

High-Performance Python Data Processing: pandas 2 vs. Polars, a vCPU Perspective
Polars promises its multithreading capabilities outperform pandas. But is it also the case with a single vCore?
Love it or hate it, pandas has been a dominant library in Python data analysis for years. It’s being used extensively in data science and analysis (both in industry and academia), as well as by software & data engineers in data processing tasks.
pandas’ long reign as the champion of tabular data analysis is currently being challenged by a new library, Polars. Polars aims to replace pandas by implementing a more modern framework to solve the same use cases pandas solves today. One of its main promises is to provide better performance, utilizing a backend written in Rust that is optimized for parallel processing. Moreover, it has a deeper implementation of vectorized operations (SIMD), which is one of the features that make NumPy and pandas so fast and powerful.
How much faster is it?
Looking at this plot (posted on the Polars homepage in April 24′), which shows the run time in seconds for the TPC-H Benchmark, under different Python data analysis ecosystems, at a glance it seems that Polar is 25x faster than pandas. Digging a bit deeper, we can find that these benchmarks were collected on a 22 vCPU virtual machine. Polars is written to excel at parallel processing, so, of course, it benefits greatly by having such a large number of vCPUs available. pandas, on the other hand, does not support multithreading at all, and thus likely only utilizes 1 vCPU on this machine. In other words, Polars completed in 1/25 of the time it took pandas, but it also used 22x more compute resources.
{kind=link}
The problem with vCores
While every physical computer nowadays sports a CPU with some form of hardware parallelization (multiple cores, multiple ALU, hyper-threading…), the same is not always true for virtual servers, where it’s often beneficial to use smaller servers to minimize costs. For example, serverless platforms like AWS Lambda Functions, GCP Cloud Functions, and Azure Functions scale vCores with memory, and as you are charged by GB-second, you would not be inclined to assign more memory to your functions than you need.
Given that this is the case, I’ve decided to test how Polars performs against pandas, in particular, I was interested in two things:
1. How Polars compares to pandas, with only 1 vCore available
2. How Polars scales with vCores
We will consider 4 operations: grouping and aggregation, quantile computation, filtering, and sorting, which could be incorporated into a data analysis job or pipeline that can be seen in the work of both data analysts and data scientists, as well as data and software engineers.
The setup
I used an AWS m6a.xlarge machine that has 4 vCores and 16GB RAM available and utilized taskset to assign 1 vCore and 2 vCores to the process at a time to simulate a machine with fewer vCores each time. For lib versions, I took the most up-to-date stable releases available at the time:
pandas==2.2.2; polars=1.2.1
The data
The dataset was randomly generated to be made up of 1M rows and 5 columns, and is meant to serve as a history of 100k user operations made in 10k sessions within a certain product:
user_id (int)
action_types (enum, can take the values in [“click”, “view”, “purchase”])
timestamp (datetime)
session_id (int)
session_duration (float)
The premise
Given the dataset, we want to find the top 10% of most engaged users, judging by their average session duration. So, we would first want to calculate the average session duration per user (grouping and aggregation), find the 90th quantile (quantile computation), select all the users above the quantile (filtering), and make sure the list is ordered by the average session duration (sorting).
Testing
Each of the operations were run 200 times (using timeit), taking the mean run time each time and the standard error to serve as the measurement error. The code can be found here.
A note on eager vs lazy evaluation
Another difference between pandas and Polars is that the former uses eager execution (statements are executed as they are written) by default and the latter uses lazy execution (statements are compiled and run only when needed). Polar’s lazy execution helps it optimize queries, which makes a very nice feature in heavy data analysis tasks. The choice to split our task and look at 4 operations is made to eliminate this aspect and focus on comparing more basic performance aspects.
