Shows our study based on the WSDM 2023 Toloka VQA Challenge

A year has passed since the Toloka Visual Question Answering (VQA) Challenge at the WSDM Cup 2023, and as we predicted back then, the winning machine-learning solution didn’t match up to the human baseline. However, this past year has been packed with breakthroughs in Generative AI. It feels like every other article flips between pointing out what OpenAI’s GPT models can’t do and praising what they do better than us.
Since autumn 2023, GPT-4 Turbo has gained “vision” capabilities, meaning it accepts images as input and it can now directly participate in VQA challenges. We were curious to test its ability against the human baseline in our Toloka challenge, wondering if that gap has finally closed.
Visual Question Answering
Visual Question Answering (VQA) is a multi-disciplinary artificial intelligence research problem, concentrated on making AI interpret images and answer related questions in natural language. This area has various applications: aiding visually impaired individuals, enriching educational content, supporting image search capabilities, and providing video search functionalities.
The development of VQA “comes with great responsibility”, such as ensuring the reliability and safety of the technology application. With AI systems having vision capabilities, the potential for misinformation increases, considering claims that images paired with false information can make statements appear more credible.
One of the subfields of the VQA domain, VQA Grounding, is not only about answers to visual questions but also connecting those answers to elements within the image. This subfield has great potential for applications like Mixed Reality (XR) headsets, educational tools, and online shopping, improving user interaction experience by directing attention to specific parts of an image. The goal of the Toloka VQA Challenge was to support the development of VQA grounding.
Toloka’s VQA Challenge recap
In the Toloka VQA Challenge, the task was to identify a single object and put it in a bounding box, based on a question that describes the object’s functions rather than its visual characteristics. For example, instead of asking to find something round and red, a typical question might be “What object in the picture is good in a salad and on a pizza?” This reflects the ability of humans to perceive objects in terms of their utility. It’s like being asked to find “a thing to swat a fly with” when you see a table with a newspaper, a coffee mug, and a pair of glasses — you’d know what to pick without a visual description of the object.
Question: What do we use to cut the pizza into slices?

The challenge required integrating visual, textual, and common sense knowledge at the same time. As a baseline approach, we proposed to combine YOLOR and CLIP as separate visual and textual backbone models. However, the winning solution did not use a two-tower paradigm at all, choosing instead the Uni-Perceiver model with a ViT-Adapter for better localization. It achieved a high final Intersection over Union (IoU) score of 76.347, however, it didn’t reach the crowdsourcing baseline of an IoU of 87.
Considering this vast gap between human and AI solutions, we were very curious to see how GPT-4V would perform in the Toloka VQA Challenge. Since the challenge was based on the MS COCO dataset, used countless times in Computer Vision (for example, in the Visual Spatial Reasoning dataset), and, therefore, likely “known” to GPT-4 from its training data, there was a possibility that GPT-4V might come closer to the human baseline.
GPT-4V and Toloka VQA Challenge
Initially, we wanted to find out if GPT-4V could handle the Toloka VQA Challenge as is.

However, even though GPT-4V mostly defined the object correctly, it had serious trouble providing meaningful coordinates for bounding boxes. This wasn’t entirely unexpected since OpenAI’s guide acknowledges GPT-4V’s limitations in tasks that require identifying precise spatial localization of an object on an image.

This led us to explore how well GPT-4 handles the identification of basic high-level locations in an image. Can it figure out where things are — not exactly, but if they’re on the left, in the middle, or on the right? Or at the top, in the middle, or at the bottom? Since these aren’t precise locations, it might be doable for GPT-4V, especially since it’s been trained on millions of images paired with captions pointing out the object’s directional locations. Educational materials often describe pictures in detail (just think of textbooks on brain structure that mention parts like “dendrites” at the “top left” or “axons” at the “bottom right” of an image).
The understanding of LLM’s and MLM’s spatial reasoning limitations, even simple reasoning like we discussed above, is crucial in practical applications. The integration of GPT-4V into the “Be My Eyes” application, which assists visually impaired users by interpreting images, perfectly illustrates this importance. Despite the abilities of GPT-4V, the application advises caution, highlighting the technology’s current inability to fully substitute for human judgment in critical safety and health contexts. However, exact topics where the technology is unable to perform well are not pointed out explicitly.
GPT-4V and spatial reasoning
For our exploration into GPT-4V’s reasoning on basic locations of objects on images, we randomly chose 500 image-question pairs from a larger set of 4,500 pairs, the competition’s private test dataset. We tried to minimize the chances of our test data leaking to the training data of GPT-4V since this subset of the competition data was released the latest in the competition timeline.

