

MusicLM fine-tuned on user preferences
What is MusicLM?
MusicLM, Google’s flagship text-to-music AI, was originally published in early 2023. Even in its basic version, it represented a major breakthrough and caught the music industry by surprise. However, a few weeks ago, MusicLM received a significant update. Here’s a side-by-side comparison for two selected prompts:
Prompt: “Dance music with a melodic synth line and arpeggiation”:
- Old MusicLM: https://google-research.github.io/seanet/musiclm/rlhf/audio_samples/musiclm-7.wav
- New MusicLM: https://google-research.github.io/seanet/musiclm/rlhf/audio_samples/musicrlhf-ru-7.wav
Prompt: “a nostalgic tune played by accordion band”
- Old MusicLM: https://google-research.github.io/seanet/musiclm/rlhf/audio_samples/musiclm-27.wav
- New MusicLM: https://google-research.github.io/seanet/musiclm/rlhf/audio_samples/musicrlhf-ru-27.wav
This increase in quality can be attributed to a new paper by Google Research titled: “MusicRL: Aligning Music Generation to Human Preferences”. Apparently, this upgrade was considered so significant that they decided to rename the model. However, under the hood, MusicRL is identical to MusicLM in its key architecture. The only difference: Finetuning.
What is Finetuning?
When building an AI model from scratch, it starts with zero knowledge and essentially does random guessing. The model then extracts useful patterns through training on data and starts displaying increasingly intelligent behavior as training progresses. One downside to this approach is that training from scratch requires a lot of data. Finetuning is the idea that an existing model is used and adapted to a new task, or adapted to approach the same task differently. Because the model already has learned the most important patterns, much less data is required.
For example, a powerful open-source LLM like Mistral7B can be trained from scratch by anyone, in principle. However, the amount of data required to produce even remotely useful outputs is gigantic. Instead, companies use the existing Mistral7B model and feed it a small amount of proprietary data to make it solve new tasks, whether that is writing SQL queries or classifying emails.
The key takeaway is that finetuning does not change the fundamental structure of the model. It only adapts its internal logic slightly to perform better on a specific task. Now, let’s use this knowledge to understand how Google finetuned MusicLM on user data.
How Google Gathered User Data
A few months after the MusicLM paper, a public demo was released as part of Google’s AI Test Kitchen. There, users could experiment with the text-to-music model for free. However, you might know the saying: If the product is free, YOU are the product. Unsurprisingly, Google is no exception to this rule. When using MusicLM’s public demo, you were occasionally confronted with two generated outputs and asked to state which one you prefer. Through this method, Google was able to gather 300,000 user preferences within a couple of months.
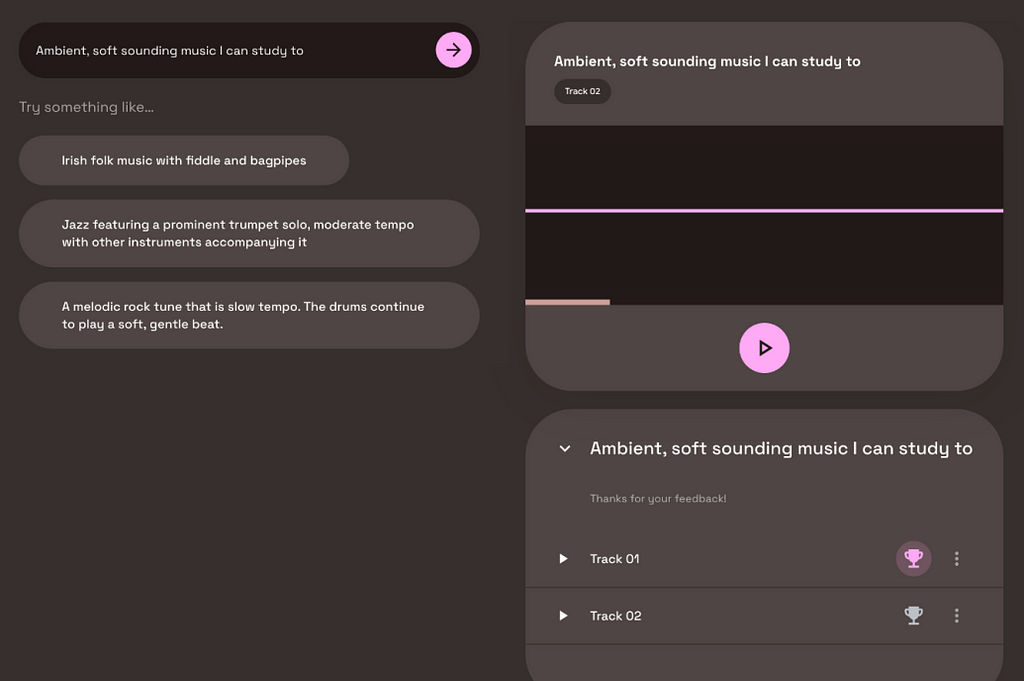