Results
Group by + Aggregate
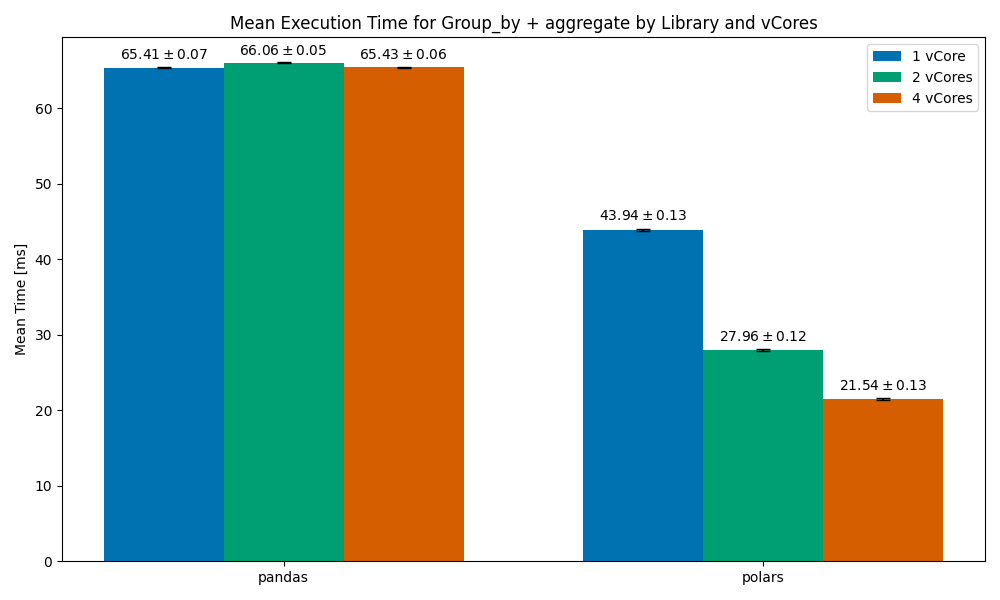
We can see how pandas does not scale with vCores — as expected. This trend will remain throughout our test. I decided to keep it in the plots, but we won’t reference it again.
polars’ results are quite impressive here — with a 1vCore setup it managed to finish faster than pandas by a third of the time, and as we scale to 2, 4 cores it finishes roughly 35% and 50% faster respectively.
Quantile Computation
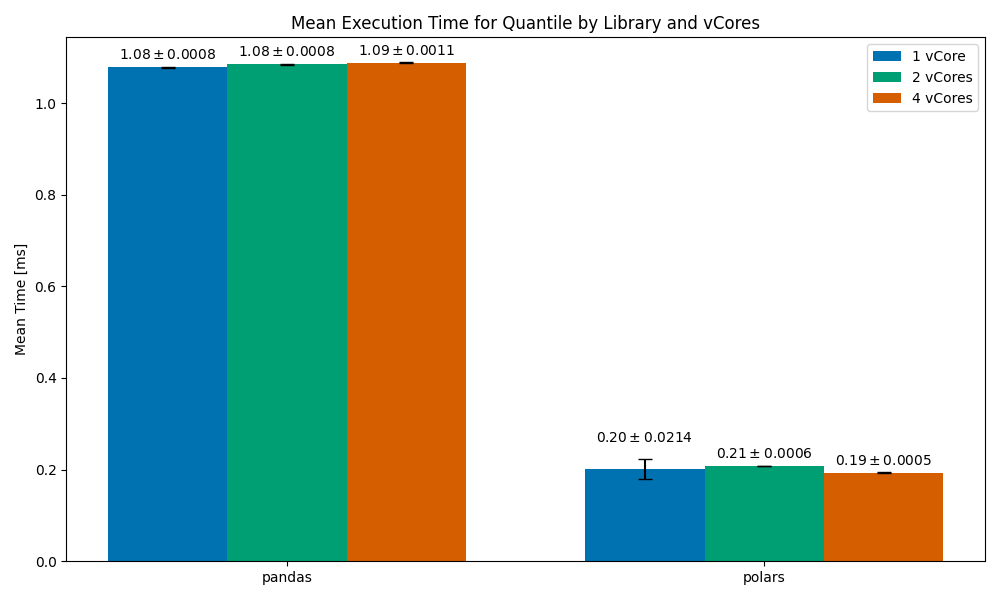
This one is interesting. In all vCores setups, polars finished around 5x faster than pandas. On the 1vCore setup, it measured 0.2ms on average, but with a significant standard error (meaning that the operation would sometimes finish well after 0.2ms, and at other times it would finish well before 0.2ms). When scaling to multiple cores we get stabler run times — 2vCores at 0.21ms and 4vCores at 0.19 (around 10% faster).
