The choice between cloud and edge deployment could make or break your project

As a machine learning engineer, I frequently see discussions on social media emphasizing the importance of deploying ML models. I completely agree — model deployment is a critical component of MLOps. As ML adoption grows, there’s a rising demand for scalable and efficient deployment methods, yet specifics often remain unclear.
So, does that mean model deployment is always the same, no matter the context? In fact, quite the opposite: I’ve been deploying ML models for about a decade now, and it can be quite different from one project to another. There are many ways to deploy a ML model, and having experience with one method doesn’t necessarily make you proficient with others.
The remaining question is: what are the methods to deploy a ML model, and how do we choose the right method?
Models can be deployed in various ways, but they typically fall into two main categories:
- Cloud deployment
- Edge deployment
It may sound easy, but there’s a catch. For both categories, there are actually many subcategories. Here is a non-exhaustive diagram of deployments that we will explore in this article:

Before talking about how to choose the right method, let’s explore each category: what it is, the pros, the cons, the typical tech stack, and I will also share some personal examples of deployments I did in that context. Let’s dig in!
Cloud Deployment
From what I can see, it seems cloud deployment is by far the most popular choice when it comes to ML deployment. This is what is usually expected to master for model deployment. But cloud deployment usually means one of these, depending on the context:
- API deployment
- Serverless deployment
- Batch processing
Even in those sub-categories, one could have another level of categorization but we won’t go that far in that post. Let’s have a look at what they mean, their pros and cons and a typical associated tech stack.
API Deployment
API stands for Application Programming Interface. This is a very popular way to deploy a model on the cloud. Some of the most popular ML models are deployed as APIs: Google Maps and OpenAI’s ChatGPT can be queried through their APIs for examples.
If you’re not familiar with APIs, know that it’s usually called with a simple query. For example, type the following command in your terminal to get the 20 first Pokémon names:
curl -X GET https://pokeapi.co/api/v2/pokemon
Under the hood, what happens when calling an API might be a bit more complex. API deployments usually involve a standard tech stack including load balancers, autoscalers and interactions with a database:
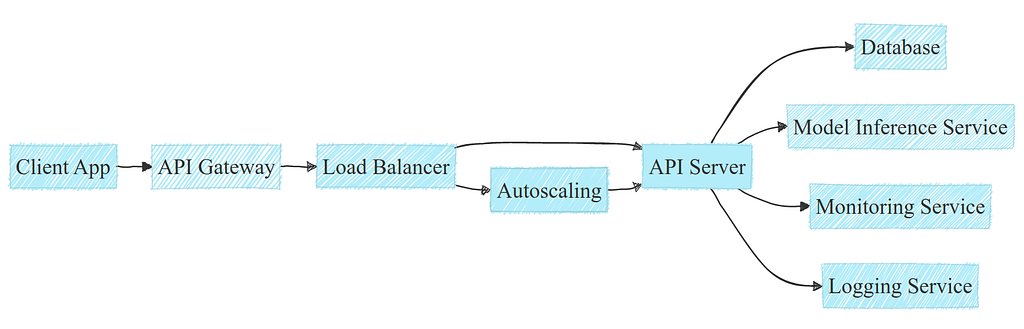
Note: APIs may have different needs and infrastructure, this example is simplified for clarity.
API deployments are popular for several reasons:
- Easy to implement and to integrate into various tech stacks
- It’s easy to scale: using horizontal scaling in clouds allow to scale efficiently; moreover managed services of cloud providers may reduce the need for manual intervention
- It allows centralized management of model versions and logging, thus efficient tracking and reproducibility
While APIs are a really popular option, there are some cons too:
- There might be latency challenges with potential network overhead or geographical distance; and of course it requires a good internet connection
- The cost can climb up pretty quickly with high traffic (assuming automatic scaling)
- Maintenance overhead can get expensive, either with managed services cost of infra team
To sum up, API deployment is largely used in many startups and tech companies because of its flexibility and a rather short time to market. But the cost can climb up quite fast for high traffic, and the maintenance cost can also be significant.