As you can see from the screenshot, users were not explicitly informed that their preferences would be used for machine learning. While that may feel unfair, it is important to note that many of our actions in the internet are being used for ML training, whether it is our Google search history, our Instagram likes, or our private Spotify playlists. In comparison to these rather personal and sensitive cases, music preferences on the MusicLM playground seem negligible.
Example of User Data Collection on Linkedin Collaborative Articles
It is good to be aware that user data collection for machine learning is happening all the time and usually without explicit consent. If you are on Linkedin, you might have been invited to contribute to so-called “collaborative articles”. Essentially, users are invited to provide tips on questions in their domain of expertise. Here is an example of a collaborative article on how to write a successful folk song (something I didn’t know I needed).
Users are incentivized to contribute, earning them a “Top Voice” badge on the platform. However, my impression is that noone actually reads these articles. This leads me to believe that these thousands of question-answer pairs are being used by Microsoft (owner of Linkedin) to train an expert AI system on these data. If my suspicion is accurate, I would find this example much more problematic than Google asking users for their favorite track.
But back to MusicLM!
How Google Took Advantage of this User Data
The next question is how Google was able to use this massive collection of user preferences to finetune MusicLM. The secret lies in a technique called Reinforcement Learning from Human Feedback (RLHF) which was one of the key breakthroughs of ChatGPT back in 2022. In RLHF, human preferences are used to train an AI model that learns to imitate human preference decisions, resulting in an artificial human rater. Once this so-called reward model is trained, it can take in any two tracks and predict which one would most likely be preferred by human raters.
With the reward model set up, MusicLM could be finetuned to maximize the predicted user preference of its outputs. This means that the text-to-music model generated thousands of tracks, each track receiving a rating from the reward model. Through the iterative adaptation of the model weights, MusicLM learned to generate music that the artificial human rater “likes”.
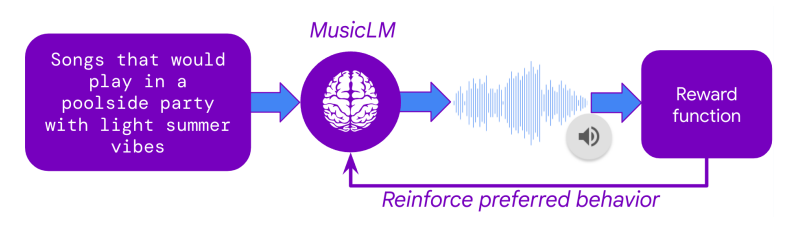
In addition to the finetuning on user preferences, MusicLM was also finetuned concerning two other criteria:
1. Prompt Adherence
MuLan, Google’s proprietary text-to-audio embedding model was used to calculate the similarity between the user prompt and the generated audio. During finetuning, this adherence score was maximized.
2. Audio Quality
Google trained another reward model on user data to evaluate the subjective audio quality of its generated outputs. These user data seem to have been collected in separate surveys, not in MusicLM’s public demo.
How Much Better is the New MusicLM?
The new, finetuned model seems to reliably outperform the old MusicLM, listen to the samples provided on the demo page. Of course, a selected public demo can be deceiving, as the authors are incentivized to showcase examples that make their new model look as good as possible. Hopefully, we will get to test out MusicRL in a public playground, soon.