Filtering
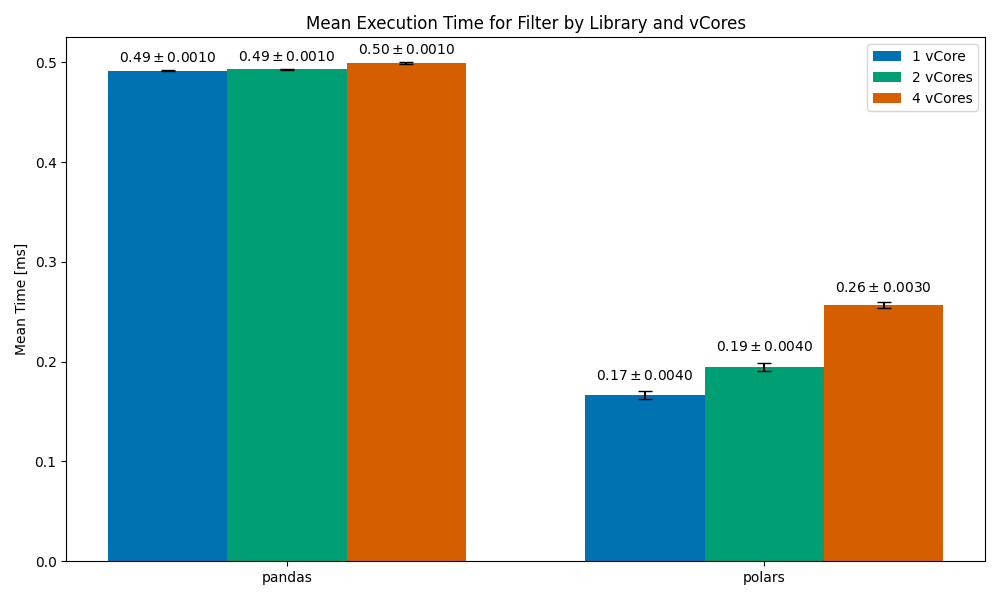
In all cases, Polars finishes faster than pandas (the worse run time is still 2 times faster than pandas). However, we can see a very unusual trend here — the run time increases with vCores (we’re expecting it to decrease). The run time of the operation with 4 vCores is roughly 35% slower than the run time with 1 vCore. While parallelization gives you more computing power, it often comes with some overhead — managing and orchestrating parallel processes is often very difficult.
This Polars scaling issue is perplexing — the implementation on my end is very simple, and I was not able to find a relevant open issue on the Polars repo (there are currently over 1k open issues there, though).
Do you have any idea as to why this could have happened? Let me know in the comments.
Sorting
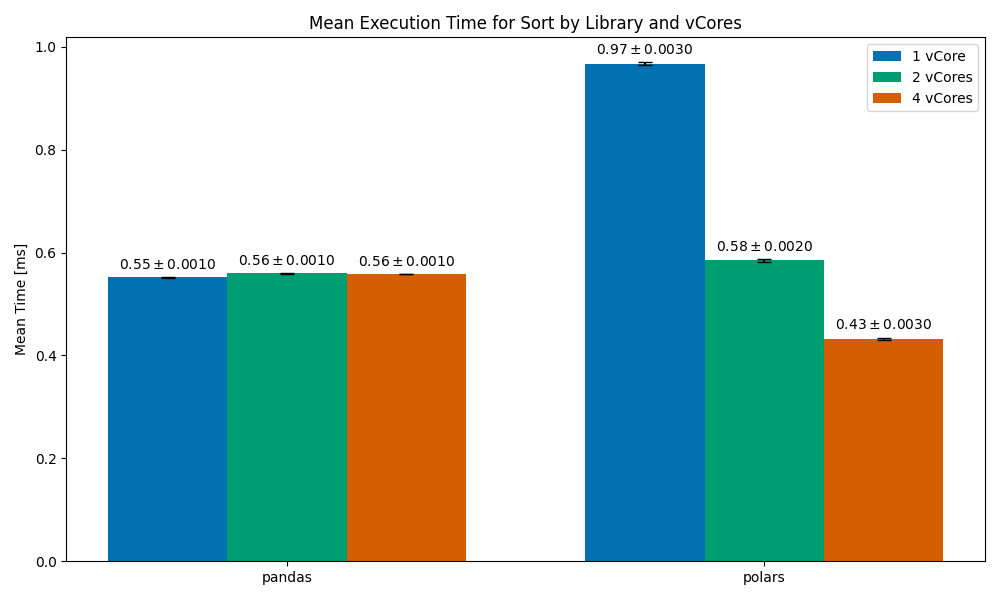
After filtering, we are left with around 13.5k rows.