Out of these 500 pairs, 25 were rejected by GPT-4V, flagged as ‘invalid image’. We suspect this rejection was due to built-in safety measures, likely triggered by the presence of objects that could be classified as Personally Identifiable (PI) information, such as peoples’ faces. The remaining 475 pairs were used as the basis for our experiments.
Understanding how things are positioned in relation to each other, like figuring out what’s left, middle or right and top, middle or bottom isn’t as straightforward as it might seem. A lot depends on the observer’s viewpoint, whether the object has a front, and if so, what are their orientations. So, spatial reasoning in humans may rely on significant inductive bias about the world as the result of our evolutionary history.
Question: What protects the eyes from lamp glare?

Take an example pair with a lampshade above, sampled from the experiment data. One person might say it’s towards the top-left of the image because the lampshade leans a bit left, while another might call it middle-top, seeing it centered in the picture. Both views have a point. It’s tough to make strict rules for identifying locations because objects can have all kinds of shapes and parts, like a lamp’s long cord, which might change how we see where it’s placed.
Keeping this complexity in mind, we planned to try out at least two different methods for labeling the ground truth of where things are in an image.
It works in the following way: if the difference in pixels between the center of the image and the center of the object (marked by its bounding box) is less than or equal to a certain percentage of the image’s width (for horizontal position) or height (for vertical position), then we label the object as being in the middle. If the difference is more, it gets labeled as either left or right (or top or bottom). We settled on using 2% as the threshold percentage. This decision was based on observing how this difference appeared for objects of various sizes relative to the overall size of the image.
object_horizontal_center = bb_left + (bb_right - bb_left) / 2
image_horizontal_center = image_width / 2
difference = object_horizontal_center - image_horizontal_center
if difference > (image_width * 0.02):
return 'right'
else if difference < (-1 * image_width * 0.02):
return 'left'
else:
return 'middle'For our first approach, we decided on simple automated heuristics to figure out where objects are placed in a picture, both horizontally and vertically. This idea came from an assumption that GPT-4V might use algorithms found in publicly available code for tasks of a similar nature.
For the second approach, we used labeling with crowdsourcing. Here are the details on how the crowdsourcing project was set up:
- Images were shown to the crowd without bounding boxes to encourage less biased (on a ground truth answer) labeling of an object’s location, as one would in responding to a query regarding the object’s placement in a visual context.
- GPT-4V’s answers were displayed as both a hint and a way to validate its object detection accuracy.
- Participants had the option to report if a question couldn’t be clearly answered with the given image, removing any potential ambiguous/grey-zone cases from the dataset.
To ensure the quality of the crowdsourced responses, I reviewed all instances where GPT-4’s answers didn’t match the crowd’s. I couldn’t see either GPT-4V’s or the crowd’s responses during this review process, which allowed me to adjust the labels without preferential bias.
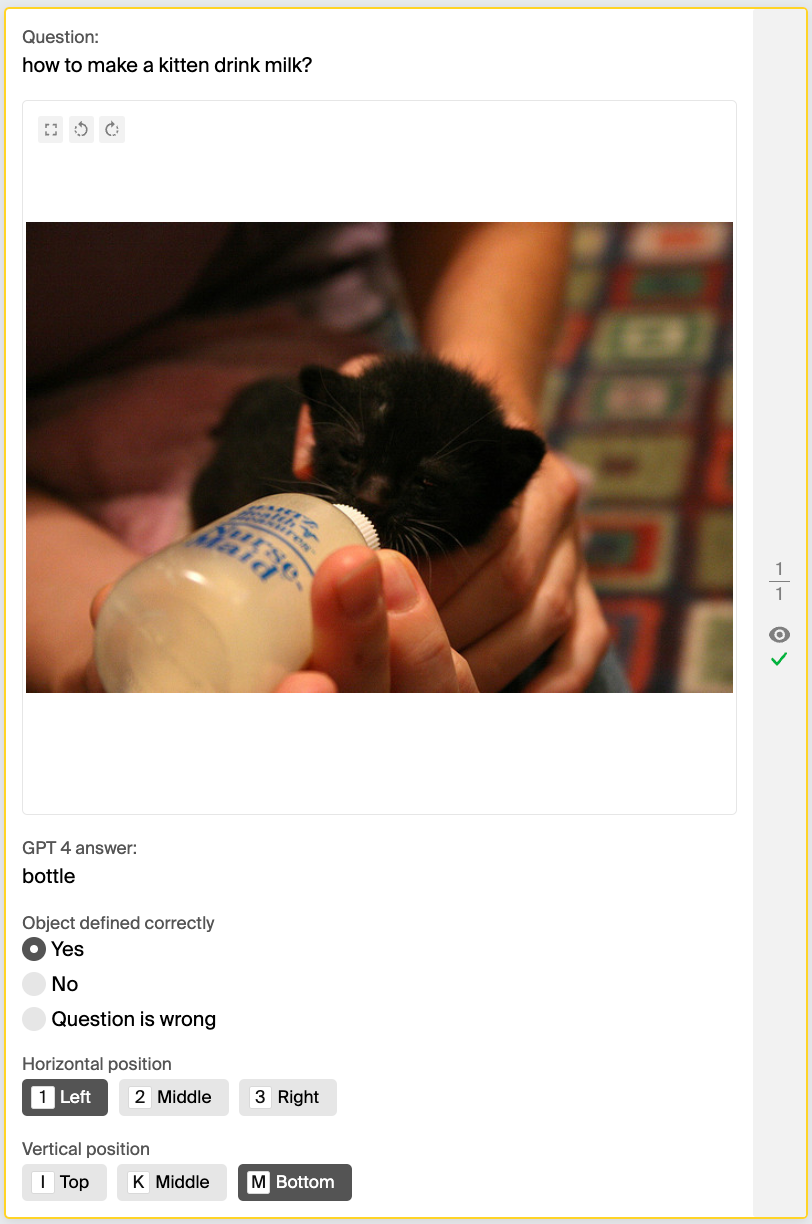
GPT-4V has directional dyslexia
We opted for accuracy as our evaluation metric because the classes in our dataset were evenly distributed. After evaluating GPT-4V’s performance against the ground truth — established through crowdsourcing and heuristic methods — on 475 images, we excluded 45 pairs that the crowd found difficult to answer. The remaining data revealed that GPT-4V’s accuracy in identifying both horizontal and vertical positions was remarkably low, at around 30%, when compared to both the crowdsourced and heuristic labels.


