slide_gen.py
Let’s break it into smaller snippets.
Here, after importing necessary packages, create a folder to store the generated .pptx files.
import json
import os
from slide_deck import SlideDeck
from llm_call import chat_completion_request
FOLDER = "generated"
if not os.path.exists(FOLDER):
os.makedirs(FOLDER)
Then define these two methods:
- A method to invoke chat_completion_request and send the request to the LLM and parse the JSON string,
- A method that gets the output of previous method and instantiate a SlideDeck to fill in the PowerPoint slides.
def generate_json_list_of_slides(content):
try:
resp = chat_completion_request(content)
obj = json.loads(resp)
return obj
except Exception as e:
raise e
def generate_presentation(content):
deck = SlideDeck()
slides_data = generate_json_list_of_slides(content)
title_slide_data = slides_data[0]
slides_data = slides_data[1:]
return deck.create_presentation(title_slide_data, slides_data)
4. ui.py
We create a simple UI with an input text box. User can type in or copy/paste their text there and hit enter to start the slide generation. Upon completion of slide generation, a message is printed at the end of input text box. streamlit is very handy here.
import traceback
import streamlit as st
from slide_gen import generate_presentation
def create_ui():
st.write("""
# Gen Slides
### Generating powerpoint slides for your text
""")
content = st.text_area(label="Enter your text:", height=400)
try:
if content:
filename = generate_presentation(content)
st.write(f"file {filename} is generated.")
except Exception:
st.write("Error in generating slides.")
st.write(traceback.format_exc())
if __name__ == "__main__":
create_ui()
Step 5: Running the LLM Service
Navigate to the llm-service folder and run the gpt.py file:
cd llm-service
python gpt.py
Note: The first time you run this, the LLM model will be downloaded, which may take several minutes to complete.
Step 6: Launching the User Interface (UI)
Now, it’s time to bring up the UI. Navigate to the frontend folder and run the ui.py file using Streamlit:
cd ..
cd frontend
streamlit run ui.py
This command will launch the UI in your default web browser.
Creating Your PowerPoint Presentation
With the UI up and running, follow these simple steps to generate your presentation:
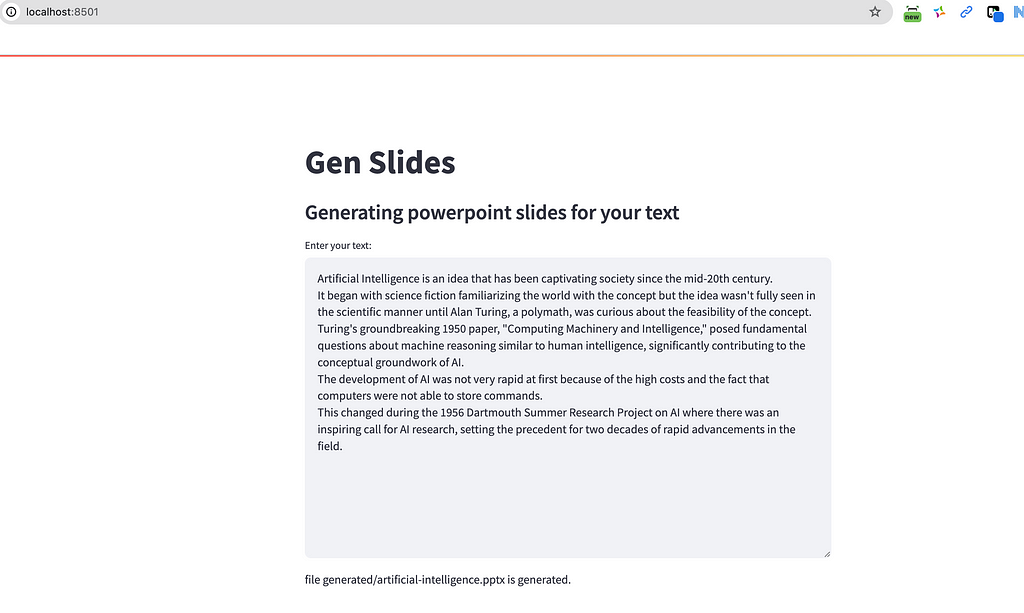
1. Input Text: In the provided text box, input the content you’d like to transform into a presentation. Here is the sample you may use:
Artificial Intelligence is an idea that has been captivating society since the mid-20th century.
