An overview of how to leverage streaming using open source tools applied to building a simple agentic chat bot
In this post we will go over how to build an agentic chatbot that streams responses to the user, leveraging Burr’s (I’m an author) streaming capabilities, FastAPI’s StreamingResponse, and server-sent-events (SSEs) queried by React. All of these are open source tools. This is aimed at those who want to learn more about streaming in Python and how to add interactivity to their agent/application. While the tools we use will be fairly specific, the lessons should be applicable to a wide range of streaming response implementations.
First, we’ll talk about why streaming is important. Then we’ll go over the open-source tooling we use. We’ll walk through an example, and point you out to code that you can use to get started, then share more resources and alternate implementations.
You can follow along with the Burr + FastAPI code here and the frontend code here. You can also run this example (you’ll need an OPENAI_API_KEY env variable) by running pip install “burr[start]” && burr, then navigating to localhost:7241/demos/streaming-chatbot (the browser will open automatically, just click demos/streaming-chatbot on the left. Note this example requires burr>=0.23.0.
Why Streaming?
While streaming media through the web is a technology from the 90s, and is now ubiquitous (video games, streaming TV, music, etc…), the recent surge in generative AI applications has seen an interest in serving and rendering streaming text, word by word.
LLMs are a fun technology (perhaps even useful), but relatively slow to run, and users don’t like waiting. Luckily, it is possible to stream the results so that a user sees an LLM’s response as it is being generated. Furthermore, given the generally robotic and stuffy nature of LLMs, streaming can make them appear more interactive, almost as if they’re thinking.
A proper implementation will allow streaming communication across multiple service boundaries, enabling intermediate proxies to augment/store the streaming data as it is presented to the user.
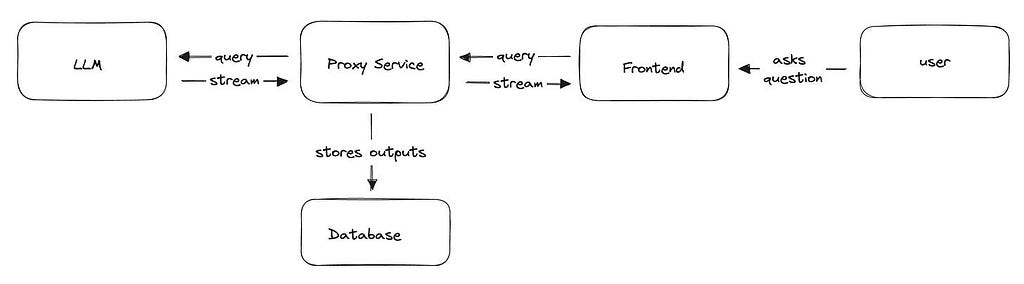
While none of this is rocket science, the same tools that make web development easy and largely standardized (OpenAPI / FastAPI / React + friends, etc…) all have varying degrees of support, meaning that you often have multiple choices that are different than what you’re used to. Streaming is often an afterthought in framework design, leading to various limitations that you might not know until you’re halfway through building.
Let’s go over some of the tools we’ll use to implement the stack above, then walk through an example.
The Open Source Tools
The tools we’ll leverage to build this are nicely decoupled from each other — you can swap like with like if you want and still apply the same lessons/code.
Burr
Burr is a lightweight Python library you use to build applications as state machines. You construct your application out of a series of actions (these can be either decorated functions or objects), which declare inputs from state, as well as inputs from the user. These specify custom logic (delegating to any framework), as well as instructions on how to update state. State is immutable, which allows you to inspect it at any given point. Burr handles orchestration, monitoring, persistence, etc…).
@action(reads=["count"], writes=["count"])
def counter(state: State) -> State:
return state.update(counter=state.get("count", 0) +1)
You run your Burr actions as part of an application — this allows you to string them together with a series of (optionally) conditional transitions from action to action.
from burr.core import ApplicationBuilder, default, expr
app = (
ApplicationBuilder()
.with_actions(
count=count,
done=done # implementation left out above
).with_transitions(
("counter", "counter", expr("count < 10")), # Keep counting if the counter is < 10
("counter", "done", default) # Otherwise, we're done
).with_state(count=0)
.with_entrypoint("counter") # we have to start somewhere
.build()
)
Burr comes with a user-interface that enables monitoring/telemetry, as well as hooks to persist state/execute arbitrary code during execution.
