Nikola Milosevic (Data Warrior)

Use Qdrant, NVidia NIM API, or Llama 3 8B locally for your local GenAI assistant
On the 23rd of May, I received an email from a person at Nvidia inviting me to the Generative AI Agents Developer Contest by NVIDIA and LangChain. My first thought was that it is quite a little time, and given we had a baby recently and my parents were supposed to come, I would not have time to participate. But then second thoughts came, and I decided that I could code something and submit it. I thought about what I could make for a few days, and one idea stuck with me — an Open-Source Generative Search Engine that lets you interact with local files. Microsoft Copilot already provides something like this, but I thought I could make an open-source version, for fun, and share a bit of learnings that I gathered during the quick coding of the system.
System Design
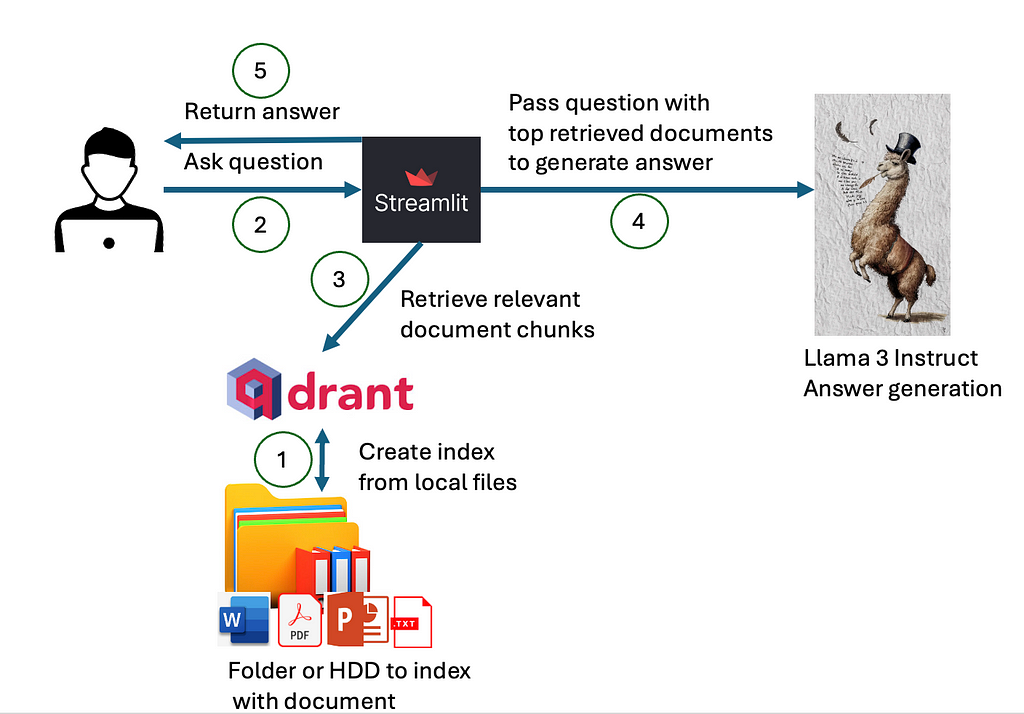
In order to build a local generative search engine or assistant, we would need several components:
- An index with the content of the local files, with an information retrieval engine to retrieve the most relevant documents for a given query/question.
- A language model to use selected content from local documents and generate a summarized answer
- A user interface
How the components interact is presented in a diagram below.
First, we need to index our local files into the index that can be queried for the content of the local files. Then, when the user asks a question, we would use the created index, with some of the asymmetric paragraph or document embeddings to retrieve the most relevant documents that may contain the answer. The content of these documents and the question are passed to the deployed large language model, which would use the content of given documents to generate answers. In the instruction prompt, we would ask a large language model to also return references to the used document. Ultimately, everything will be visualized to the user on the user interface.
Now, let’s have a look in more detail at each of the components.
Semantic Index
We are building a semantic index that will provide us with the most relevant documents based on the similarity of the file’s content and a given query. To create such an index we will use Qdrant as a vector store. Interestingly, a Qdrant client library does not require a full installation of Qdrant server and can do a similarity of documents that fit in working memory (RAM). Therefore, all we need to do is to pip install Qdrant client.
