
Graph RAG into Production — Step-by-Step
A GCP native, fully serverless implementation that you will replicate in minutes
After discussing Graph RAG conceptually, let’s bring it into production. This is how to productionize GraphRAG: completely serverless, fully parallelized to minimize inference and indexing times, and without ever touching a graph database (promise!).
In this article, I will introduce you to graphrag-lite, an end-to-end Graph RAG ingestion and query implementation. I published graphrag-lite as an OSS project to make your life easier when deploying graphrag on GCP. Graphrag-lite is Google Cloud-native and ready to use off the shelf. The code is designed in a modular manner, adjustable for your platform of choice.
Recap:
Retrieval Augmented Generation itself does not yet describe any specific architecture or method. It only depicts the augmentation of a given generation task with an arbitrary retrieval method. The original RAG paper (Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks by Lewis et. al.) compares a two-tower embedding approach with bag-of-words retrieval.
Modern Q&A systems differentiate between local and global questions. A local (extractive) question on an unstructured sample knowledge base might be “Who won the Nobel Peace Prize in 2023?”. A global (aggregative) question might be “Who are the most recent Nobel prize winners you know about?”. Text2embedding RAG leaves obvious gaps when it comes to global and structured questions. Graph RAG can close these gaps and it does that well! Via an abstraction layer, it learns the semantics of the knowledge graph communities. That builds a more “global” understanding of the indexed dataset. Here is a conceptual intro to Graph RAG to read up on.
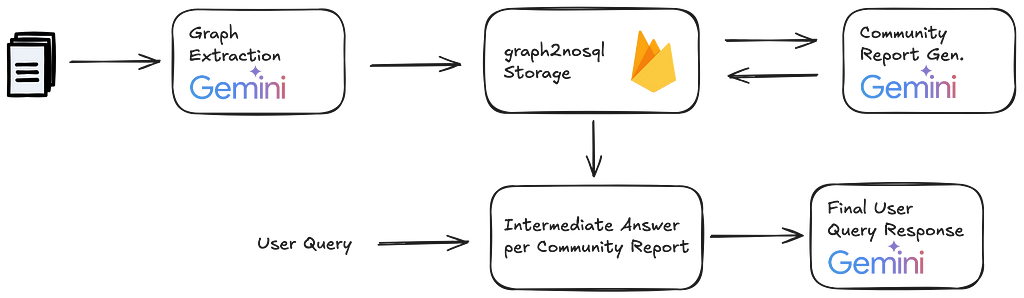
The Graph RAG pipeline
A Graph RAG pipeline will usually follows the following steps:
Graph Extraction
This is the main ingestion step. Your LLM scans every incoming document with a prompt to extract relevant nodes and edges for our knowledge graph. You iterate multiple times over this prompt to assure you catch all relevant pieces of information.
Graph Storage
You store the extracted nodes and edges in your data store of choice. Dedicated Graph DBs are one option, but they are often tedious. Graph2nosql is a Python-based interface to store and manage knowledge graphs in Firestore or any other NoSQL DB. I open sourced this project becase I did not find any other comparable, knowledge graph native option on the market.
Community detection
Once you store your knowledge graph data you will use a community detection algorithm to identify groups of nodes that are more densely connected within each other than they are to the rest of the graph. In the context of a knowledge graph, the assumption is that dense communities cover common topics.
Community report generation
You then instruct your LLM to generate a report for each graph community. These community reports help abstract across single topics to grasp wider, global concepts across your dataset. Community reports are stored along with your knowledge graph. This concludes the ingestion layer of the pipeline.
Map-Reduce for final context building.
At query time you follow a map-reduce pattern to generate an intermediate response to the user query for every community report in your knowledge graph. You have the LLM also rate the relevance of each intermediate query response. Finally, you rank the intermediate responses by relevance and select the top n as context for your final response to the user.
