
A holistic view of designing efficient architecture for AI/ML
State-of-the-art generative AI technologies in computer vision, natural language processing, etc. have been exploding recently with research breakthroughs on innovative model architectures including stable diffusion, neural rendering (NeRF), text to 3D, large language models(LLM), and more. These advanced technologies require more complex AI networks, and demand orders of magnitude more compute resources and energy-efficient architecture.
To fulfill the above-mentioned architectural requirement, bridging the gap between hardware(HW) and software(SW)/algorithm design is essential. Co-design involves an iterative process of designing, testing, and refining both HW and SW components until the system meets the desired performance requirements. However, SW and HW are traditionally designed independently as SW programmers seldom need to think about which HW to run on, and HW is typically designed to support a wide range of SW. There are very limited studies on SW/HW co-design which is strongly required for supporting AI workloads efficiently.
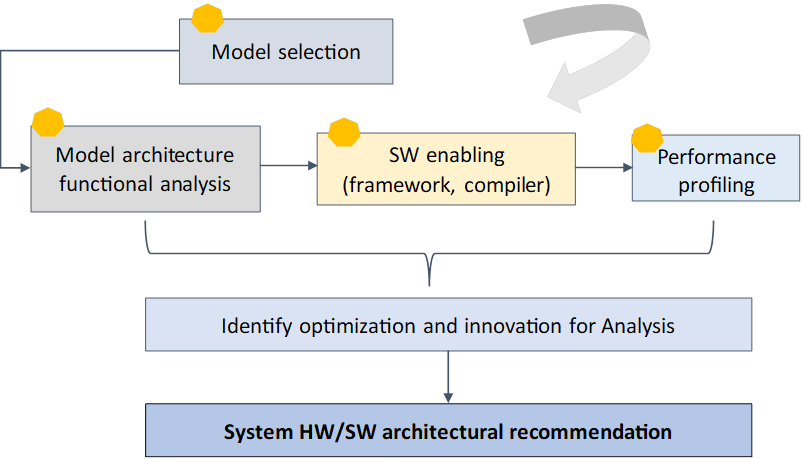
We have to design efficient ‘SW/algorithm aware’ HW and ‘HW aware’ SW/algorithm, so they can tightly intertwine to squeeze every bit of our limited compute resources. How should we do it? Below is an evolving methodology that can be used as a reference if you are architecting new HW/SW features for AI.
1. Identify proxy AI workloads.
To initiate the analysis, we need proxy AI models and define a priority list to investigate further. There are multiple resources you can refer to, including the latest research paper (CVPR, Siggraph, research labs from big tech) with open-source code, customer feedback or requests, industry trends, etc. Filter out several representative models based on your expert judgment. This step is crucial as you are using them to design your ‘future architecture’
2. Thorough model architecture analysis.
Be sure to investigate the model architecture comprehensively to understand its functionality, innovation, and break it down into detailed pieces as much as you can. Are there new operators unsupported in the current tech stack? Where are the compute-intensive layers? Is it a data transfer (memory) heavy model? What is the datatype required and what type of quantization techniques can be applied without sacrificing accuracy? Which part of the model can be HW accelerated and where are the potential performance optimizations?
For example, in neural rendering, the model requires both rendering and computing (matrix multiplication) working in parallel, you need to check if the current SW stack supports render/compute simultaneously. In LLMs, key-value(KV) cache size is increasing w.r.t. input sequence length, it’s critical to understand the memory requirement and potential data transfer/memory hierarchy optimization to handle large KV cache.

3. SW enabling and prototyping
Download the open-source code for the model identified in Step 2, and run it on the ‘target’ SW framework/HW. This step is not straightforward, especially for new/disruptive models. As the goal is to enable a workable solution for performance analysis, it’s not necessary to deliver product-quality code at this stage. A dirty fix on SW without performance tunning is acceptable to proceed to Step 4. A major step is to convert the pre-trained model in the development framework (Pytorch) to a new format required by the targeted new framework.
torch.onnx.export(model,
dummy_input,
"resnet50.onnx",
verbose=False,
input_names=input_names,
outputnames=output_names,
export_params=True)
However, there are often cases where significant support effort is required. For example, to run differentiable rendering models, autograd needs to be supported. It’s very likely that this feature is not ready in the new framework, and requires months of effort from the development team. Another example is GPTQ quantization for LLMs, which might not be supported in the inference framework initially. Instead of waiting for the engineering team, architects can run the workload on the Nvidia system for performance analysis, as Nvidia is the choice of HW for academic development. This enables the development of a list of SW requirements based on the gaps observed during SW enabling.
4. Performance analysis and architectural innovation.
There are numerous metrics to judge an AI model’s performance. Below are the major ones we should consider.
4.1 FLOPs (Floating Point Operations) and MACs (Multiply-Accumulate Operations).
These metrics are commonly used to calculate the computational complexity of deep learning models. They provide a quick and easy way to understand the number of arithmetic operations required. FLOPs can be calculated through methods such as paper analysis, Vtune reports, or tools like flops-counter.pytorch and pytorch-OpCounter.
4.2 Memory Footprint and Bandwidth (BW)
Memory footprint mainly consists of weights (network parameters) and input data. For example, a Llama model with 13B parameters in FP16 consumes about 13*2 (FP16=2 bytes) = 26GB memory (input is negligible as weight takes much more space). Another key factor for LLMs is the KV cache size. KV cache takes up to 30% of total memory and it is dynamic (refer to picture in Step 2). Large models are usually memory bound as the speed is dependent on how quickly to move data from system memory to local memory, or from local memory to local caches/registers. Available memory BW is far better in predicting inference latency (token generation time for LLMs) than peak compute TOPS. One performance indicator is memory bandwidth utilization (MBU) which is defined as actual BW/peak BW. Ideally, MBU close to 100% indicates memory BW is fully utilized.
Enough Memory is Not Enough!