It began with science fiction familiarizing the world with the concept but the idea wasn't fully seen in the scientific manner until Alan Turing, a polymath, was curious about the feasibility of the concept.
Turing's groundbreaking 1950 paper, "Computing Machinery and Intelligence," posed fundamental questions about machine reasoning similar to human intelligence, significantly contributing to the conceptual groundwork of AI.
The development of AI was not very rapid at first because of the high costs and the fact that computers were not able to store commands.
This changed during the 1956 Dartmouth Summer Research Project on AI where there was an inspiring call for AI research, setting the precedent for two decades of rapid advancements in the field.
2. Generate Slides: Once you enter the text (followed by Command ⌘ + Enter keys in Mac), GenSlide will process it and create the presentation .pptxfile.
3. Access Your Slides: The newly created PowerPoint file will be saved in thefrontend/generatedfolder.
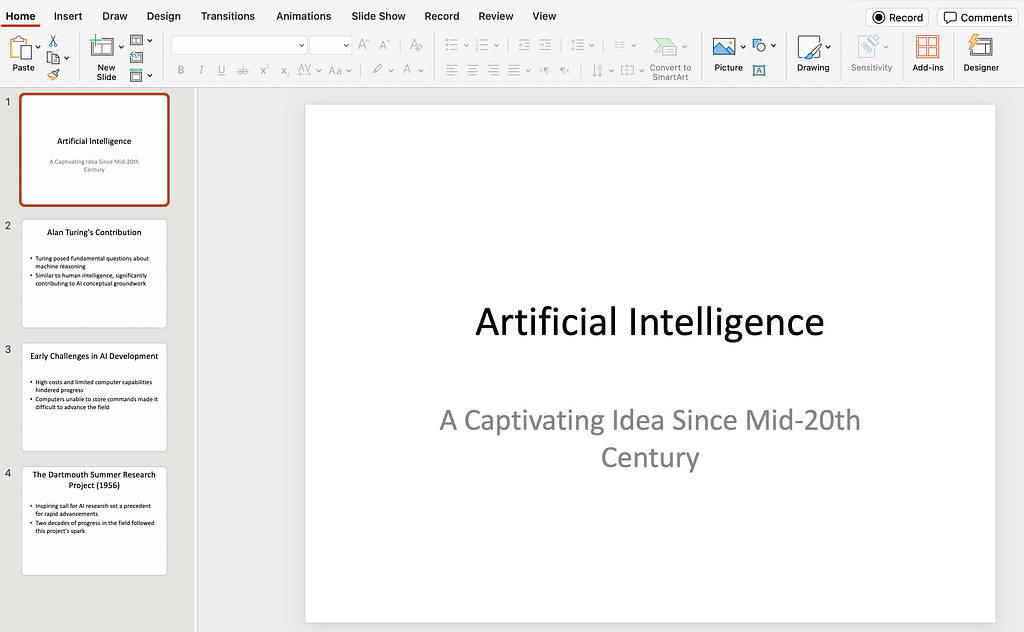
Congratulations! The ability to automate slide generation is not just a technical achievement; it’s a time-saving marvel for professionals and students alike. For the next steps, the application can be extended to read the text from other formats like PDF files, MS Word documents, web pages and more. I would be happy to hear how you use or extend this project.
For further enhancement and contributions, feel free to explore the repository on GitHub.
How to Create an LLM-Powered app to Convert Text to Presentation Slides: GenSlide — A Step-by-step… was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
Originally appeared here:
How to Create an LLM-Powered app to Convert Text to Presentation Slides: GenSlide — A Step-by-step…