Exploring learning curves and sample efficiency of Gemini Flash with code examples.

In most common Machine Learning and Natural Language Processing, achieving optimal performance often involves a trade-off between the amount of data used for training and the resulting model accuracy. This blog post explores the concept of sample efficiency in the context of fine-tuning Google’s Gemini Flash model using a PII masking dataset as a practical example. We’ll examine how fine-tuning with increasing amounts of data impacts the tuned model’s capabilities.
What is Sample Efficiency and Why Does it Matter?
Sample efficiency refers to a model’s ability to achieve high accuracy with a limited amount of training data. It’s a key aspect of ML development, especially when dealing with tasks or domains where large, labeled datasets might be scarce or expensive to acquire. A sample-efficient model can learn effectively from fewer examples, reducing the time, cost, and effort associated with data collection and training. LLMs were shown to be very sample efficient, even capable of doing in-context learning with few examples to significantly boost performance. The main motivation of this blog post is to explore this aspect using Gemini Flash as an example. We will evaluate this LLM under different settings and then plot the learning curves to understand how the amount of training data impacts the performance.

Our Experiment: Fine-tuning Gemini Flash for PII masking
To show the impact of sample efficiency, we’ll conduct an experiment focusing on fine-tuning Gemini Flash for PII masking. We’ll use a publicly available PII masking dataset from Hugging Face and evaluate the model’s performance under different fine-tuning scenarios:
- Zero-shot setting: Evaluating the pre-trained Gemini Flash model without any fine-tuning.
- Few-shot setting (3-shot): Providing the model with 3 examples before asking it to mask PII new text.
- Fine-tuned with 50 | 200 | 800 | 3200 | 6400 samples: Fine-tuning the model using small to larger dataset of PII/Masked pairs.
For each setting, we’ll evaluate the model’s performance on a fixed test set of 200 sentences, using the BLEU metric to measure the quality of the generated masked text. This metric assesses the overlap between the model’s output and masked sentence, providing a quantitative measure of masking accuracy.
Limitations:
It’s important to acknowledge that the findings of this small experiment might not directly generalize to other use cases or datasets. The optimal amount of data for fine-tuning depends on various factors, including the nature and complexity of the task, the quality of the data, and the specific characteristics of the base model.
My advice here is to take inspiration from the code presented in this post and either:
- Apply it directly to your use case if you already have data so you can see if your training curves are slowing down (meaning you are getting significant diminishing returns)
- Or, if you have no data, find a dataset for the same class of problems that you have (classification, NER, summarization) and a similar difficulty level so that you can use it to get an idea of how much data you need for your own task by plotting the learning curves.
Data
We will be using a PII (Personal Identifiable Information) masking dataset shared on Huggingface.
The dataset presents two pairs of texts, one original with PII and another one with all PII information masked.
Example:
Input :
A student’s assessment was found on device bearing IMEI: 06–184755–866851–3. The document falls under the various topics discussed in our Optimization curriculum. Can you please collect it?
Target:
A student’s assessment was found on device bearing IMEI: [PHONEIMEI]. The document falls under the various topics discussed in our [JOBAREA] curriculum. Can you please collect it?
The data is synthetic, so no real PII is actually shared here.
Our objective is to build a mapping from the source text to the target text to hide all PII automatically.
Data licence: https://huggingface.co/datasets/ai4privacy/pii-masking-200k/blob/main/license.md
Code Implementation
We’ll provide code snippets to facilitate the execution of this experiment. The code will leverage the Hugging Face datasets library for loading the PII masking dataset, the google.generativeai library for interacting with Gemini Flash, and the evaluate library for computing the BLEU score.
pip install transformers datasets evaluate google-generativeai python-dotenv sacrebleu
This snippet installs the required libraries for the project, including:
- datasets: Facilitates loading and processing datasets from Hugging Face.
- evaluate: Enables the use of evaluation metrics like SacreBLEU.
- google-generativeai: Allows interaction with Google’s Gemini API.
First, we do data some data loading and splitting:
# Import necessary libraries
from datasets import load_dataset
from google.generativeai.types import HarmCategory, HarmBlockThreshold
# Define GOOGLE_API_KEY as a global variable
# Function to load and split the dataset
def load_data(train_size: int, test_size: int):
"""
Loads the pii-masking-200k dataset and splits it into train and test sets.
Args:
train_size: The size of the training set.
test_size: The size of the test set.
Returns:
A tuple containing the train and test datasets.
"""
dataset = load_dataset("ai4privacy/pii-masking-200k")
dataset = dataset["train"].train_test_split(test_size=test_size, seed=42)
train_d = dataset["train"].select(range(train_size))
test_d = dataset["test"]
return train_d, test_d
First, we try zero-shot prompting for this task. This means we explain the task to the LLM and ask it to generate PII masked data from the original text. This is done using a prompt that lists all the tags that need to be masked.
We also parallelize the calls to the LLM api to speed up things a bit.