We can initialize Qdrant in the following way (note that the hf parameter is later defined due to the story flow, but with Qdrant client you already need to define which vectorization method and metric is being used):
from qdrant_client import QdrantClient
from qdrant_client.models import Distance, VectorParams
client = QdrantClient(path="qdrant/")
collection_name = "MyCollection"
if client.collection_exists(collection_name):
client.delete_collection(collection_name)
client.create_collection(collection_name,vectors_config=VectorParams(size=768, distance=Distance.DOT))
qdrant = Qdrant(client, collection_name, hf)
In order to create a vector index, we will have to embed the documents on the hard drive. For embeddings, we will have to select the right embedding method and the right vector comparison metric. Several paragraph, sentence, or word embedding methods can be used, with varied results. The main issue with creating vector search, based on the documents, is the problem of asymmetric search. Asymmetric search problems are common to information retrieval and happen when one has short queries and long documents. Word or sentence embeddings are often fine-tuned to provide similarity scores based on documents of similar size (sentences, or paragraphs). Once that is not the case, the proper information retrieval may fail.
However, we can find an embedding methodology that would work well on asymmetric search problems. For example, models fine-tuned on the MSMARCO dataset usually work well. MSMARCO dataset is based on Bing Search queries and documents and has been released by Microsoft. Therefore, it is ideal for the problem we are dealing with.
For this particular implementation, I have selected an already fine-tuned model, called:
sentence-transformers/msmarco-bert-base-dot-v5
This model is based on BERT and it was fine-tuned using dot product as a similarity metric. We have already initialized qdrant client to use dot product as a similarity metric in line (note this model has dimension of 768):
client.create_collection(collection_name,vectors_config=VectorParams(size=768, distance=Distance.DOT))
We could use other metrics, such as cosine similarity, however, given this model is fine-tuned using dot product, we will get the best performance using this metric. On top of that, thinking geometrically: Cosine similarity focuses solely on the difference in angles, whereas the dot product takes into account both angle and magnitude. By normalizing data to have uniform magnitudes, the two measures become equivalent. In situations where ignoring magnitude is beneficial, cosine similarity is useful. However, the dot product is a more suitable similarity measure if the magnitude is significant.
The code for initializing the MSMarco model is (in case you have available GPU, use it. by all means):
model_name = "sentence-transformers/msmarco-bert-base-dot-v5"
model_kwargs = {'device': 'cpu'}
encode_kwargs = {'normalize_embeddings': True}
hf = HuggingFaceEmbeddings(
model_name=model_name,
model_kwargs=model_kwargs,
encode_kwargs=encode_kwargs
)
The next problem: we need to deal with is that BERT-like models have limited context size, due to the quadratic memory requirements of transformer models. In the case of many BERT-like models, this context size is set to 512 tokens. There are two options: (1) we can base our answer only on the first 512 tokens and ignore the rest of the document, or (2) create an index, where one document will be split into multiple chunks and stored in the index as chunks. In the first case, we would lose a lot of important information, and therefore, we picked the second variant. To chunk documents, we can use a prebuilt chunker from LangChain:
from langchain_text_splitters import TokenTextSplitter
text_splitter = TokenTextSplitter(chunk_size=500, chunk_overlap=50)
texts = text_splitter.split_text(file_content)
metadata = []
for i in range(0,len(texts)):
metadata.append({"path":file})
qdrant.add_texts(texts,metadatas=metadata)
In the provided part of the code, we chunk text into the size of 500 tokens, with a window of 50 overlapping tokens. This way we keep a bit of context on the places where chunks end or begin. In the rest of the code, we create metadata with the document path on the user’s hard disk and add these chunks with metadata to the index.
However, before we add the content of the files to the index, we need to read it. Even before we read files, we need to get all the files we need to index. For the sake of simplicity, in this project, the user can define a folder that he/she would like to index. The indexer retrieves all the files from that folder and its subfolder in a recursive manner and indexes files that are supported (we will look at how to support PDF, Word, PPT, and TXT).
