A friendly introduction to testing machine learning projects, by using standard libraries such as Pytest and Pytest-cov
Introduction
Testing is a crucial component of software development, but in my experience, it is widely neglected in machine learning projects. Lots of people know they should test their code, but not many people know how to do and actually do it.
This guide aims to introduce you to the essentials of testing various parts of a machine learning pipeline. We’ll focus on fine-tuning BERT for text classification on the IMDb dataset and using the industry standard libraries like pytest and pytest-cov for testing.
I strongly advise you to follow the code on this Github repository:
Project overview
Here is a brief overview of the project.
bert-text-classification/
├── src/
│ ├── data_loader.py
│ ├── evaluation.py
│ ├── main.py
│ ├── trainer.py
│ └── utils.py
├── tests/
│ ├── conftest.py
│ ├── test_data_loader.py
│ ├── test_evaluation.py
│ ├── test_main.py
│ ├── test_trainer.py
│ └── test_utils.py
├── models/
│ └── imdb_bert_finetuned.pth
├── environment.yml
├── requirements.txt
├── README.md
└── setup.py
A common practice is to split the code into several parts:
- src: contains the main files we use to load the datasets, train and evaluate models.
- tests: It contains different python scripts. Most of the time, there is one test file for each script. I personally use the following convention: if the script you want to test is called XXX.py then the corresponding test script is called test_XXX.py and located in the tests folder.
For example if you want to test the evaluation.py file, I use the test_evaluation.py file.
NB: In the tests folder, you can notice a conftest.py file. This file is not testing function per proper say, but it contains some configuration informations about the test, especially fixtures, that we will explain a bit later.
How to get started
You can only read this article, but I strongly advise you to clone the repository and start playing with the code, as we always learn better by being active. To do so, you need to clone the github repository, create an environment, and get a model.
# clone github repo
git clone https://github.com/FrancoisPorcher/awesome-ai-tutorials/tree/main
# enter corresponding folder
cd MLOps/how_to_test/
# create environment
conda env create -f environment.yml
conda activate how_to_test
You will also need a model to run the evaluations. To reproduce my results, you can run the main file. The training should take between 2 and 20 min (depending if you have CUDA, MPS, or a CPU).
python src/main.py
If you do not want to fine-tune BERT (but I strongly advise you to fine tune BERT yourself), you can take a stock version of BERT, and add a linear layer to get 2 classes with the following command:
from transformers import BertForSequenceClassification
model = BertForSequenceClassification.from_pretrained(
"bert-base-uncased", num_labels=2
)
Now you are all set!
Let’s write some tests:
But first, a quick introduction to Pytest.
What Pytest is and how to use it?
pytest is a standard and mature testing framework in the industry that makes it easy to write tests.
Something that is awesome with pytest is that you can test at different levels of granularity: a single function, a script, or the entire project. Let’s learn how to do the 3 options.
What does a test look like?
A test is a function that tests the behaviour of an other function. The convention is that if you want to test the function called foo , you call your test function test_foo .
We then define several tests, to check whether the function we are testing is behaving as we want.
Let’s use an example to clarify ideas:
In the data_loader.py script we are using a very standard function called clean_text , which removes capital letters and white spaces, defined as follows:
def clean_text(text: str) -> str:
"""
Clean the input text by converting it to lowercase and stripping whitespace.
Args:
text (str): The text to clean.
Returns:
str: The cleaned text.
