Guide to estimating time for training X-billion LLMs with Y trillion tokens and Z GPU compute

Intro
Every ML engineer working on LLM training has faced the question from a manager or product owner: ‘How long will it take to train this LLM?’
When I first tried to find an answer online, I was met with many articles covering generic topics — training techniques, model evaluation, and the like. But none of them addressed the core question I had: How do I actually estimate the time required for training?
Frustrated by the lack of clear, practical guidance, I decided to create my own. In this article, I’ll walk you through a simple, back-of-the-envelope method to quickly estimate how long it will take to train your LLM based on its size, data volume, and available GPU power
Approach
The goal is to quantify the computational requirements for processing data and updating model parameters during training in terms of FLOPs (floating point operations). Next, we estimate the system’s throughput in FLOPS (floating-point operations per second) based on the type and number of GPUs selected. Once everything is expressed on the same scale, we can easily calculate the time required to train the model.
So the final formula is pretty straightforward:
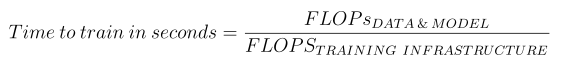
Let’s dive into knowing how to estimate all these variables.
FLOPs for Data and Model
The number of add-multiply operations per token for the forward pass for Transformer based LLM involves roughly the following amount of FLOPs:
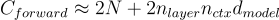
Where the factor of two comes from the multiply-accumulate operation used in matrix multiplication.
The backward pass requires approximately twice the compute of the forward pass. This is because, during backpropagation, we need to compute gradients for each weight in the model as well as gradients with respect to the intermediate activations, specifically the activations of each layer.
With this in mind, the floating-point operations per training token can be estimated as:
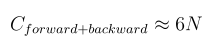
A more detailed math for deriving these estimates can be found in the paper from the authors here.
To sum up, training FLOPs for the transformer model of size N and dataset of P tokens can be estimated as:
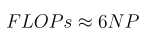
FLOPS of the training Infrastructure
Today, most LLMs are trained using GPU accelerators. Each GPU model (like Nvidia’s H100, A100, or V100) has its own FLOPS performance, which varies depending on the data type (form factor) being used. For instance, operations with FP64 are slower than those with FP32, and so on. The peak theoretical FLOPS for a specific GPU can usually be found on its product specification page (e.g., here for the H100).
However, the theoretical maximum FLOPS for a GPU is often less relevant in practice when training Large Language Models. That’s because these models are typically trained on thousands of interconnected GPUs, where the efficiency of network communication becomes crucial. If communication between devices becomes a bottleneck, it can drastically reduce the overall speed, making the system’s actual FLOPS much lower than expected.
To address this, it’s important to track a metric called model FLOPS utilization (MFU) — the ratio of the observed throughput to the theoretical maximum throughput, assuming the hardware is operating at peak efficiency with no memory or communication overhead. In practice, as the number of GPUs involved in training increases, MFU tends to decrease. Achieving an MFU above 50% is challenging with current setups.
For example, the authors of the LLaMA 3 paper reported an MFU of 38%, or 380 teraflops of throughput per GPU, when training with 16,000 GPUs.

To summarize, when performing a back-of-the-envelope calculation for model training, follow these steps:
- Identify the theoretical peak FLOPS for the data type your chosen GPU supports.
- Estimate the MFU (model FLOPS utilization) based on the number of GPUs and network topology, either through benchmarking or by referencing open-source data, such as reports from Meta engineers (as shown in the table above).
- Multiply the theoretical FLOPS by the MFU to get the average throughput per GPU.
- Multiply the result from step 3 by the total number of GPUs involved in training.
Case study with Llama 3 405B
Now, let’s put our back-of-the-envelope calculations to work and estimate how long it takes to train a 405B parameter model.
LLaMA 3.1 (405B) was trained on 15.6 trillion tokens — a massive dataset. The total FLOPs required to train a model of this size can be calculated as follows:
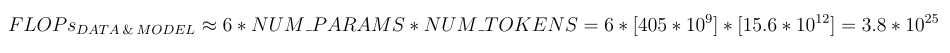
The authors used 16,000 H100 GPUs for training. According to the paper, the average throughput was 400 teraflops per GPU. This means the training infrastructure can deliver a total throughput of:
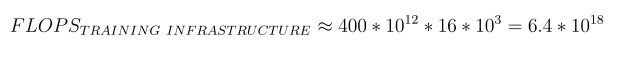
Finally, by dividing the total required FLOPs by the available throughput and converting the result into days (since what we really care about is the number of training days), we get:
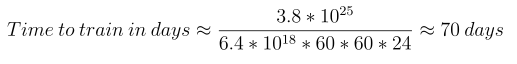
Bonus: How much does it cost to train Llama 3.1 405B?
Once you know the FLOPS per GPU in the training setup, you can calculate the total GPU hours required to train a model of a given size and dataset. You can then multiply this number by the cost per GPU hour from your cloud provider (or your own cost per GPU hour).
For example, if one H100 GPU costs approximately $2 per hour, the total cost to train this model would be around $52 million! The formula below explains how this number is derived:
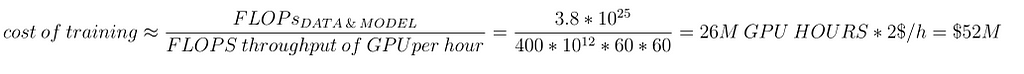
References
[1] Scaling Laws for Neural Language Models by Jared Kaplan et al.
[2]The Llama 3 Herd of Models by Llama Team, AI @ Meta
How Long Does It Take to Train the LLM From Scratch? was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
Originally appeared here:
How Long Does It Take to Train the LLM From Scratch?
Go Here to Read this Fast! How Long Does It Take to Train the LLM From Scratch?