We can retrieve all the files in a given folder and its subfolder in a recursive way:
def get_files(dir):
file_list = []
for f in listdir(dir):
if isfile(join(dir,f)):
file_list.append(join(dir,f))
elif isdir(join(dir,f)):
file_list= file_list + get_files(join(dir,f))
return file_list
Once all the files are retrieved in the list, we can read the content of files containing text. In this tool, for start, we will support MS Word documents (with extension “.docx”), PDF documents, MS PowerPoint presentations (with extension “.pptx”), and plain text files (with extension “.txt”).
In order to read MS Word documents, we can use the docx-python library. The function reading documents into a string variable would look something like this:
import docx
def getTextFromWord(filename):
doc = docx.Document(filename)
fullText = []
for para in doc.paragraphs:
fullText.append(para.text)
return 'n'.join(fullText)
A similar thing can be done with MS PowerPoint files. For this, we will need to download and install the pptx-python library and write a function like this:
from pptx import Presentation
def getTextFromPPTX(filename):
prs = Presentation(filename)
fullText = []
for slide in prs.slides:
for shape in slide.shapes:
fullText.append(shape.text)
return 'n'.join(fullText)
Reading text files is pretty simple:
f = open(file,'r')
file_content = f.read()
f.close()
For PDF files we will in this case use the PyPDF2 library:
reader = PyPDF2.PdfReader(file)
for i in range(0,len(reader.pages)):
file_content = file_content + " "+reader.pages[i].extract_text()
Finally, the whole indexing function would look something like this:
file_content = ""
for file in onlyfiles:
file_content = ""
if file.endswith(".pdf"):
print("indexing "+file)
reader = PyPDF2.PdfReader(file)
for i in range(0,len(reader.pages)):
file_content = file_content + " "+reader.pages[i].extract_text()
elif file.endswith(".txt"):
print("indexing " + file)
f = open(file,'r')
file_content = f.read()
f.close()
elif file.endswith(".docx"):
print("indexing " + file)
file_content = getTextFromWord(file)
elif file.endswith(".pptx"):
print("indexing " + file)
file_content = getTextFromPPTX(file)
else:
continue
text_splitter = TokenTextSplitter(chunk_size=500, chunk_overlap=50)
texts = text_splitter.split_text(file_content)
metadata = []
for i in range(0,len(texts)):
metadata.append({"path":file})
qdrant.add_texts(texts,metadatas=metadata)
print(onlyfiles)
print("Finished indexing!")
As we stated, we use TokenTextSplitter from LangChain to create chunks of 500 tokens with 50 token overlap. Now, when we have created an index, we can create a web service for querying it and generating answers.
Generative Search API
We will create a web service using FastAPI to host our generative search engine. The API will access the Qdrant client with the indexed data we created in the previous section, perform a search using a vector similarity metric, use the top chunks to generate an answer with the Llama 3 model, and finally provide the answer back to the user.
In order to initialize and import libraries for the generative search component, we can use the following code:
from fastapi import FastAPI
from langchain_community.embeddings import HuggingFaceEmbeddings
from langchain_qdrant import Qdrant
from qdrant_client import QdrantClient
from pydantic import BaseModel
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM
import environment_var
import os
from openai import OpenAI
class Item(BaseModel):
query: str
def __init__(self, query: str) -> None:
super().__init__(query=query)
As previously mentioned, we are using FastAPI to create the API interface. We will utilize the qdrant_client library to access the indexed data we created and leverage the langchain_qdrant library for additional support. For embeddings and loading Llama 3 models locally, we will use the PyTorch and Transformers libraries. Additionally, we will make calls to the NVIDIA NIM API using the OpenAI library, with the API keys stored in the environment_var (for both Nvidia and HuggingFace) file we created.
We create class Item, derived from BaseModel in Pydantic to pass as parameters to request functions. It will have one field, called query.