As memory is a bottleneck, exploration in advanced model compression and memory/caching technologies are required. A few pioneer works are listed below:
- MemGPT: it utilizes different level memory hierarchy resources, such as a combination of fast and small RAM, and large and slow storage storage memory. Information must be explicitly transferred between them. [2]
- Low precision quantization (GPTQ, AWQ, GGML) to reduce the memory footprint of models
- In-memory computing (PIM) : Reduce power and improve performance by eliminating the need of data movement.
4.3 Latency/throughput.
In computer vision, latency is the time to generate one frame. In the context of LLMs, it is the time between the first token and the next token generation. Throughput is the number of tokens/frames per second. Latency is a critical metric for measuring AI system performance and is a compound factor of both SW/HW performance. There are various optimization strategies to consider, to name a few below:
- Optimization of bandwidth-constrained operations like normalizations, pointwise operations, SoftMax, and ReLU. It is estimated that normalization and pointwise operations consume nearly 40% more runtime than matrix multiplications, while only achieving 250x and 700x less FLOPS than matrix multiplications respectively. To solve the problem, kernel fusion can be utilized to fuse multiple operators to save data transfer costs or replace expensive operators (softmax) with light ones (ReLU).

- Specialized HW architecture. The integration of specialized hardware(AVX, GPUs, TPU, NPU) can lead to significant speedups and energy savings, which is particularly important for applications that require real-time processing on resource-constrained devices. For example, Intel AVX instructions can lead up to 60,000 times more speed-up than native Python code.

Tensor cores on Nvidia graphics (V100, A100, H100, etc.) can multiply and add two FP16 and/or FP32 matrices in one clock cycle, compared to Cuda cores which can only perform 1 operation per cycle. However, the utilization of tensor core is very low (3% — 9% for end-to-end training), resulting in high energy cost and low performance. There is active research on improving systolic array utilization (FlexSA, multi-directional SA, etc. ) that I will write in the next series of posts.

In addition, as memory and data traffic is always a bottleneck for large AI models, it’s crucial to explore advanced architecture considering bigger and more efficient memory on chip. One example is the Cerebras core memory design, where memory is independently addressed per core.

- There are a lot of other optimizations: Parallelism, KV cache quantization for LLMs, sparse activation, and End-to-End Optimization — I will explain more in upcoming posts
4.4 Power and energy efficiency
Power is another beast we need to look into, especially for low-power user scenarios. It is always a tradeoff between performance and power. As illustrated below, the memory access operation takes a couple of orders of magnitude more energy than computation operations. Reduction in memory transfer is strongly required to save power.

Conclusion
Above are major metrics we need to measure for AI model performance, using performance profilers like Vtune, Nsight, or other modeling tools, architects can deep dive into the next level of performance details (layer-wise compute/memory traffic, compute efficiency, BW utilization, etc. ) and identify hotspots leveraging traces. Very often, performance could be unexpectedly low because of software inefficiencies. It is an iterative process to co-design the AI SW/HW based on proxy models.
It is a collaborative effort to conduct a thorough architectural analysis of emerging AI models. The investigation cycle could be pretty long, and there are always tradeoffs between product schedule and analysis depth. Strong expertise in HW, SW, and AI technologies is required at the same time to architect efficient AI solutions.
Reference
[1] Woosuk Kwon, Zhuohan Li, Siyuan Zhuang, Ying Sheng, Lianmin Zheng, Cody Hao Yu, Joseph E. Gonzalez, Hao Zhang, Ion Stoica, Efficient Memory Management for Large Language Model Serving with Paged Attention, 2023, arxiv
[2] Charles Packer, Vivian Fang, Shishir G. Patil, Kevin Lin, Sarah Wooders, Joseph E. Gonzalez, MemGPT: Towards LLMs as Operating Systems, 2023, arxiv
[3] Charles Leiserson, Neil Thompson, Joel Emer, Bradley Kuszmaul, Butler Lampson, Daniel Sanchez, and Tao Schardl, There’s plenty of room at the Top: What will drive computer performance after Moore’s law? 2020, Science
[4] Song Han, Jeff Pool, John Tran, William J. Dally, Learning both Weights and Connections for Efficient Neural Networks, 2015, arxiv
How to co-design software/hardware architecture for AI/ML in a new era? was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
Originally appeared here:
How to co-design software/hardware architecture for AI/ML in a new era?
Go Here to Read this Fast! How to co-design software/hardware architecture for AI/ML in a new era?