Graph Extraction
In the initial ingestion step, you instruct your LLM to encode your input document(s) as a graph. An extensive prompt instructs your LLM to first identify nodes of given types, and secondly edges between the nodes you identified. Just like with any LLM prompt, there is not one solution for this challenge. Here is the core of my graph extraction prompt, which I based on Microsoft’s OSS implementation:
-Goal-
Given a text document that is potentially relevant to this activity and a list of entity types, identify all entities of those types from the text and all relationships among the identified entities.
-Steps-
1. Identify all entities. For each identified entity, extract the following information:
- entity_name: Name of the entity, capitalized
- entity_type: One of the following types: [{entity_types}]
- entity_description: Comprehensive description of the entity's attributes and activities
Format each entity as ("entity"{tuple_delimiter}<entity_name>{tuple_delimiter}<entity_type>{tuple_delimiter}<entity_description>
2. From the entities identified in step 1, identify all pairs of (source_entity, target_entity) that are *clearly related* to each other.
For each pair of related entities, extract the following information:
- source_entity: name of the source entity, as identified in step 1
- target_entity: name of the target entity, as identified in step 1
- relationship_description: explanation as to why you think the source entity and the target entity are related to each other
- relationship_strength: a numeric score indicating strength of the relationship between the source entity and target entity
Format each relationship as ("relationship"{tuple_delimiter}<source_entity>{tuple_delimiter}<target_entity>{tuple_delimiter}<relationship_description>{tuple_delimiter}<relationship_strength>)
3. Return output in English as a single list of all the entities and relationships identified in steps 1 and 2. Use **{record_delimiter}** as the list delimiter.
4. When finished, output {completion_delimiter}
<Multishot Examples>
-Real Data-
######################
Entity_types: {entity_types}
Text: {input_text}
######################
Output:
The extraction step is responsible for which information will be reflected in your knowledge base. Thus you should use a rather powerful model such as Gemini 1.5 Pro. You can further increase the result robustness, use the multi-turn version Gemini 1.5 Pro, and query the model to improve its results n times. Here is how I implemented the graph extraction loop in graphrag-lite:
class GraphExtractor:
def __init__(self, graph_db) -> None:
self.tuple_delimiter = "<|>"
self.record_delimiter = "##"
self.completion_delimiter = "<|COMPLETE|>"
self.entity_types = ["organization", "person", "geo", "event"]
self.graph_extraction_system = prompts.GRAPH_EXTRACTION_SYSTEM.format(
entity_types=", ".join(self.entity_types),
record_delimiter=self.record_delimiter,
tuple_delimiter=self.tuple_delimiter,
completion_delimiter=self.completion_delimiter,
)
self.llm = LLMSession(system_message=self.graph_extraction_system,
model_name="gemini-1.5-pro-001")
def __call__(self, text_input: str, max_extr_rounds: int = 5) -> None:
input_prompt = self._construct_extractor_input(input_text=text_input)
print("+++++ Init Graph Extraction +++++")
init_extr_result = self.llm.generate_chat(
client_query_string=input_prompt, temperature=0, top_p=0)
print(f"Init result: {init_extr_result}")
for round_i in range(max_extr_rounds):
print(f"+++++ Contd. Graph Extraction round {round_i} +++++")
round_response = self.llm.generate_chat(
client_query_string=prompts.CONTINUE_PROMPT, temperature=0, top_p=0)
init_extr_result += round_response or ""
print(f"Round response: {round_response}")
if round_i >= max_extr_rounds - 1:
break
completion_check = self.llm.generate_chat(
client_query_string=prompts.LOOP_PROMPT, temperature=0, top_p=0)
if "YES" not in completion_check:
print(
f"+++++ Complete with completion check after round {round_i} +++++")
break
First I make an initial call to the multi-turn model to extract nodes and edges. Second I ask the model to improve the previous extraction results several times.
In the graphrag-lite implementation, the extraction model calls are made by the front-end client. If you want to reduce client load you could outsource the extraction queries to a microservice.