However, the paper also provides a quantitative assessment of subjective quality. For this, Google conducted a study and asked users to compare two tracks generated for the same prompt, giving each track a score from 1 to 5. Using this metric with the fancy-sounding name Mean Opinion Score (MOS), we can compare not only the number of direct comparison wins for each model, but also calculate the average rater score (MOS).
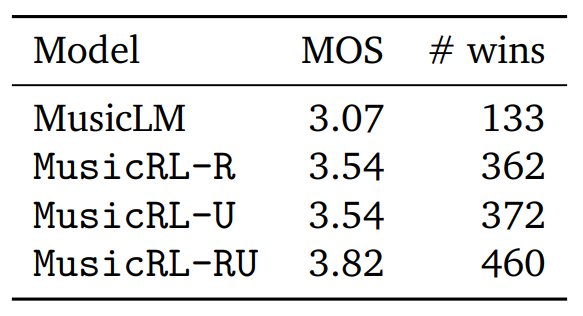
Here, MusicLM represents the original MusicLM model. MusicRL-R was only finetuned for audio quality and prompt adherence. MusicRL-U was finetuned solely on human feedback (the reward model). Finally, MusicRL-RU was finetuned on all three objectives. Unsurprisingly, MusicRL-RU beats all other models in direct comparison as well as on the average ratings.
The paper also reports that MusicRL-RU, the fully finetuned model, beat MusicLM in 87% of direct comparisons. The importance of RLHF can be shown by analyzing the direct comparisons between MusicRL-R and MusicRL-RU. Here, the latter had a 66% win rate, reliably outperforming its competitor.
What are the Implications of This?
Although the difference in output quality is noticeable, qualitatively as well as quantitatively, the new MusicLM is still quite far from human-level outputs in most cases. Even on the public demo page, many generated outputs sound odd, rhythmically, fail to capture key elements of the prompt or suffer from unnatural-sounding instruments.
In my opinion, this paper is still significant, as it is the first attempt at using RLHF for music generation. RLHF has been used extensively in text generation for more than one year. But why has this taken so long? I suspect that collecting user feedback and finetuning the model is quite costly. Google likely released the public MusicLM demo with the primary intention of collecting user feedback. This was a smart move and gave them an edge over Meta, which has equally capable models, but no open platform to collect user data on.
All in all, Google has pushed itself ahead of the competition by leveraging proven finetuning methods borrowed from ChatGPT. While even with RLHF, the new MusicLM has still not reached human-level quality, Google can now maintain and update its reward model, improving future generations of text-to-music models with the same finetuning procedure.
It will be interesting to see if and when other competitors like Meta or Stability AI will be catching up. For us as users, all of this is just great news! We get free public demos and more capable models.
For musicians, the pace of the current developments may feel a little threatening — and for good reason. I expect to see human-level text-to-music generation in the next 1–3 years. By that, I mean text-to-music AI that is at least as capable at producing music as ChatGPT was at writing texts when it was released. Musicians must learn about AI and how it can already support them in their everyday work. As the music industry is being disrupted once again, curiosity and flexibility will be the primary key to success.
Interested in Music AI?
If you liked this article, you might want to check out some of my other work:
- “3 Music AI Breakthroughs to Expect in 2024”. Medium Blog
- “Where is Generative AI Music Now?”. YouTube Interview on Sync My Music
- “MusicLM — Has Google Solved AI Music Generation?” Medium Blog Post
You can also follow me on Linkedin to stay updated about new papers and trends in Music AI.
Thanks for reading this article!
References
Agostinelli et al., 2023. MusicLM: Generating Music From Text. https://arxiv.org/abs/2301.11325
Cideron et al., 2024. MusicRL: Aligning Music Generation to Human Preferences. https://arxiv.org/abs/2402.04229
How Google Used Your Data to Improve their Music AI was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
Originally appeared here:
How Google Used Your Data to Improve their Music AI
Go Here to Read this Fast! How Google Used Your Data to Improve their Music AI