About the tech stack: there are many ways to develop APIs, but the most common ones in Machine Learning are probably FastAPI and Flask. They can then be deployed quite easily on the main cloud providers (AWS, GCP, Azure…), preferably through docker images. The orchestration can be done through managed services or with Kubernetes, depending on the team’s choice, its size, and skills.
As an example of API cloud deployment, I once deployed a ML solution to automate the pricing of an electric vehicle charging station for a customer-facing web app. You can have a look at this project here if you want to know more about it:
How Renault Leveraged Machine Learning to Scale Electric Vehicle Sales
Even if this post does not get into the code, it can give you a good idea of what can be done with API deployment.
API deployment is very popular for its simplicity to integrate to any project. But some projects may need even more flexibility and less maintenance cost: this is where serverless deployment may be a solution.
Serverless Deployment
Another popular, but probably less frequently used option is serverless deployment. Serverless computing means that you run your model (or any code actually) without owning nor provisioning any server.
Serverless deployment offers several significant advantages and is quite easy to set up:
- No need to manage nor to maintain servers
- No need to handle scaling in case of higher traffic
- You only pay for what you use: no traffic means virtually no cost, so no overhead cost at all
But it has some limitations as well:
- It is usually not cost effective for large number of queries compared to managed APIs
- Cold start latency is a potential issue, as a server might need to be spawned, leading to delays
- The memory footprint is usually limited by design: you can’t always run large models
- The execution time is limited too: it’s not possible to run jobs for more than a few minutes (15 minutes for AWS Lambda for example)
In a nutshell, I would say that serverless deployment is a good option when you’re launching something new, don’t expect large traffic and don’t want to spend much on infra management.
Serverless computing is proposed by all major cloud providers under different names: AWS Lambda, Azure Functions and Google Cloud Functions for the most popular ones.
I personally have never deployed a serverless solution (working mostly with deep learning, I usually found myself limited by the serverless constraints mentioned above), but there is lots of documentation about how to do it properly, such as this one from AWS.
While serverless deployment offers a flexible, on-demand solution, some applications may require a more scheduled approach, like batch processing.
Batch Processing
Another way to deploy on the cloud is through scheduled batch processing. While serverless and APIs are mostly used for live predictions, in some cases batch predictions makes more sense.
Whether it be database updates, dashboard updates, caching predictions… as soon as there is no need to have a real-time prediction, batch processing is usually the best option:
- Processing large batches of data is more resource-efficient and reduce overhead compared to live processing
- Processing can be scheduled during off-peak hours, allowing to reduce the overall charge and thus the cost
Of course, it comes with associated drawbacks:
- Batch processing creates a spike in resource usage, which can lead to system overload if not properly planned
- Handling errors is critical in batch processing, as you need to process a full batch gracefully at once
Batch processing should be considered for any task that does not required real-time results: it is usually more cost effective. But of course, for any real-time application, it is not a viable option.
It is used widely in many companies, mostly within ETL (Extract, Transform, Load) pipelines that may or may not contain ML. Some of the most popular tools are:
- Apache Airflow for workflow orchestration and task scheduling
- Apache Spark for fast, massive data processing
As an example of batch processing, I used to work on a YouTube video revenue forecasting. Based on the first data points of the video revenue, we would forecast the revenue over up to 5 years, using a multi-target regression and curve fitting:

For this project, we had to re-forecast on a monthly basis all our data to ensure there was no drifting between our initial forecasting and the most recent ones. For that, we used a managed Airflow, so that every month it would automatically trigger a new forecasting based on the most recent data, and store those into our databases. If you want to know more about this project, you can have a look at this article:
How to Forecast YouTube Video Revenue
After exploring the various strategies and tools available for cloud deployment, it’s clear that this approach offers significant flexibility and scalability. However, cloud deployment is not always the best fit for every ML application, particularly when real-time processing, privacy concerns, or financial resource constraints come into play.

This is where edge deployment comes into focus as a viable option. Let’s now delve into edge deployment to understand when it might be the best option.