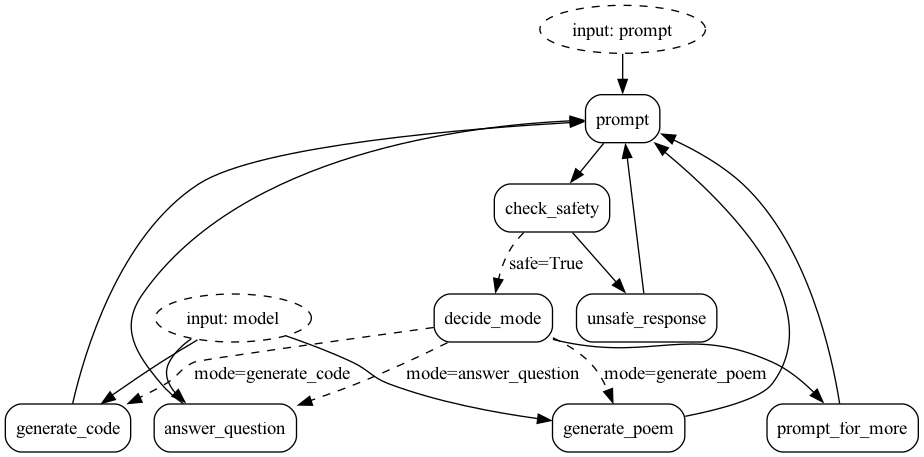
You can visualize this as a flow chart, i.e. graph / state machine:

And monitor it using the local telemetry debugger:
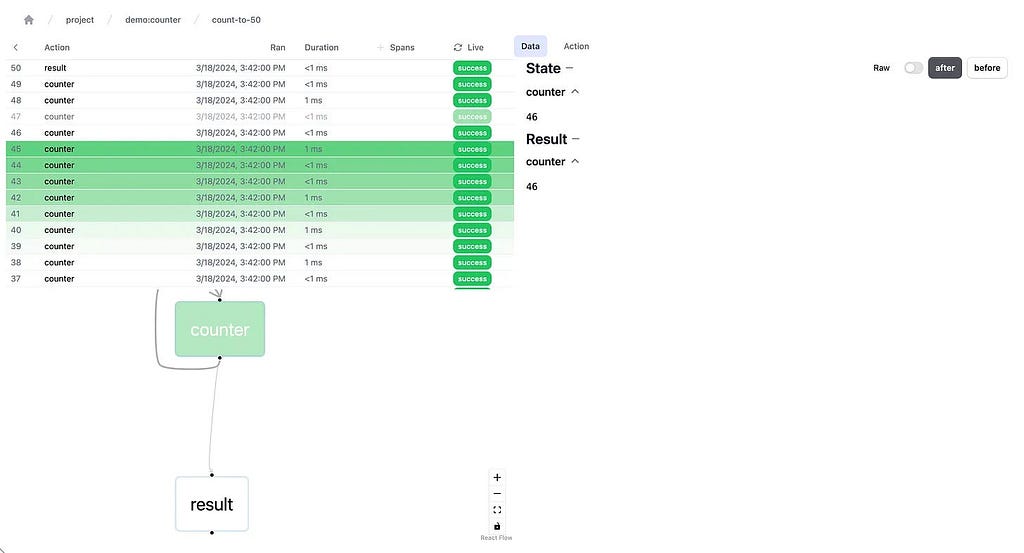
While the above example is a simple illustration, Burr is commonly used for Agents (like in this example), RAG applications, and human-in-the-loop AI interfaces. See the repository examples for a (more exhaustive) set of use-cases. We’ll go over streaming and a few more powerful features a little later.
FastAPI
FastAPI is a framework that lets you expose python functions in a REST API. It has a simple interface — you write your functions then decorate them, and run your script — turning it into a server with self-documenting endpoints through OpenAPI.