Even when we accepted GPT-4V’s answer as correct if it matched either the crowdsourced or heuristic approach, its accuracy still didn’t reach 50%, resulting in 40.2%.
To further validate these findings, we manually reviewed 100 image-question pairs that GPT-4V had incorrectly labeled.

By directly asking GPT-4V to specify the objects’ locations and comparing its responses, we confirmed the initial results.
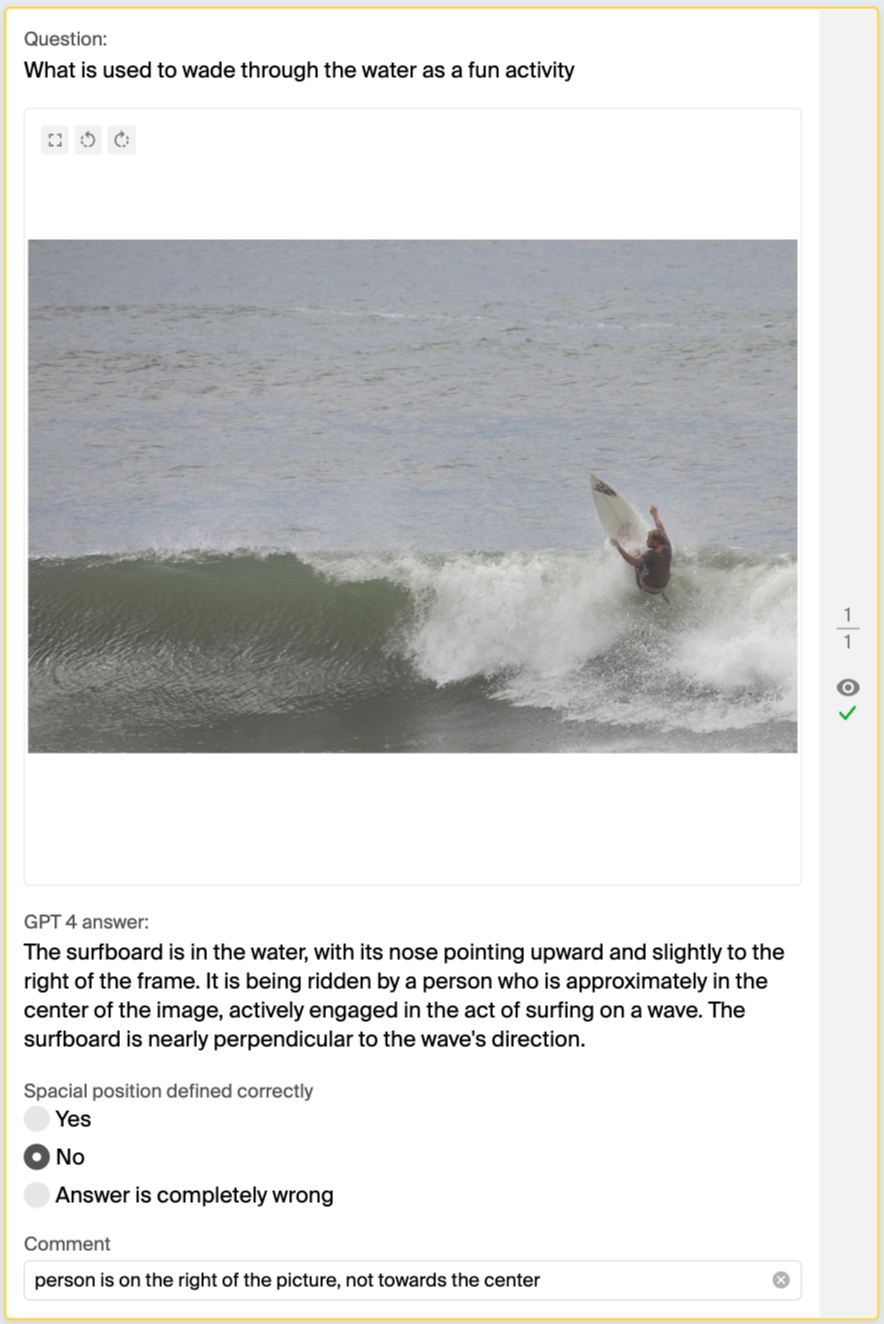
GPT-4V consistently confused left and right, top and bottom, so if GPT-4V is your navigator, be prepared to take the scenic route — unintentionally.