Edge Deployment
From my own experience, edge deployment is rarely considered as the main way of deployment. A few years ago, even I thought it was not really an interesting option for deployment. With more perspective and experience now, I think it must be considered as the first option for deployment anytime you can.
Just like cloud deployment, edge deployment covers a wide range of cases:
- Native phone applications
- Web applications
- Edge server and specific devices
While they all share some similar properties, such as limited resources and horizontal scaling limitations, each deployment choice may have their own characteristics. Let’s have a look.
Native Application
We see more and more smartphone apps with integrated AI nowadays, and it will probably keep growing even more in the future. While some Big Tech companies such as OpenAI or Google have chosen the API deployment approach for their LLMs, Apple is currently working on the iOS app deployment model with solutions such as OpenELM, a tini LLM. Indeed, this option has several advantages:
- The infra cost if virtually zero: no cloud to maintain, it all runs on the device
- Better privacy: you don’t have to send any data to an API, it can all run locally
- Your model is directly integrated to your app, no need to maintain several codebases
Moreover, Apple has built a fantastic ecosystem for model deployment in iOS: you can run very efficiently ML models with Core ML on their Apple chips (M1, M2, etc…) and take advantage of the neural engine for really fast inferences. To my knowledge, Android is slightly lagging behind, but also has a great ecosystem.
While this can be a really beneficial approach in many cases, there are still some limitations:
- Phone resources limit model size and performance, and are shared with other apps
- Heavy models may drain the battery pretty fast, which can be deceptive for the user experience overall
- Device fragmentation, as well as iOS and Android apps make it hard to cover the whole market
- Decentralized model updates can be challenging compared to cloud
Despite its drawbacks, native app deployment is often a strong choice for ML solutions that run in an app. It may seem more complex during the development phase, but it will turn out to be much cheaper as soon as it’s deployed compared to a cloud deployment.
When it comes to the tech stack, there are actually two main ways to deploy: iOS and Android. They both have their own stacks, but they share the same properties:
- App development: Swift for iOS, Kotlin for Android
- Model format: Core ML for iOS, TensorFlow Lite for Android
- Hardware accelerator: Apple Neural Engine for iOS, Neural Network API for Android
Note: This is a mere simplification of the tech stack. This non-exhaustive overview only aims to cover the essentials and let you dig in from there if interested.
As a personal example of such deployment, I once worked on a book reading app for Android, in which they wanted to let the user navigate through the book with phone movements. For example, shake left to go to the previous page, shake right for the next page, and a few more movements for specific commands. For that, I trained a model on accelerometer’s features from the phone for movement recognition with a rather small model. It was then deployed directly in the app as a TensorFlow Lite model.
Native application has strong advantages but is limited to one type of device, and would not work on laptops for example. A web application could overcome those limitations.
Web Application
Web application deployment means running the model on the client side. Basically, it means running the model inference on the device used by that browser, whether it be a tablet, a smartphone or a laptop (and the list goes on…). This kind of deployment can be really convenient:
- Your deployment is working on any device that can run a web browser
- The inference cost is virtually zero: no server, no infra to maintain… Just the customer’s device
- Only one codebase for all possible devices: no need to maintain an iOS app and an Android app simultaneously
Note: Running the model on the server side would be equivalent to one of the cloud deployment options above.
While web deployment offers appealing benefits, it also has significant limitations:
- Proper resource utilization, especially GPU inference, can be challenging with TensorFlow.js
- Your web app must work with all devices and browsers: whether is has a GPU or not, Safari or Chrome, a Apple M1 chip or not, etc… This can be a heavy burden with a high maintenance cost
- You may need a backup plan for slower and older devices: what if the device can’t handle your model because it’s too slow?
Unlike for a native app, there is no official size limitation for a model. However, a small model will be downloaded faster, making it overall experience smoother and must be a priority. And a very large model may just not work at all anyway.
In summary, while web deployment is powerful, it comes with significant limitations and must be used cautiously. One more advantage is that it might be a door to another kind of deployment that I did not mention: WeChat Mini Programs.