Now, we can start initializing our machine-learning models
model_name = "sentence-transformers/msmarco-bert-base-dot-v5"
model_kwargs = {'device': 'cpu'}
encode_kwargs = {'normalize_embeddings': True}
hf = HuggingFaceEmbeddings(
model_name=model_name,
model_kwargs=model_kwargs,
encode_kwargs=encode_kwargs
)
os.environ["HF_TOKEN"] = environment_var.hf_token
use_nvidia_api = False
use_quantized = True
if environment_var.nvidia_key !="":
client_ai = OpenAI(
base_url="https://integrate.api.nvidia.com/v1",
api_key=environment_var.nvidia_key
)
use_nvidia_api = True
elif use_quantized:
model_id = "Kameshr/LLAMA-3-Quantized"
tokenizer = AutoTokenizer.from_pretrained(model_id)
model = AutoModelForCausalLM.from_pretrained(
model_id,
torch_dtype=torch.float16,
device_map="auto",
)
else:
model_id = "meta-llama/Meta-Llama-3-8B-Instruct"
tokenizer = AutoTokenizer.from_pretrained(model_id)
model = AutoModelForCausalLM.from_pretrained(
model_id,
torch_dtype=torch.float16,
device_map="auto",
)
In the first few lines, we load weights for the BERT-based model fine-tuned on MSMARCO data that we have also used to index our documents.
Then, we check whether nvidia_key is provided, and if it is, we use the OpenAI library to call NVIDIA NIM API. When we use NVIDIA NIM API, we can use a big version of the Llama 3 instruct model, with 70B parameters. In case nvidia_key is not provided, we will load Llama 3 locally. However, locally, at least for most consumer electronics, it would not be possible to load the 70B parameters model. Therefore, we will either load the Llama 3 8B parameter model or the Llama 3 8B parameters model that has been additionally quantized. With quantization, we save space and enable model execution on less RAM. For example, Llama 3 8B usually needs about 14GB of GPU RAM, while Llama 3 8B quantized would be able to run on 6GB of GPU RAM. Therefore, we load either a full or quantized model depending on a parameter.
We can now initialize the Qdrant client
client = QdrantClient(path="qdrant/")
collection_name = "MyCollection"
qdrant = Qdrant(client, collection_name, hf)
Also, FastAPI and create a first mock GET function
app = FastAPI()
@app.get("/")
async def root():
return {"message": "Hello World"}
This function would return JSON in format {“message”:”Hello World”}
However, for this API to be functional, we will create two functions, one that performs only semantic search, while the other would perform search and then put the top 10 chunks as a context and generate an answer, referencing documents it used.
@app.post("/search")
def search(Item:Item):
query = Item.query
search_result = qdrant.similarity_search(
query=query, k=10
)
i = 0
list_res = []
for res in search_result:
list_res.append({"id":i,"path":res.metadata.get("path"),"content":res.page_content})
return list_res
@app.post("/ask_localai")
async def ask_localai(Item:Item):
query = Item.query
search_result = qdrant.similarity_search(
query=query, k=10
)
i = 0
list_res = []
context = ""
mappings = {}
i = 0
for res in search_result:
context = context + str(i)+"n"+res.page_content+"nn"
mappings[i] = res.metadata.get("path")
list_res.append({"id":i,"path":res.metadata.get("path"),"content":res.page_content})
i = i +1
rolemsg = {"role": "system",
"content": "Answer user's question using documents given in the context. In the context are documents that should contain an answer. Please always reference document id (in squere brackets, for example [0],[1]) of the document that was used to make a claim. Use as many citations and documents as it is necessary to answer question."}
messages = [
rolemsg,
{"role": "user", "content": "Documents:n"+context+"nnQuestion: "+query},
]
if use_nvidia_api:
completion = client_ai.chat.completions.create(
model="meta/llama3-70b-instruct",
messages=messages,
temperature=0.5,
top_p=1,
max_tokens=1024,
stream=False
)
response = completion.choices[0].message.content
else:
input_ids = tokenizer.apply_chat_template(
messages,
add_generation_prompt=True,
return_tensors="pt"
).to(model.device)
terminators = [
tokenizer.eos_token_id,
tokenizer.convert_tokens_to_ids("<|eot_id|>")
]
outputs = model.generate(
input_ids,
max_new_tokens=256,
eos_token_id=terminators,
do_sample=True,
temperature=0.2,
top_p=0.9,
)
response = tokenizer.decode(outputs[0][input_ids.shape[-1]:])
return {"context":list_res,"answer":response}
Both functions are POST methods, and we use our Item class to pass the query via JSON body. The first method returns the 10 most similar document chunks, with the path, and assigns document ID from 0–9. Therefore, it just performs the plain semantic search using dot product as similarity metric (this was defined during indexing in Qdrant — remember line containing distance=Distance.DOT).