"""
return text.lower().strip()
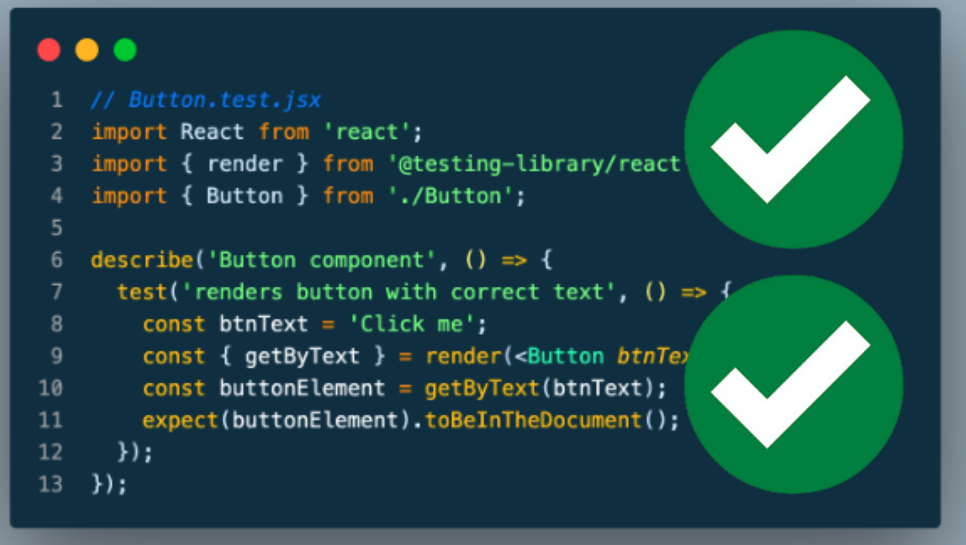
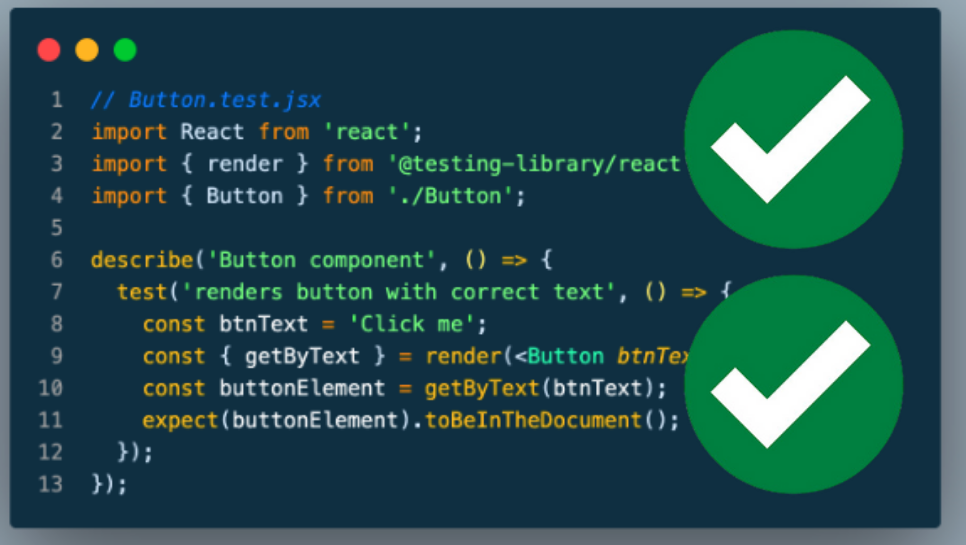
We want to make sure that this function behaves well, so in the test_data_loader.py file we can write a function called test_clean_text
from src.data_loader import clean_text
def test_clean_text():
# test capital letters
assert clean_text("HeLlo, WoRlD!") == "hello, world!"
# test spaces removed
assert clean_text(" Spaces ") == "spaces"
# test empty string
assert clean_text("") == ""
Note that we use the function assert here. If the assertion is True, nothing happens, if it’s False, AssertionError is raised.
Now let’s call the test. Run the following command in your terminal.
pytest tests/test_data_loader.py::test_clean_text
This terminal command means that you are using pytest to run the test, most specifically the test_data_loader.py script located in the tests folder, and you only want to run one test which is test_clean_text .
If the test passes, this is what you should get:

What happens when a test does not pass?
For the sake of this example let’s imagine I modify the test_clean_text function to this:
def clean_text(text: str) -> str:
# return text.lower().strip()
return text.lower()
Now the function does not remove spaces anymore and is going to fail the tests. This is what we get when running the test again:
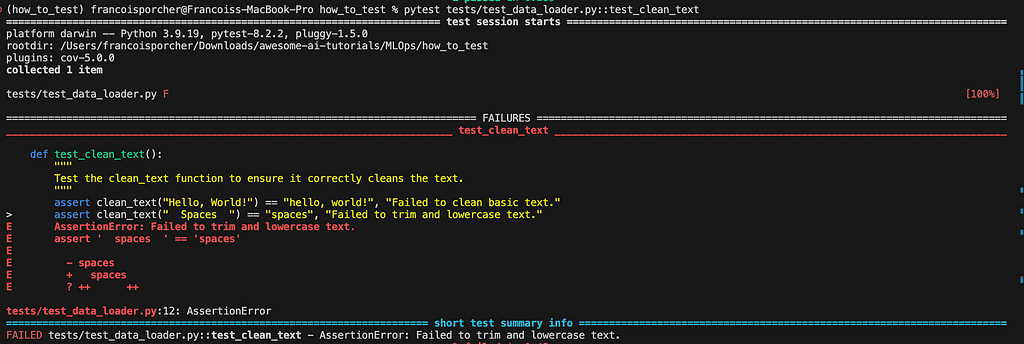
This time we know why the test failed. Great!