Graph Storage
Once you extract the nodes and edges from a document you need to store them in an accessible format. Graph Databases are one way to go, but they can also be cumbersome. For your knowledge graph, you might be looking for something a little more lightweight. I thought the same, because I did not find any knowledge graph native library I open sources graph2nosql. Graph2nosql is a simple knowledge graph native Python interface. It helps store and manage your knowledge graph in any NoSQL DB. All that without blowing up your tech stack with a graph db or needing to learn Cypher.
Graph2nosql is designed for knowledge graph retrieval with graph rag in mind. The library is designed around three major datatypes: EdgeData, NodeData, and CommunityData. Nodes are identified by an uid. Edges are identified by source and destination node uid and an edge uid. Given that uids can be freely designed, the graph2nosql data model leaves space for any size of the knowledge graph. You can even add text or graph embeddings. That allows embedding-based analytics, edge prediction, and additional text embedding retrieval (thinking hybrid RAG).
Graph2nosql is natively designed around Firestore.
@dataclass
class EdgeData:
source_uid: str
target_uid: str
description: str
edge_uid: str | None = None
document_id: str | None = None
@dataclass
class NodeData:
node_uid: str
node_title: str
node_type: str
node_description: str
node_degree: int
document_id: str
community_id: int | None = None # community id based on source document
edges_to: list[str] = field(default_factory=list)
edges_from: list[str] = field(default_factory=list) # in case of directed graph
embedding: list[float] = field(default_factory=list) # text embedding representing node e.g. combination of title & description
@dataclass
class CommunityData:
title: str # title of comm, None if not yet computed
community_nodes: set[str] = field(default_factory=set) # list of node_uid belonging to community
summary: str | None = None # description of comm, None if not yet computed
document_id: str | None = None # identifier for source knowlede base document for this entity
community_uid: str | None = None # community identifier
community_embedding: Tuple[float, ...] = field(default_factory=tuple) # text embedding representing community
rating: int | None = None
rating_explanation: str | None = None
findings: list[dict] | None = None
To store your graph data via graph2nosql simply run the following code when parsing the results from your extraction step. Here is the graphrag-lite implementation.
from graph2nosql.graph2nosql.graph2nosql import NoSQLKnowledgeGraph
from graph2nosql.databases.firestore_kg import FirestoreKG
from graph2nosql.datamodel import data_model
fskg = FirestoreKG(
gcp_project_id=project_id,
gcp_credential_file=firestore_credential_file,
firestore_db_id=database_id,
node_collection_id=node_coll_id,
edges_collection_id=edges_coll_id,
community_collection_id=community_coll_id)
node_data = data_model.NodeData(
node_uid=entity_name,
node_title=entity_name,
node_type=entity_type,
node_description=entity_description,
document_id=str(source_doc_id),
node_degree=0)
fskg.add_node(node_uid=entity_name,node_data=node_data)
Community detection
With all relevant nodes and edges stored in your Graph DB, you can start building the abstraction layer. One way of doing that is finding nodes that describe similar concepts and describe how they are connected semantically. Graph2nosql offers inbuilt community detection, for example, based on Louvain communities.
Depending on your extraction result quality you will find zero-degree nodes in your knowledge graph. From experience, zero-degree nodes are often duplicates. Graphrag-lite uses graph communities as a major abstraction layer thus you should drop the nodes without any edges. Thus it would make sense to think about another duplicate/merge step and/or a node prediction step based on description and graph embeddings to add edges that might have been missed in the extraction step. In graphrag-lite I currently simply drop all zero-degree nodes.
# clean graph off all nodes without any edges
fskg.clean_zerodegree_nodes()
# generate communities based on cleaned graph
comms = kg.get_louvain_communities()
Here is the graphrag-lite implementation of community detection.