However, GPT-4V’s object recognition capabilities are impressive, achieving an accuracy rate of 88.84%. This suggests that by integrating GPT-4V with specialized object detection tools, we could potentially match (or even exceed) the human baseline. This is the next objective of our research.
Prompt engineering & directional dyslexia
To ensure we’re not pointing out the limitations of GPT-4V without any prompt optimization efforts, so as not to become what we hate, we explored various prompt engineering techniques mentioned in the research literature as ones enhancing spatial reasoning in LLMs.
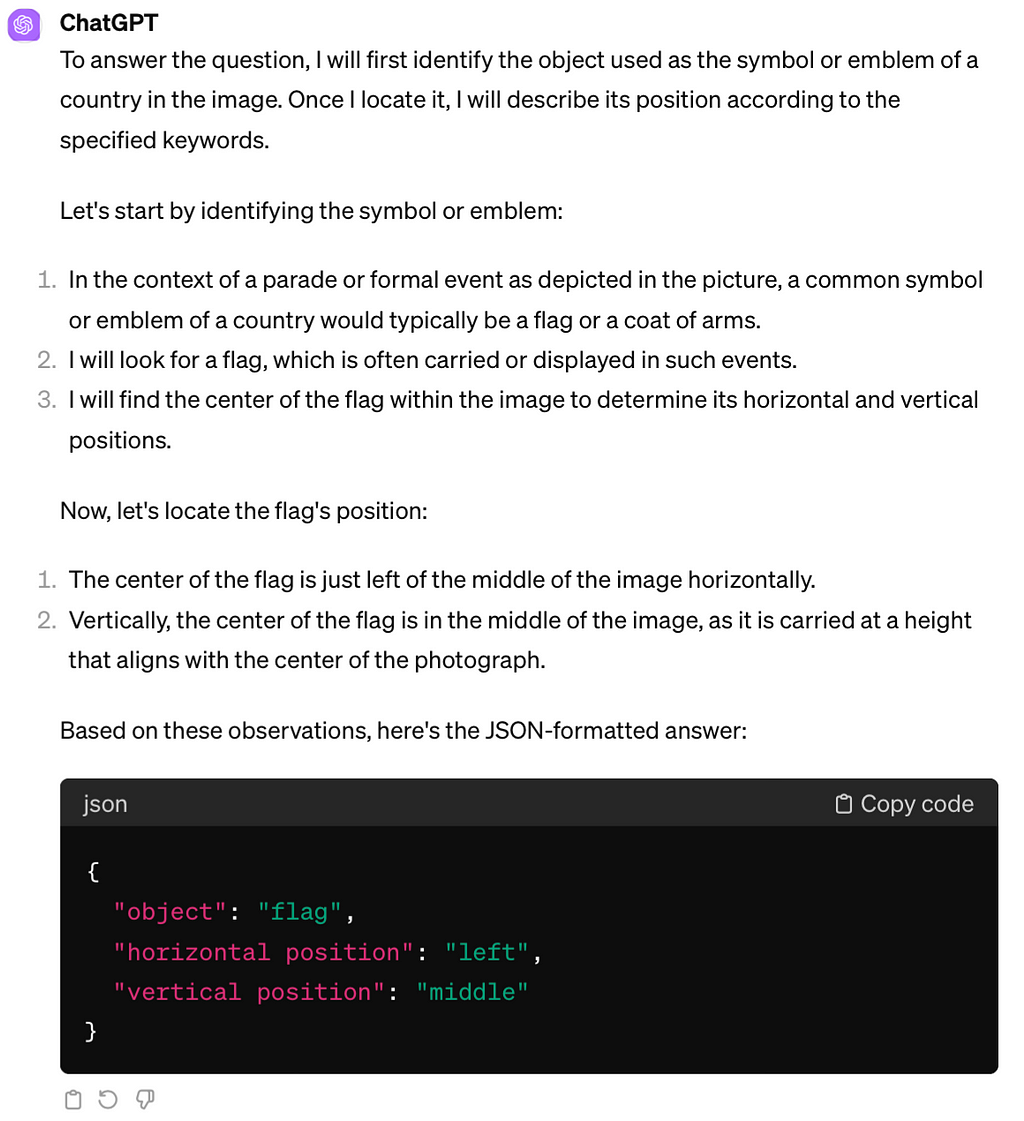
Question: What is used as the symbol or emblem of a country?