The tech stack is usually the same as for web development: HTML, CSS, JavaScript (and any frameworks you want), and of course TensorFlow Lite for model deployment. If you’re curious about an example of how to deploy ML in the browser, you can have a look at this post where I run a real time face recognition model in the browser from scratch:
BlazeFace: How to Run Real-time Object Detection in the Browser
This article goes from a model training in PyTorch to up to a working web app and might be informative about this specific kind of deployment.
In some cases, native and web apps are not a viable option: we may have no such device, no connectivity, or some other constraints. This is where edge servers and specific devices come into play.
Edge Servers and Specific Devices
Besides native and web apps, edge deployment also includes other cases:
- Deployment on edge servers: in some cases, there are local servers running models, such as in some factory production lines, CCTVs, etc…Mostly because of privacy requirements, this solution is sometimes the only available
- Deployment on specific device: either a sensor, a microcontroller, a smartwatch, earplugs, autonomous vehicle, etc… may run ML models internally
Deployment on edge servers can be really close to a deployment on cloud with API, and the tech stack may be quite close.
Note: It is also possible to run batch processing on an edge server, as well as just having a monolithic script that does it all.
But deployment on specific devices may involve using FPGAs or low-level languages. This is another, very different skillset, that may differ for each type of device. It is sometimes referred to as TinyML and is a very interesting, growing topic.
On both cases, they share some challenges with other edge deployment methods:
- Resources are limited, and horizontal scaling is usually not an option
- The battery may be a limitation, as well as the model size and memory footprint
Even with these limitations and challenges, in some cases it’s the only viable solution, or the most cost effective one.
An example of an edge server deployment I did was for a company that wanted to automatically check whether the orders were valid in fast food restaurants. A camera with a top down view would look at the plateau, compare what is sees on it (with computer vision and object detection) with the actual order and raise an alert in case of mismatch. For some reason, the company wanted to make that on edge servers, that were within the fast food restaurant.
To recap, here is a big picture of what are the main types of deployment and their pros and cons:
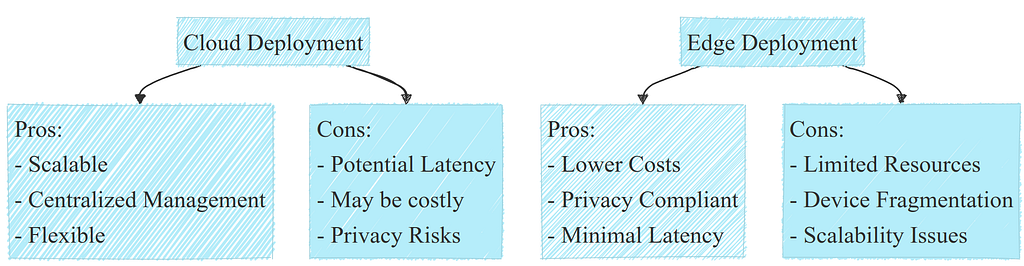
With that in mind, how to actually choose the right deployment method? There’s no single answer to that question, but let’s try to give some rules in the next section to make it easier.
How to Choose the Right Deployment
Before jumping to the conclusion, let’s make a decision tree to help you choose the solution that fits your needs.