Optimizing throughput latency in LLM applications
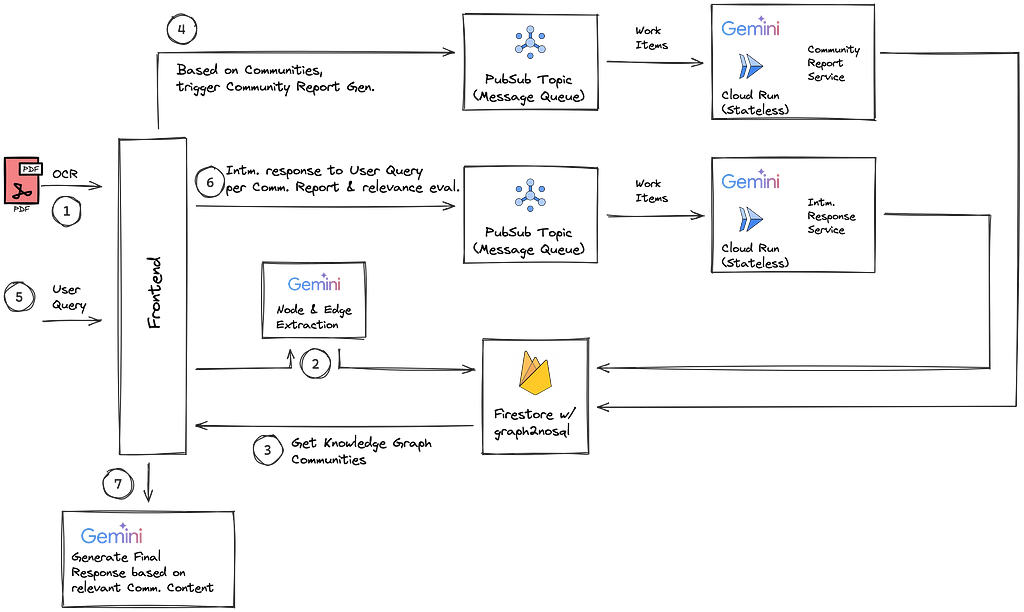
The GraphRAG pipeline mentioned above takes numerous LLM calls per document ingestion and user query. For example, to generate multiple community reports for every newly indexed document, or to generate intermediate responses for multiple communities at query time. If processed concurrently an awful user experience will be the result. Especially at scale users will have to wait minutes to hours to receive a response to their query. Fortunately, if you frame your LLM prompts the right way you can design them as “stateless workers”. The power of stateless processing architectures is twofold. Firstly, they are easy to parallelize. Secondly, they are easy to implement as serverless infastructure. Combined with a parallelized and serverless architecture maximizes your throughput scalability and minimizes your cost for idle cluster setups.
In the graphrag-lite architecture I host both the community report generation and the intermediate query generation as serverless Cloud Run microservice workers. These are fed with messages via GCP’s serverless messaging queue PubSub.
Community report generation
After running the community detection you now know multiple sets of community member nodes. Each of these sets represents a semantic topic within your knowledge graph. The community reporting step needs to abstract across these concepts that originated in different documents within your knowledge base. I again built on the Microsoft implementation and added a function call for easily parsable structured output.
You are an AI assistant that helps a human analyst to perform general information discovery. Information discovery is the process of identifying and assessing relevant information associated with certain entities (e.g., organizations and individuals) within a network.
# Goal
Write a comprehensive report of a community, given a list of entities that belong to the community as well as their relationships and optional associated claims. The report will be used to inform decision-makers about information associated with the community and their potential impact. The content of this report includes an overview of the community's key entities, their legal compliance, technical capabilities, reputation, and noteworthy claims.
# Report Structure
The report should include the following sections:
- TITLE: community's name that represents its key entities - title should be short but specific. When possible, include representative named entities in the title.
- SUMMARY: An executive summary of the community's overall structure, how its entities are related to each other, and significant information associated with its entities.
- IMPACT SEVERITY RATING: a float score between 0-10 that represents the severity of IMPACT posed by entities within the community. IMPACT is the scored importance of a community.
- RATING EXPLANATION: Give a single sentence explanation of the IMPACT severity rating.
- DETAILED FINDINGS: A list of 5-10 key insights about the community. Each insight should have a short summary followed by multiple paragraphs of explanatory text grounded according to the grounding rules below. Be comprehensive.