We applied three discovered prompt engineering techniques on the experimental dataset example above that GPT-4V stubbornly and consistently misinterpreted. The flag which is asked about is located in the middle-right of the picture.
The “Shikra: Unleashing Multimodal LLM’s Referential Dialogue Magic” paper introduces a method combining Chain of Thought (CoT) with position annotations, specifically center annotations, called Grounding CoT (GCoT). In the GCoT setting, the authors prompt the model to provide CoT along with center points for each mentioned object. Since the authors specifically trained their model to provide coordinates of objects on an image, we had to adapt the prompt engineering technique to a less strict setting, asking the model to provide reasoning about the object’s location based on the center of the object.

The study “Mapping Language Models to Grounded Conceptual Spaces” by Patel & Pavlick (2022) illustrates that GPT-3 can grasp spatial and cardinal directions even within a text-based grid by ‘orienting’ the models with specific word forms learned during training. They substitute traditional directional terms using north/south and west/east instead of top/bottom and left/right, to guide the model’s spatial reasoning.

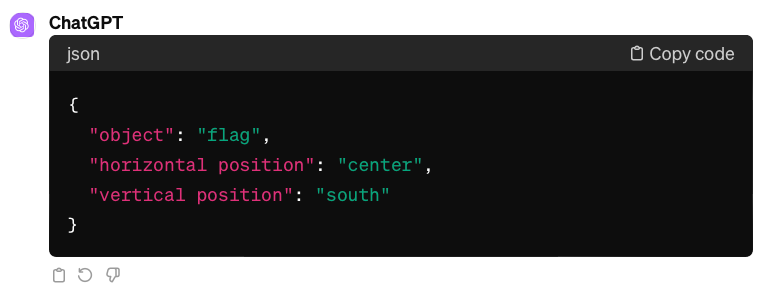
Lastly, the “Visual Spatial Reasoning” article states the significance of different perspectives in spatial descriptions: the intrinsic frame centered on an object (e.g. behind the chair = side with a backrest), the relative frame from the viewer’s perspective, and the absolute frame using fixed coordinates (e.g. “north” of the chair). English typically favors the relative frame, so we explicitly mentioned it in the prompt, hoping to refine GPT-4V’s spatial reasoning.

As we can see from the examples, GPT-4V’s challenges with basic spatial reasoning persist.
Conclusions and future work
GPT-4V struggles with simple spatial reasoning, like identifying object horizontal and vertical positions on a high level in images. Yet its strong object recognition skills based just on implicit functional descriptions are promising. Our next step is to combine GPT-4V with models specifically trained for object detection in images. Let’s see if this combination can beat the human baseline in the Toloka VQA challenge!
GPT-4V Has Directional Dyslexia was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
Originally appeared here:
GPT-4V Has Directional Dyslexia