@app.get("/")
def read_root():
return {"Hello": "World"}
@app.get("/items/{item_id}")
def read_item(item_id: int, q: Union[str, None] = None):
return {"item_id": item_id, "q": q}
FastAPI provides a myriad of benefits. It is async native, supplies documentation through OpenAPI, and is easy to deploy on any cloud provider. It is infrastructure agnostic and can generally scale horizontally (so long as consideration into state management is done). See this page for more information.
React
React needs no introduction — it is an extremely popular tool that powers much of the internet. Even recent popular tools (such as next.js/remix) build on top of it. For more reading, see react.dev. We will be using React along with typescript and tailwind, but you can generally replace with your favorite frontend tools and be able to reuse much of this post.
Building a simple Agentic chatbot
Let’s build a simple agentic chatbot — it will be agentic as it actually makes two LLM calls:
- A call to determine the model to query. Our model will have a few “modes” — generate a poem, answer a question, etc…
- A call to the actual model (in this case prompt + model combination)
With the OpenAI API this is more of a toy example — their models are impressive jacks of all trades. That said, this pattern of tool delegation shows up in a wide variety of AI systems, and this example can be extrapolated cleanly.
Modeling the Agent in Burr
Modeling as a State Machine
To leverage Burr, we model our agentic application as a state machine. The basic flow of logic looks like this:
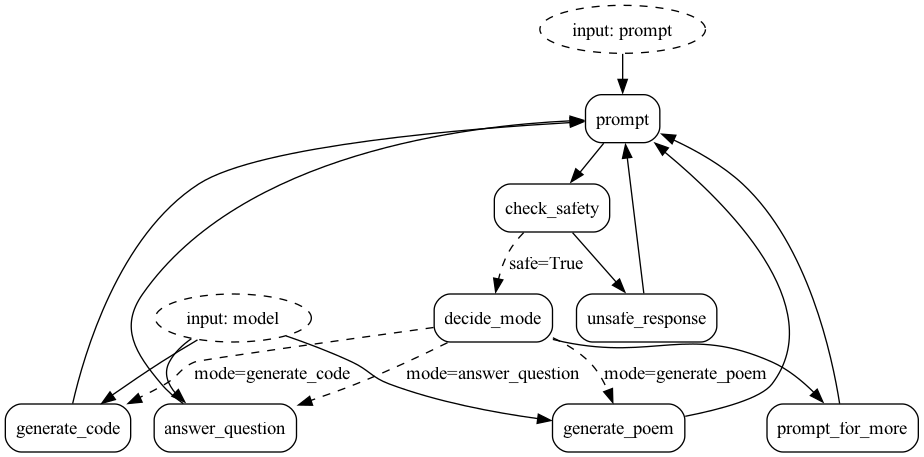
To model this with Burr, we will first create corresponding actions, using the streaming API. Then we’ll tie them together as an application.
Streaming Actions
In Burr, actions can leverage both a synchronous and asynchronous API. In this case we’ll be using async. Streaming functions in Burr can also be mixed and match with non-streaming actions, but to simplify we will implement everything as streaming. So, whether it’s streaming from OpenAPI (which has its own async streaming interface), or returning a fixed Sorry I cannot answer this question response, it will still be implemented as a generator.
For those who are unfamiliar, generators are a Python construct that enables efficient, lazy evaluation over a sequence of values. They are created by the yield keyword, which cedes control from the function back to the caller, until the next item is needed. Async generators function similarly, except they also cede control of the event loop on yield. Read more about synchronous generators and asynchronous generators.
Streaming actions in Burr are implemented as a generator that yields tuples, consisting of:
- The intermediate result (in this case, delta token in the message)
- The final state update, if it is complete, or None if it is still generating
Thus the final yield will indicate that the stream is complete, and output a final result for storage/debugging later. A basic response that proxies to OpenAI with some custom prompt manipulation looks like this:
@streaming_action(reads=["prompt", "chat_history", "mode"], writes=["response"])
async def chat_response(
state: State, prepend_prompt: str, model: str = "gpt-3.5-turbo"
) -> AsyncGenerator[Tuple[dict, Optional[State]], None]:
"""A simple proxy.