For the evaluation we use the BLEU score. It is a precision based metric that is commonly used in machine translation to compare the model output to the reference sentence. It has its limitations but is easy to apply and is suited to text-to-text tasks like the one we have at hand.
import google.generativeai as genai
from google.generativeai.types.content_types import ContentDict
from google.generativeai.types import HarmCategory, HarmBlockThreshold
from concurrent.futures import ThreadPoolExecutor
import evaluate
safety_settings = {
HarmCategory.HARM_CATEGORY_HATE_SPEECH: HarmBlockThreshold.BLOCK_NONE,
HarmCategory.HARM_CATEGORY_SEXUALLY_EXPLICIT: HarmBlockThreshold.BLOCK_NONE,
HarmCategory.HARM_CATEGORY_DANGEROUS_CONTENT: HarmBlockThreshold.BLOCK_NONE,
HarmCategory.HARM_CATEGORY_HARASSMENT: HarmBlockThreshold.BLOCK_NONE,
}
SYS_PROMPT = (
"Substitute all PII in this text for a generic label like [FIRSTNAME] (Between square brackets)n"
"Labels to substitute are PREFIX, FIRSTNAME, LASTNAME, DATE, TIME, "
"PHONEIMEI, USERNAME, GENDER, CITY, STATE, URL, JOBAREA, EMAIL, JOBTYPE, "
"COMPANYNAME, JOBTITLE, STREET, SECONDARYADDRESS, COUNTY, AGE, USERAGENT, "
"ACCOUNTNAME, ACCOUNTNUMBER, CURRENCYSYMBOL, AMOUNT, CREDITCARDISSUER, "
"CREDITCARDNUMBER, CREDITCARDCVV, PHONENUMBER, SEX, IP, ETHEREUMADDRESS, "
"BITCOINADDRESS, MIDDLENAME, IBAN, VEHICLEVRM, DOB, PIN, CURRENCY, "
"PASSWORD, CURRENCYNAME, LITECOINADDRESS, CURRENCYCODE, BUILDINGNUMBER, "
"ORDINALDIRECTION, MASKEDNUMBER, ZIPCODE, BIC, IPV4, IPV6, MAC, "
"NEARBYGPSCOORDINATE, VEHICLEVIN, EYECOLOR, HEIGHT, SSN, language"
)
# Function to evaluate the zero-shot setting
def evaluate_zero_shot(train_data, test_data, model_name="gemini-1.5-flash"):
"""
Evaluates the zero-shot performance of the model.
Args:
train_data: The training dataset (not used in zero-shot).
test_data: The test dataset.
model_name: The name of the model to use.
Returns:
The SacreBLEU score for the zero-shot setting.
"""
model = genai.GenerativeModel(model_name)
def map_zero_shot(text):
messages = [
ContentDict(
role="user",
parts=[f"{SYS_PROMPT}nText: {text}"],
),
]
response = model.generate_content(messages, safety_settings=safety_settings)
try:
return response.text
except ValueError:
print(response)
return ""
with ThreadPoolExecutor(max_workers=4) as executor:
predictions = list(
executor.map(
map_zero_shot,
[example["source_text"] for example in test_data],
)
)
references = [[example["target_text"]] for example in test_data]
sacrebleu = evaluate.load("sacrebleu")
sacrebleu_results = sacrebleu.compute(
predictions=predictions, references=references
)
print(f"Zero-shot SacreBLEU score: {sacrebleu_results['score']}")
return sacrebleu_results["score"]
Now, lets try to go further with prompting. In addition to explaining the task to the LLM, we will also show it three examples of what we expect it to do. This usually improves performance.
# Function to evaluate the few-shot setting
def evaluate_few_shot(train_data, test_data, model_name="gemini-1.5-flash"):
"""
Evaluates the few-shot performance of the model.
Args:
train_data: The training dataset.
test_data: The test dataset.
model_name: The name of the model to use.
Returns:
The SacreBLEU score for the few-shot setting.
"""
model = genai.GenerativeModel(model_name)
def map_few_shot(text, examples):
messages = [
ContentDict(
role="user",
parts=[SYS_PROMPT],
)
]
for example in examples:
messages.append(
ContentDict(role="user", parts=[f"Text: {example['source_text']}"]),
)
messages.append(
ContentDict(role="model", parts=[f"{example['target_text']}"])
)
messages.append(ContentDict(role="user", parts=[f"Text: {text}"]))
response = model.generate_content(messages, safety_settings=safety_settings)
try:
return response.text
except ValueError:
print(response)
return ""
few_shot_examples = train_data.select(range(3))
with ThreadPoolExecutor(max_workers=4) as executor:
predictions = list(
executor.map(
lambda example: map_few_shot(example["source_text"], few_shot_examples),
test_data,
)
)
references = [[example["target_text"]] for example in test_data]
sacrebleu = evaluate.load("sacrebleu")
sacrebleu_results = sacrebleu.compute(
predictions=predictions, references=references
)
print(f"3-shot SacreBLEU score: {sacrebleu_results['score']}")
return sacrebleu_results["score"]
Finally, we try fine-tuning. Here, we just use the managed service of the Gemini API. It is free for now so might as well take advantage of it. We use increasing amounts of data and compare the performance of each.