In this one, we can see that the 1vCore Polars case is significantly slower than pandas (by around 45%). As we scale to 2vCores the run time becomes competitive with pandas’, and by the time we scale to 4vCores Polars becomes significantly faster than pandas. The likely scenario here is that Polars uses a sorting algorithm that is optimized for parallelization — such an algorithm may have poor performance on a single core.
Looking more closely at the docs, I found that the sort operation in Polars has a multithreaded parameter that controls whether a multi-threaded sorting algorithm is used or a single-threaded one.
Sorting (with multithreading=False)
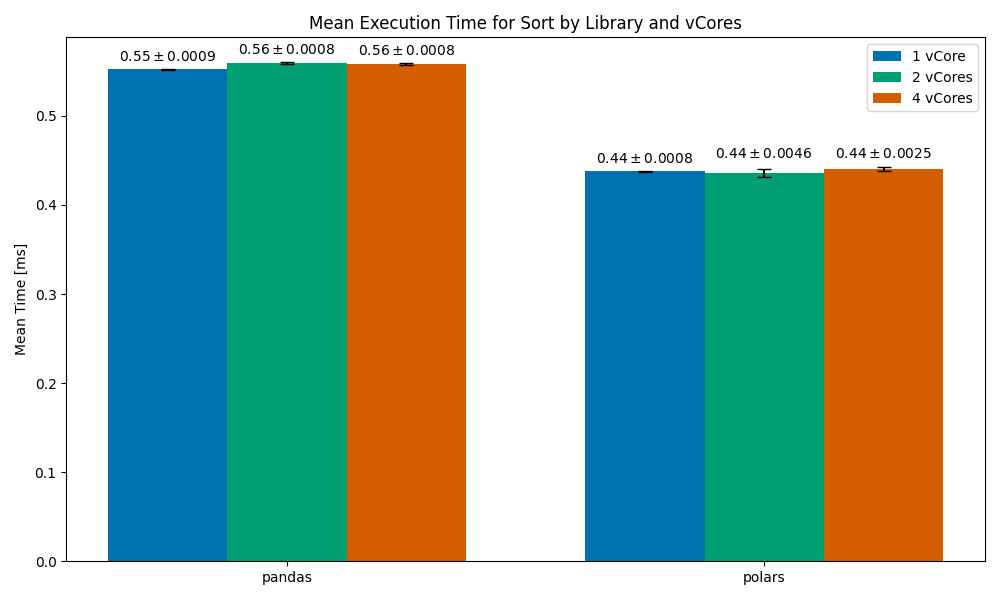
This time, we can see much more consistent run times, which don’t scale with cores but do beat pandas.
Conclusions
- Parallel computing & distributed computing is hard. We tend to think that if we just scale our program it would complete faster, but it always adds overhead. In many cases, programs like Redis and node.js that are known to be blazing fast are actually single-threaded, with no parallelization support (node.js is famously concurrent, but concurrency =/= parallelization).
- It appears that, for the most part, Polars is indeed faster than pandas, even with just 1 available vCore. Impressive!
- Judging by the filter & sorting operation, polars appears to not be well-optimized to a single vCore case, as you might encounter on your cloud. This is important if you run a lot of small (<2GB in memory) serverless Functions. Scaling for speed is often coupled with scaling in price.
- Polars is still a relatively new solution, and as of mid-2024 it feels not as mature as pandas. For example, on the multithreaded parameter in sort — I’d expect there to be an auto default option that will choose the algorithm based on the hardware.
Final Notes
- When considering a switch between foundational libraries like pandas, performance is not the only thing that should be on your mind. It’s important to consider other parameters such as the cost of switching (learning a new syntax, refactoring old code), the compatibility with other libraries, and the maturity of the new solution.
- The tests here are meant as to be in the middle of the spectrum between quick and dirty and thorough benchmarks. There is more to do to reach a decisive conclusion.
- I briefly discussed how pandas and Polars benefit from SIMD (single instruction, multiple data), another piece of hardware you may have heard of, the GPU, is famous for implementing the same idea. Nvidia has released a plugin for executing Apache Spark code on a GPU — from my testing, it’s even less mature than Polars but worth checking out.
High-Performance Data Processing: pandas 2 vs. Polars, a vCPU Perspective was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
Originally appeared here:
High-Performance Data Processing: pandas 2 vs. Polars, a vCPU Perspective
Go Here to Read this Fast! High-Performance Data Processing: pandas 2 vs. Polars, a vCPU Perspective