This massages the chat history to pass the context to OpenAI,
streams the result back, and finally yields the completed result
with the state update.
"""
client = _get_openai_client()
# code skipped that prepends a custom prompt and formats chat history
chat_history_for_openai = _format_chat_history(
state["chat_history"],
prepend_final_promprt=prepend_prompt)
result = await client.chat.completions.create(
model=model, messages=chat_history_api_format, stream=True
)
buffer = []
async for chunk in result:
chunk_str = chunk.choices[0].delta.content
if chunk_str is None:
continue
buffer.append(chunk_str)
yield {"delta": chunk_str}, None
result = {
"response": {"content": "".join(buffer), "type": "text", "role": "assistant"},
}
yield result, state.update(**result).append(chat_history=result["response"])
In the example, we also have a few other streaming actions — these will represent the “terminal” actions — actions that will trigger the workflow to pause when the state machine completes them.
Building an Application
To build the application, we’re first going to build a graph. We’ll be using the Graph API for Burr, allowing us to decouple the shape of the graph from other application concerns. In a web service the graph API is a very clean way to express state machine logic. You can build it once, globally, then reuse it per individual application instances. The graph builder looks like this — note it refers to the function chat_response from above:
# Constructing a graph from actions (labeled by kwargs) and
# transitions (conditional or default).
graph = (
GraphBuilder()
.with_actions(
prompt=process_prompt,
check_safety=check_safety,
decide_mode=choose_mode,
generate_code=chat_response.bind(
prepend_prompt="Please respond with *only* code and no other text"
"(at all) to the following",
),
# more left out for brevity
)
.with_transitions(
("prompt", "check_safety", default),
("check_safety", "decide_mode", when(safe=True)),
("check_safety", "unsafe_response", default),
("decide_mode", "generate_code", when(mode="generate_code")),
# more left out for brevity
)
.build()
)
Finally, we can add this together in an Application — which exposes the right execution methods for the server to interact with:
# Here we couple more application concerns (telemetry, tracking, etc…).
app = ApplicationBuilder()
.with_entrypoint("prompt")
.with_state(chat_history=[])
.with_graph(graph)
.with_tracker(project="demo_chatbot_streaming")
.with_identifiers(app_id=app_id)
.build()
)
When we want to run it, we can call out to astream_results. This takes in a set of halting conditions, and returns an AsyncStreamingResultContainer (a generator that caches the result and ensures Burr tracking is called), as well as the action that triggered the halt.
# Running the application as you would to test,
# (in a jupyter notebook, for instance).
action, streaming_container = await app.astream_result(
halt_after=["generate_code", "unsafe_response", ...], # terminal actions
inputs={
"prompt": "Please generate a limerick about Alexander Hamilton and Aaron Burr"
}
)
async for item in streaming_container:
print(item['delta'], end="")
Exposing in a Web Server
Now that we have the Burr application, we’ll want to integrate with FastAPI’s streaming response API using server-sent-events (SSEs). While we won’t dig too much into SSEs, the TL;DR is that they function as a one way (server → client) version of web-sockets. You can read more in the links at the end.
To use these in FastAPI, we declare an endpoint as a function that returns a StreamingResponse — a class that wraps a generator. The standard is to provide streaming responses in a special shape, “data: <contents> nn”. Read more about why here. While this is largely meant for the EventSource API (which we will be bypassing in favor of fetch and getReader()), we will keep this format for standards (and so that anyone using the EventSource API can reuse this code).
We have separately implemented _get_application, a utility function to get/load an application by ID.
The function will be a POST endpoint, as we are adding data to the server, although could easily be a PUT as well.