Why would we even want to test a single function?
Well, testing can take a lot of time. For a small project like this one, evaluating on the whole IMDb dataset can already take several minutes. Sometimes we just want to test a single behaviour without having to retest the whole codebase each time.
Now let’s move to the next level of granularity: testing a script.
How to test a whole script?
Now let’s complexify our data_loader.py script and add a tokenize_text function, which takes as input a string, or a list of string, and outputs the tokenized version of the input.
# src/data_loader.py
import torch
from transformers import BertTokenizer
def clean_text(text: str) -> str:
"""
Clean the input text by converting it to lowercase and stripping whitespace.
Args:
text (str): The text to clean.
Returns:
str: The cleaned text.
"""
return text.lower().strip()
def tokenize_text(
text: str, tokenizer: BertTokenizer, max_length: int
) -> Dict[str, torch.Tensor]:
"""
Tokenize a single text using the BERT tokenizer.
Args:
text (str): The text to tokenize.
tokenizer (BertTokenizer): The tokenizer to use.
max_length (int): The maximum length of the tokenized sequence.
Returns:
Dict[str, torch.Tensor]: A dictionary containing the tokenized data.
"""
return tokenizer(
text,
padding="max_length",
truncation=True,
max_length=max_length,
return_tensors="pt",
)
Just so you can understand a bit more what this function does, let’s try with an example:
from transformers import BertTokenizer
tokenizer = BertTokenizer.from_pretrained("bert-base-uncased")
txt = ["Hello, @! World! qwefqwef"]
tokenize_text(txt, tokenizer=tokenizer, max_length=16)
This will output the following result:
{'input_ids': tensor([[ 101, 7592, 1010, 1030, 999, 2088, 999, 1053, 8545, 2546, 4160, 8545,2546, 102, 0, 0]]),
'token_type_ids': tensor([[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]]),
'attention_mask': tensor([[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 0]])}
- max_length: is the maximum length a sequence can have. In this case we chose 16, but we can see that the sequence is of length 14, so we can see that the 2 last tokens are padded.
- input_ids: Each token is converted into its associated id, which are the worlds that are part of the vocabulary. NB: token 101 is the token CLS, and token_id 102 is the token SEP. These 2 tokens mark the beginning and the end of a sentence. Read the Attention is all your need paper for more details.
- token_type_ids: It’s not very important. If you feed 2 sequences as input, you will have 1 values for the second sentence.
- attention_mask: This tells the model which tokens it needs to attend in the self attention mechanism. Because the sentence is padded, the attention mechanism does not need to attend the 2 last tokens, so there are 0 there.
Now let’s write our test_tokenize_text function that will check that the tokenize_text function behaves properly:
def test_tokenize_text():
"""
Test the tokenize_text function to ensure it correctly tokenizes text using BERT tokenizer.
"""
tokenizer = BertTokenizer.from_pretrained("bert-base-uncased")
# Example input texts
txt = ["Hello, @! World!",
"Spaces "]
# Tokenize the text
max_length = 128
res = tokenize_text(text=txt, tokenizer=tokenizer, max_length=max_length)
# let's test that the output is a dictionary and that the keys are correct
assert all(key in res for key in ["input_ids", "token_type_ids", "attention_mask"]), "Missing keys in the output dictionary."
# let's check the dimensions of the output tensors
assert res["input_ids"].shape[0] == len(txt), "Incorrect number of input_ids."
assert res['input_ids'].shape[1] == max_length, "Incorrect number of tokens."
# let's check that all the associated tensors are pytorch tensors
assert all(isinstance(res[key], torch.Tensor) for key in res), "Not all values are PyTorch tensors."
Now let’s run the full test for the test_data_loader.py file, that now has 2 functions:
- test_tokenize_text
- test_clean_text
You can run the full test using this command from terminal
pytest tests/test_data_loader.py
And you should get this result:

Congrats! You now know how to test a whole script. Let’s move on to final leve, testing the full codebase.
How to test a whole codebase?
Continuing the same reasoning, we can write other tests for each script, and you should have a similar structure:
├── tests/
│ ├── conftest.py
│ ├── test_data_loader.py
│ ├── test_evaluation.py
│ ├── test_main.py
│ ├── test_trainer.py
│ └── test_utils.py
Now notice that in all these test functions, some variables are constant. For example the tokenizer we use is the same across all scripts. Pytest has a nice way to handle this with Fixtures.
Fixtures are a way to set up some context or state before running tests and to clean up afterward. They provide a mechanism to manage test dependencies and inject reusable code into tests.