Running a tuning task can’t be easier: we just use the genai.create_tuned_model function with the data, number of epochs and learning rate and parameters.
The training task is asynchronous, which means we don’t have to wait for it. It gets queued and is usually done within 24 hours.
def finetune(train_data, finetune_size, model_name="gemini-1.5-flash"):
"""
Fine-tunes the model .
Args:
train_data: The training dataset.
finetune_size: The number of samples to use for fine-tuning.
model_name: The name of the base model to use for fine-tuning.
Returns:
The name of the tuned model.
"""
base_model = f"models/{model_name}-001-tuning"
tuning_data = [
{
"text_input": f"{SYS_PROMPT}nText: {example['source_text']}",
"output": example["target_text"],
}
for example in train_data.select(range(finetune_size))
]
print(len(tuning_data))
operation = genai.create_tuned_model(
display_name=f"tuned-{finetune_size}",
source_model=base_model,
epoch_count=2,
batch_size=4,
learning_rate=0.0001,
training_data=tuning_data,
)
You can check the status of the tuning tasks using this code snippet:
import google.generativeai as genai
for model_info in genai.list_tuned_models():
print(model_info.name)
print(model_info)
Summary of Findings:
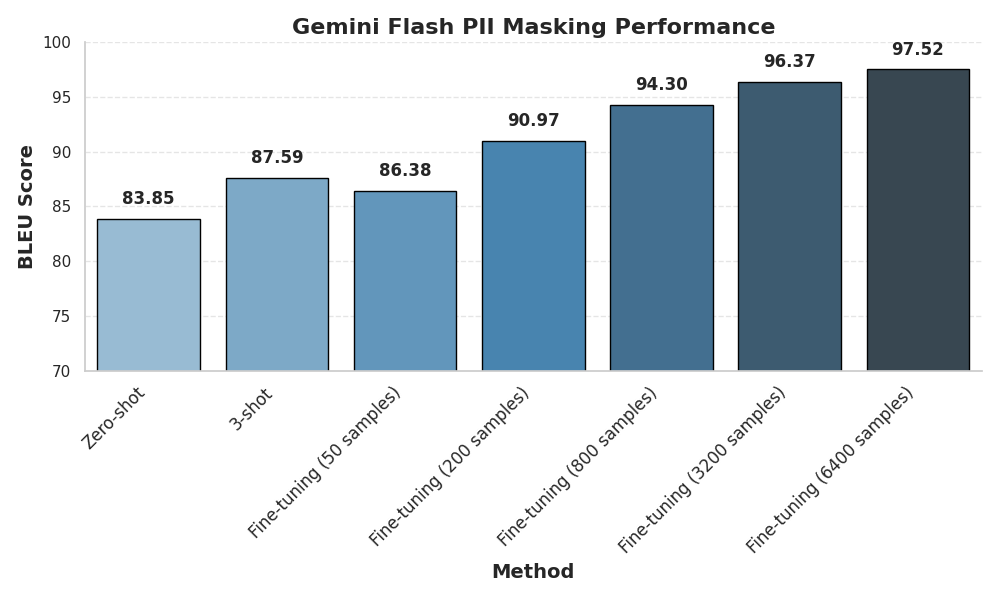
The PII masking algorithm demonstrates increasing performance with the addition of more training data for fine-tuning.
Zero-shot and Few-shot:
The zero-shot approach achieves a respectable BLEU score of 83.85, indicating a basic understanding of the task even without any training examples. However, providing just three examples (3-shot) improves the score to 87.59, showcasing the effectiveness of even limited examples with in-context learning of LLMs.
Fine-tuning:
Fine-tuning with a small dataset of 50 samples yields a BLEU score of 86.38, slightly lower than the 3-shot approach. However, as the training data increases, the performance improves significantly. With 200 samples, the BLEU score jumps to 90.97, and with 800 samples, it reaches a nice 94.30. The maximum score is reached at the maximum amount of data tested (6400 samples) at 97.52 BLEU score.
Conclusion:
The basic conclusion is that, unsurprisingly, you gain performance as you add more data. While the zero-shot and few-shot capabilities of Gemini Flash are impressive, demonstrating its ability to generalize to new tasks, fine-tuning with an big enough amount of data significantly enhances its accuracy. The only unexpected thing here is that few-shot prompting can sometimes outperform fine-tuning if the amount or quality of your training data is too low.
Key points:
- Fine-tuning can be necessary for high performance: Even a small amount of fine-tuning data can generate large improvements over zero-shot and few-shot approaches.
- More data generally leads to better results: As the size of the fine-tuning dataset increases, the tuned model’s ability to accurately mask PII also increases, as shown by the rising BLEU scores.
- Diminishing returns: While more data is generally better, there likely comes a point where the gains in performance start to plateau. Identifying this point can help better weigh the trade-off between labeling budget and tuned model quality.
In our example, the plateau starts at 3200 samples, anything above that will yields positive but diminishing returns.
How Much Data Do You Need to Fine-Tune Gemini? was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
Originally appeared here:
How Much Data Do You Need to Fine-Tune Gemini?
Go Here to Read this Fast! How Much Data Do You Need to Fine-Tune Gemini?