The community report generation also demonstrated the biggest challenge around knowledge graph retrieval. Theoretically, any document could add a new node to every existing community in the graph. In the worst-case scenario, you re-generate every community report in your knowledge base for each new document added. In practice it is crucial to include a detection step that identifies which communities have changed after a document upload, resulting in new report generation for only the adjusted communities.
As you need to re-generate multiple community reports for every document upload we are also facing significant latency challenges if running these requests concurrently. Thus you should outsource and parallelize this work to asynchronous workers. As mentioned before, graphrag-lite solved this using a serverless architecture. I use PubSub as a message queue to manage work items and ensure processing. Cloud Run comes on top as a compute platform hosting stateless workers calling the LLM. For generation, they use the prompt as shown above.
Here is the code that runs in the stateless worker for community report generation:
def async_generate_comm_report(self, comm_members: set[str]) -> data_model.CommunityData:
llm = LLMSession(system_message=prompts.COMMUNITY_REPORT_SYSTEM,
model_name="gemini-1.5-flash-001")
response_schema = {
"type": "object",
"properties": {
"title": {
"type": "string"
},
"summary": {
"type": "string"
},
"rating": {
"type": "int"
},
"rating_explanation": {
"type": "string"
},
"findings": {
"type": "array",
"items": {
"type": "object",
"properties": {
"summary": {
"type": "string"
},
"explanation": {
"type": "string"
}
},
# Ensure both fields are present in each finding
"required": ["summary", "explanation"]
}
}
},
# List required fields at the top level
"required": ["title", "summary", "rating", "rating_explanation", "findings"]
}
comm_report = llm.generate(client_query_string=prompts.COMMUNITY_REPORT_QUERY.format(
entities=comm_nodes,
relationships=comm_edges,
response_mime_type="application/json",
response_schema=response_schema
))
comm_data = data_model.CommunityData(title=comm_report_dict["title"], summary=comm_report_dict["summary"], rating=comm_report_dict["rating"], rating_explanation=comm_report_dict["rating_explanation"], findings=comm_report_dict["findings"],
community_nodes=comm_members)
return comm_data
This completes the ingestion pipeline.
Map-step for intermediate responses
Finally, you reached query time. To generate your final response to the user, you generate a set of intermediate responses (one per community report). Each intermediate response takes the user query and one community report as input. You then rate these intermediate queries by their relevance. Finally, you use the most relevant community reports and additional information such as node descriptions of the relevant member nodes as the final query context. Given a high number of community reports at scale, this again poses a challenge of latency and cost. Similar to previously you should also parallelize the intermediate response generation (map-step) across serverless microservices. In the future, you could significantly improve efficiency by adding a filter layer to pre-determine the relevance of a community report for a user query.
The map-step microservice looks as follows:
def generate_response(client_query: str, community_report: dict):
llm = LLMSession(
system_message=MAP_SYSTEM_PROMPT,
model_name="gemini-1.5-pro-001"
)
response_schema = {
"type": "object",
"properties": {
"response": {
"type": "string",
"description": "The response to the user question as raw string.",
},
"score": {
"type": "number",
"description": "The relevance score of the given community report context towards answering the user question [0.0, 10.0]",
},
},
"required": ["response", "score"],
}
query_prompt = MAP_QUERY_PROMPT.format(
context_community_report=community_report, user_question=client_query)
response = llm.generate(client_query_string=query_prompt,
response_schema=response_schema,
response_mime_type="application/json")
return response
The map-step microservice uses the following prompt:
---Role---
You are an expert agent answering questions based on context that is organized as a knowledge graph.
You will be provided with exactly one community report extracted from that same knowledge graph.
---Goal---
Generate a response consisting of a list of key points that responds to the user's question, summarizing all relevant information in the given community report.
You should use the data provided in the community description below as the only context for generating the response.
If you don't know the answer or if the input community description does not contain sufficient information to provide an answer respond "The user question cannot be answered based on the given community context.".