Fixtures are defined using the @pytest.fixture decorator.
The tokenizer is a good example of fixture we can use. For that, let’s add it to theconftest.py file located in the tests folder:
import pytest
from transformers import BertTokenizer
@pytest.fixture()
def bert_tokenizer():
"""Fixture to initialize the BERT tokenizer."""
return BertTokenizer.from_pretrained("bert-base-uncased")
And now in the test_data_loader.py file, we can call the fixture bert_tokenizer in the argument of test_tokenize_text.
def test_tokenize_text(bert_tokenizer):
"""
Test the tokenize_text function to ensure it correctly tokenizes text using BERT tokenizer.
"""
tokenizer = bert_tokenizer
# Example input texts
txt = ["Hello, @! World!",
"Spaces "]
# Tokenize the text
max_length = 128
res = tokenize_text(text=txt, tokenizer=tokenizer, max_length=max_length)
# let's test that the output is a dictionary and that the keys are correct
assert all(key in res for key in ["input_ids", "token_type_ids", "attention_mask"]), "Missing keys in the output dictionary."
# let's check the dimensions of the output tensors
assert res["input_ids"].shape[0] == len(txt), "Incorrect number of input_ids."
assert res['input_ids'].shape[1] == max_length, "Incorrect number of tokens."
# let's check that all the associated tensors are pytorch tensors
assert all(isinstance(res[key], torch.Tensor) for key in res), "Not all values are PyTorch tensors."
Fixtures are a very powerful and versatile tool. If you want to learn more about them, the official doc is your go-to resource. But at least now, you have the tools at your disposal to cover most ML testing.
Let’s run the whole codebase with the following command from the terminal:
pytest tests
And you should get the following message:

Congratulations!
How to measure test coverage with Pytest-cov?
In the previous sections we have learned how to test code. In large projects, it is important to measure the coverage of your tests. In other words, how much of your code is tested.
pytest-cov is a plugin for pytest that generates test coverage reports.
That being said, do not get fooled by the coverage percentage. It is not because you have 100% coverage that your code is bug-free. It is just a tool for you to identify which parts of your code need more testing.
You can run the following command to generate a coverage report from terminal:
pytest --cov=src --cov-report=html tests/
And you should get this:
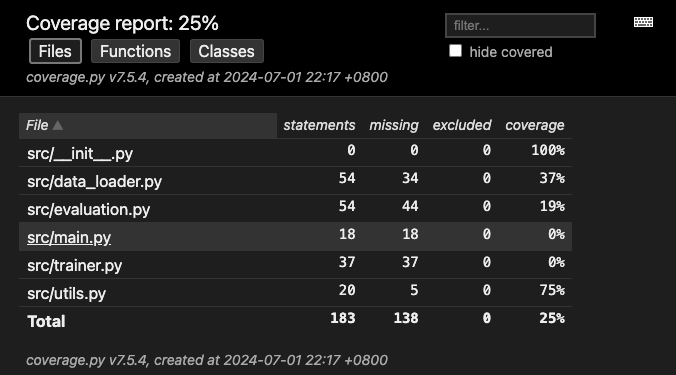
Let’s look at how to read it:
- Statements: total number of executable statements in the code. It counts all the lines of code that can be executed, including conditionals, loops, and function calls.
- Missing: This indicates the number of statements that were not executed during the test run. These are the lines of code that were not covered by any test.
- Coverage: percentage of the total statements that were executed during the tests. It is calculated by dividing the number of executed statements by the total number of statements.
- Excluded: This refers to the lines of code that have been explicitly excluded from coverage measurement. This is useful for ignoring code that is not relevant for test coverage, such as debugging statements.
We can see that the coverage for the main.py file is 0%, it’s normal, we did not write a test_main.py file.
We can also see that there is only 19% of the evaluation code being tested, and it gives us an idea on where we should focus first.
Congratulations, you’ve made it!
Thanks for reading! Before you go:
For more awesome tutorials, check my compilation of AI tutorials on Github
You should get my articles in your inbox. Subscribe here.
If you want to have access to premium articles on Medium, you only need a membership for $5 a month. If you sign up with my link, you support me with a part of your fee without additional costs.
If you found this article insightful and beneficial, please consider following me and leaving a clap for more in-depth content! Your support helps me continue producing content that aids our collective understanding.
References
How Should You Test Your Machine Learning Project? A Beginner’s Guide was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
Originally appeared here:
How Should You Test Your Machine Learning Project? A Beginner’s Guide
Go Here to Read this Fast! How Should You Test Your Machine Learning Project? A Beginner’s Guide