@app.post("/response/{project_id}/{app_id}", response_class=StreamingResponse)
async def chat_response(project_id: str, app_id: str, prompt: PromptInput) -> StreamingResponse:
"""A simple API that wraps our Burr application."""
burr_app = _get_application(project_id, app_id)
chat_history = burr_app.state.get("chat_history", [])
action, streaming_container = await burr_app.astream_result(
halt_after=chat_application.TERMINAL_ACTIONS, inputs=dict(prompt=prompt.prompt)
)
async def sse_generator():
yield f"data: {json.dumps({'type': 'chat_history', 'value': chat_history})}nn"
async for item in streaming_container:
yield f"data: {json.dumps({'type': 'delta', 'value': item['delta']})} nn"
return StreamingResponse(sse_generator())
Note that we define a generator inside the function that wraps the Burr result and turns it into SSE-friendly outputs. This allows us to impose some structure on the result, which we will use on the frontend. Unfortunately, we will have to parse it on our own, as fastAPI does not enable strict typing of a StreamingResponse.
Furthermore, we actually yield the entire state at the beginning, prior to execution. While this is not strictly necessary (we can also have a separate API for chat history), it will make rendering easier.
To test this you can use the requests library Response.iter_lines API.
Building a UI
Now that we have a server, our state machine, and our LLM lined up, let’s make it look nice! This is where it all ties together. While you can download and play with the entirety of the code in the example, we will be focusing in on the function that queries the API when you click “send”.
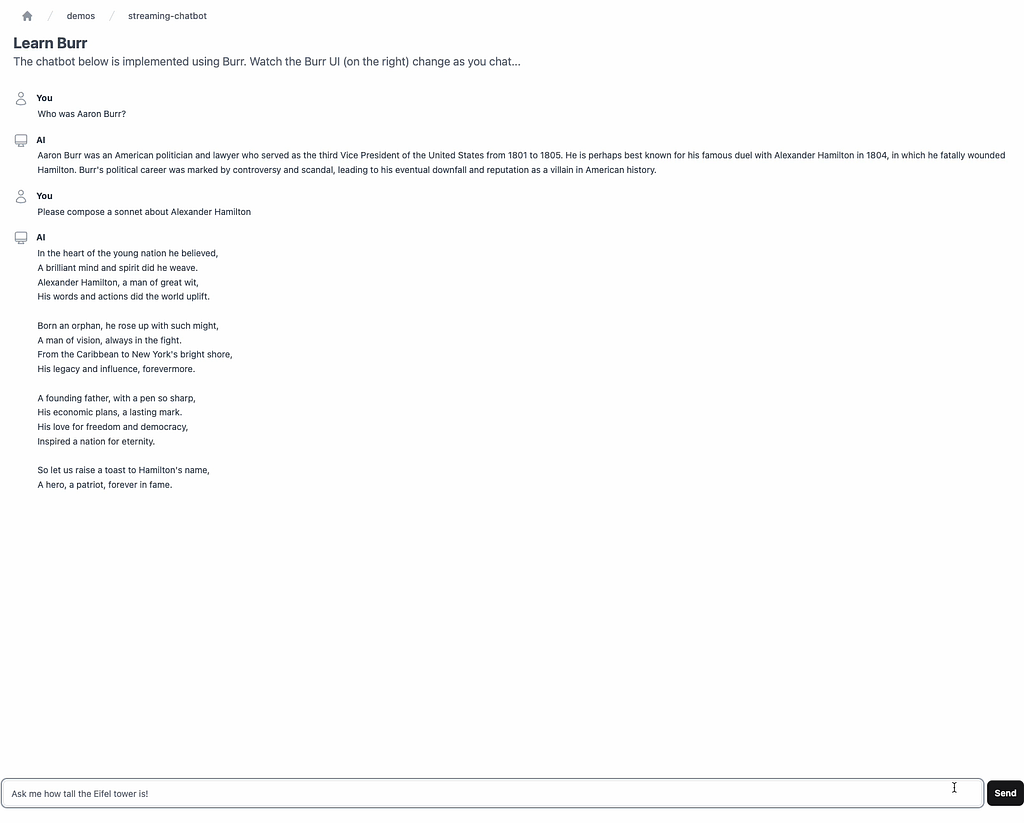
First, let’s query our API using fetch (obviously adjust this to your endpoint, in this case we’re proxying all /api calls to another server…):
// A simple fetch call with getReader()
const response = await fetch(
`/api/v0/streaming_chatbot/response/${props.projectId}/${props.appId}`,
{
method: 'POST',
headers: { 'Content-Type': 'application/json' },
body: JSON.stringify({ prompt: currentPrompt })
}
);
const reader = response.body?.getReader();
This looks like a plain old API call, leveraging the typescript async API. This extracts a reader object, which will help us stream results as they come in.