The second function, called ask_localai is slightly more complex. It contains a search mechanism from the first method (therefore it may be easier to go through code there to understand semantic search), but adds a generative part. It creates a prompt for Llama 3, containing instructions in a system prompt message saying:
Answer the user’s question using the documents given in the context. In the context are documents that should contain an answer. Please always reference the document ID (in square brackets, for example [0],[1]) of the document that was used to make a claim. Use as many citations and documents as it is necessary to answer a question.
The user’s message contains a list of documents structured as an ID (0–9) followed by the document chunk on the next line. To maintain the mapping between IDs and document paths, we create a list called list_res, which includes the ID, path, and content. The user prompt ends with the word “Question” followed by the user’s query.
The response contains context and generated answer. However, the answer is again generated by either the Llama 3 70B model (using NVIDIA NIM API), local Llama 3 8B, or local Llama 3 8B quantized depending on the passed parameters.
The API can be started from a separate file containing the following lines of code (given, that our generative component is in a file called api.py, as the first argument in Uvicorn maps to the file name):
import uvicorn
if __name__=="__main__":
uvicorn.run("api:app",host='0.0.0.0', port=8000, reload=False, workers=3)
Simple User Interface
The final component of our local generative search engine is the user interface. We will build a simple user interface using Streamlit, which will include an input bar, a search button, a section for displaying the generated answer, and a list of referenced documents that can be opened or downloaded.
The whole code for the user interface in Streamlit has less than 45 lines of code (44 to be exact):
import re
import streamlit as st
import requests
import json
st.title('_:blue[Local GenAI Search]_ :sunglasses:')
question = st.text_input("Ask a question based on your local files", "")
if st.button("Ask a question"):
st.write("The current question is "", question+""")
url = "http://127.0.0.1:8000/ask_localai"
payload = json.dumps({
"query": question
})
headers = {
'Accept': 'application/json',
'Content-Type': 'application/json'
}
response = requests.request("POST", url, headers=headers, data=payload)
answer = json.loads(response.text)["answer"]
rege = re.compile("[Document [0-9]+]|[[0-9]+]")
m = rege.findall(answer)
num = []
for n in m:
num = num + [int(s) for s in re.findall(r'bd+b', n)]
st.markdown(answer)
documents = json.loads(response.text)['context']
show_docs = []
for n in num:
for doc in documents:
if int(doc['id']) == n:
show_docs.append(doc)
a = 1244
for doc in show_docs:
with st.expander(str(doc['id'])+" - "+doc['path']):
st.write(doc['content'])
with open(doc['path'], 'rb') as f:
st.download_button("Downlaod file", f, file_name=doc['path'].split('/')[-1],key=a
)
a = a + 1
It will all end up looking like this:

Availability
The entire code for the described project is available on GitHub, at https://github.com/nikolamilosevic86/local-genAI-search. In the past, I have worked on several generative search projects, on which there have also been some publications. You can have a look at https://www.thinkmind.org/library/INTERNET/INTERNET_2024/internet_2024_1_10_48001.html or https://arxiv.org/abs/2402.18589.
Conclusion
This article showed how one can leverage generative AI with semantic search using Qdrant. It is generally a Retrieval-Augmented Generation (RAG) pipeline over local files with instructions to reference claims to the local documents. The whole code is about 300 lines long, and we have even added complexity by giving a choice to the user between 3 different Llama 3 models. For this use case, both 8B and 70B parameter models work quite well.
I wanted to explain the steps I did, in case this can be helpful for someone in the future. However, if you want to use this particular tool, the easiest way to do so is by just getting it from GitHub, it is all open source!
How to Build a Generative Search Engine for Your Local Files Using Llama 3 was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
Originally appeared here:
How to Build a Generative Search Engine for Your Local Files Using Llama 3