Choosing the right deployment requires understanding specific needs and constraints, often through discussions with stakeholders. Remember that each case is specific and might be a edge case. But in the diagram below I tried to outline the most common cases to help you out:
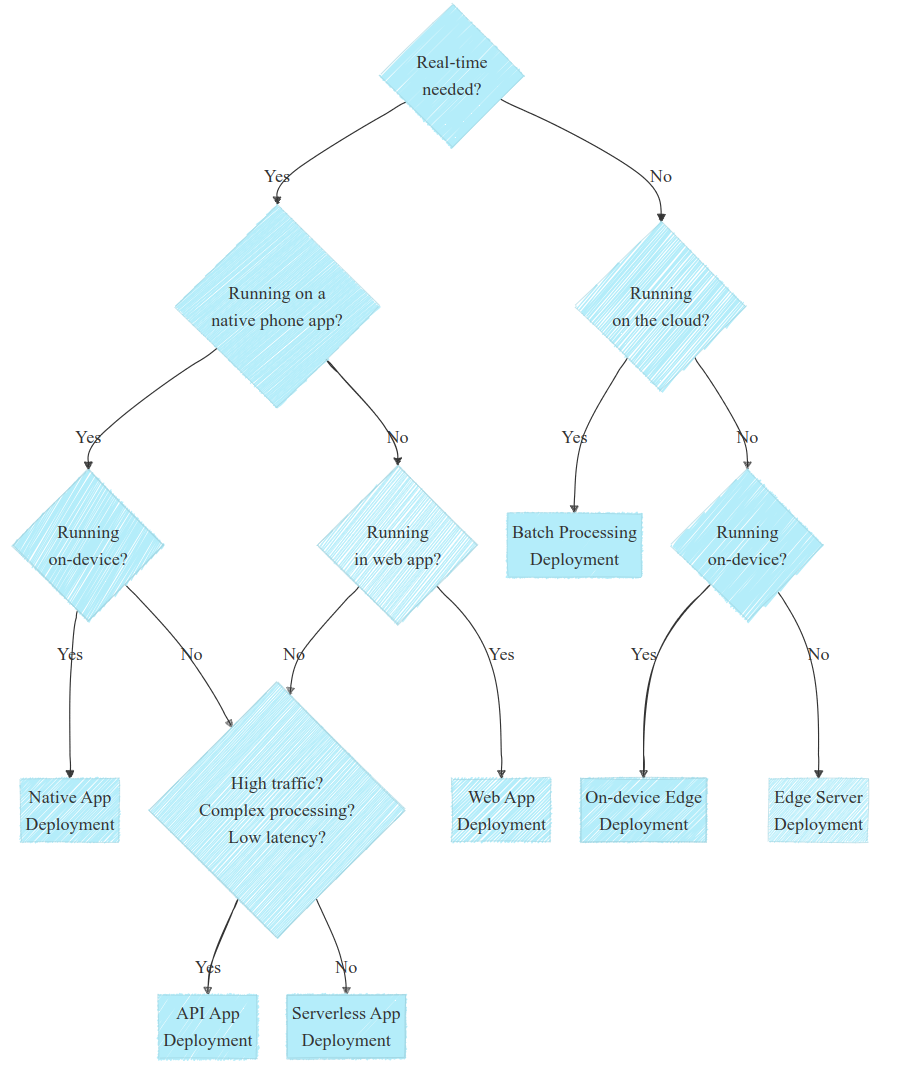
This diagram, while being quite simplistic, can be reduced to a few questions that would allow you go in the right direction:
- Do you need real-time? If no, look for batch processing first; if yes, think about edge deployment
- Is your solution running on a phone or in the web? Explore these deployments method whenever possible
- Is the processing quite complex and heavy? If yes, consider cloud deployment
Again, that’s quite simplistic but helpful in many cases. Also, note that a few questions were omitted for clarity but are actually more than important in some context: Do you have privacy constraints? Do you have connectivity constraints? What is the skillset of your team?
Other questions may arise depending on the use case; with experience and knowledge of your ecosystem, they will come more and more naturally. But hopefully this may help you navigate more easily in deployment of ML models.
Conclusion and Final Thoughts
While cloud deployment is often the default for ML models, edge deployment can offer significant advantages: cost-effectiveness and better privacy control. Despite challenges such as processing power, memory, and energy constraints, I believe edge deployment is a compelling option for many cases. Ultimately, the best deployment strategy aligns with your business goals, resource constraints and specific needs.
If you’ve made it this far, I’d love to hear your thoughts on the deployment approaches you used for your projects.
How to Choose the Best ML Deployment Strategy: Cloud vs. Edge was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
Originally appeared here:
How to Choose the Best ML Deployment Strategy: Cloud vs. Edge
Go Here to Read this Fast! How to Choose the Best ML Deployment Strategy: Cloud vs. Edge