Let’s define some data types to leverage the structure we created above. In addition to the ChatItem data types (which was generated using openapi-typescript-codegen), we’ll also define two classes, which correspond to the data types returned by the server.
// Datatypes on the frontend.
// The contract is loose, as nothing in the framework encodes it
type Event = {
type: 'delta' | 'chat_history';
};
type ChatMessageEvent = Event & {
value: string;
};
type ChatHistoryEvent = Event & {
value: ChatItem[];
};
Next, we’ll iterate through the reader and parse. This assumes the following state variables in react:
- setCurrentResponse/currentResponse
- setDisplayedChatHistory
We read through, splitting on “data:”, then looping through splits and parsing/reacting depending on the event type.
// Loop through, continually getting the stream.
// For each item, parse it as our desired datatype and react appropriately.
while (true) {
const result = await reader.read();
if (result.done) {
break;
}
const message = decoder.decode(result.value, { stream: true });
message
.split('data: ')
.slice(1)
.forEach((item) => {
const event: Event = JSON.parse(item);
if (event.type === 'chat_history') {
const chatMessageEvent = event as ChatHistoryEvent;
setDisplayedChatHistory(chatMessageEvent.value);
}
if (event.type === 'delta') {
const chatMessageEvent = event as ChatMessageEvent;
chatResponse += chatMessageEvent.value;
setCurrentResponse(chatResponse);
}
});
}
We’ve left out some cleanup/error handling code (to clear, initialize the state variables before/after requests, handle failure, etc…) — you can see more in the example.
Finally, we can render it (note this refers to additional state variables that are set/unset outside of the code above, as well as a ChatMessage react component that simply displays a chat message with the appropriate icon.
<!-- More to illustrates the example -->
<div className="flex-1 overflow-y-auto p-4 hide-scrollbar" id={VIEW_END_ID}>
{displayedChatHistory.map((message, i) => (
<ChatMessage
message={message}
key={i}
/>
))}
{isChatWaiting && (
<ChatMessage
message={{
role: ChatItem.role.USER,
content: currentPrompt,
type: ChatItem.type.TEXT
}}
/>
)}
{isChatWaiting && (
<ChatMessage
message={{
content: currentResponse,
type: ChatItem.type.TEXT,
role: ChatItem.role.ASSISTANT
}}
/>
)}
</div>
<!-- Note: We've left out the isChatWaiting and currentPrompt state fields above,
see StreamingChatbot.tsx for the full implementation. -->
We finally have our whole app! For all the code click here.
Alternate SSE Tooling
Note that what we presented above is just one approach to streaming with FastAPI/react/Burr. There are a host of other tools you can use, including:
- The EventSource API — standard but limited to get/ requests
- The FetchEventSource API (appears unmaintained, but well built)
As well as a host of other blog posts (that are awesome! I read these to get started). These will give you a better sense of architecture as well.
Wrapping Up
In this post we covered a lot — we went over Burr, FastAPI, and React, talked about how to build a streaming agentic chatbot using the OpenAI API, built out the entire stack, and streamed data all the way through! While you may not use every one of the technologies, the individual pieces should be able to work on their own.
To download and play with this example, you can run:
pip install "burr[start]"
burr # will open up in a new window
Note you’ll need an API key from OpenAI for this specific demo. You will find the Burr + FastAPI code here and the frontend code here.
Additional Resources
- Github repository for Burr (give us a star if you like what you see!)
- FastAPI guide
- Example + README
How to Build a Streaming Agent with Burr, FastAPI, and React was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
Originally appeared here:
How to Build a Streaming Agent with Burr, FastAPI, and React
Go Here to Read this Fast! How to Build a Streaming Agent with Burr, FastAPI, and React