Your response should always contain following elements:
- Query based response: A comprehensive and truthful response to the given user query, solely based on the provided context.
- Importance Score: An integer score between 0-10 that indicates how important the point is in answering the user's question. An 'I don't know' type of response should have a score of 0.
The response should be JSON formatted as follows:
{{"response": "Description of point 1 [Data: Reports (report ids)]", "score": score_value}}
---Context Community Report---
{context_community_report}
---User Question---
{user_question}
---JSON Response---
The json response formatted as follows:
{{"response": "Description of point 1 [Data: Reports (report ids)]", "score": score_value}}
response:
Reduce-step for final user response
For a successful reduce-step, you need to store the intermediate response for access at query time. With graphrag-lite, I use Firestore as a shared state across microservices. After triggering the intermediate response generations, the client also periodically checks for the existence of all expected entries in the shared state. The following code extract from graphrag-lite shows how I submit every community report to the PubSub queue. After, I periodically query the shared state to check whether all intermediate responses have been processed. Finally, the end response towards the user is generated using the top-scoring community reports as context to respond to the user query.
class KGraphGlobalQuery:
def __init__(self) -> None:
# initialized with info on mq, knowledge graph, shared nosql state
pass
@observe()
def __call__(self, user_query: str) -> str:
# orchestration method taking natural language user query to produce and return final answer to client
comm_report_list = self._get_comm_reports()
# pair user query with existing community reports
query_msg_list = self._context_builder(
user_query=user_query, comm_report_list=comm_report_list)
# send pairs to pubsub queue for work scheduling
for msg in query_msg_list:
self._send_to_mq(message=msg)
print("int response request sent to mq")
# periodically query shared state to check for processing compeltion & get intermediate responses
intermediate_response_list = self._check_shared_state(
user_query=user_query)
# based on helpfulness build final context
sorted_final_responses = self._filter_and_sort_responses(intermediate_response_list=intermediate_response_list)
# get full community reports for the selected communities
comm_report_list = self._get_communities_reports(sorted_final_responses)
# generate & return final response based on final context community repors and nodes.
final_response_system = prompts.GLOBAL_SEARCH_REDUCE_SYSTEM.format(
response_type="Detailled and wholistic in academic style analysis of the given information in at least 8-10 sentences across 2-3 paragraphs.")
llm = LLMSession(
system_message=final_response_system,
model_name="gemini-1.5-pro-001"
)
final_query_string = prompts.GLOBAL_SEARCH_REDUCE_QUERY.format(
report_data=comm_report_list,
user_query=user_query
)
final_response = llm.generate(client_query_string=final_query_string)
return final_response
Once all entries are found the client triggers the final user response generation given the selected community context.
Final Thoughts
Graph RAG is a powerful technique every ML Engineer should add to their toolbox. Every Q&A type of application will eventually arrive at the point that purely extractive, “local” queries don’t cut it anymore. With graphrag-lite, you now have a lightweight, cloud-native, and serverless implementation that you can rapidly replicate.
Despite these strengths, please note that in the current state Graph RAG still consumes significantly more LLM input tokens than in the text2emb RAG. That usually comes with considerably higher latency and cost for queries and document indexing. Nevertheless, after experiencing the improvement in result quality I am convinced that in the right use cases, Graph RAG is worth the time and money.
RAG applications will ultimately move in a hybrid direction. Extractive queries can be handled efficiently and correctly by text2emb RAG. Global abstractive queries might need a knowledge graph as an alternative retrieval layer. Finally, both methods underperform with quantitative and analytical queries. Thus a third text2sql retrieval layer would add massive value. To complete the picture, user queries could initially be classified between the three retrieval methods. Like this, every query could be grounded most efficiently with the right amount and depth of information.
I cannot wait to see where else this is going. Which alternative retrieval methods have you been working with?
Graph RAG into Production — step-by-step was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
Originally appeared here:
Graph RAG into Production — step-by-step
Go Here to Read this Fast! Graph RAG into Production — step-by-step