Understanding techniques for encoding geographic coordinates in a neural network

An inductive bias in machine learning is a constraint on a model given some prior knowledge of the target task. As humans, we can recognize a bird whether it’s flying in the sky or perched in a tree. Moreover, we don’t need to examine every cloud or take in the entirety of the tree to know that we are looking at a bird and not something else. These biases in the vision process are encoded in convolution layers via two properties:
- Weight sharing: the same kernel weights are re-used along an input channel’s full width and height.
- Locality: the kernel has a much smaller width and height than the input.
We can also encode inductive biases in our choice of input features to the model, which can be interpreted as a constraint on the model itself. Designing input features for a neural network involves a trade-off between expressiveness and inductive bias. On one hand, we want to allow the model the flexibility to learn patterns beyond what we humans can detect and encode. On the other hand, a model without any inductive biases will struggle to learn anything meaningful at all.
In this article, we will explore the inductive biases that go into designing effective position encoders for geographic coordinates. Position on Earth can be a useful input to a wide range of prediction tasks, including image classification. As we will see, using latitude and longitude directly as input features is under-constraining and ultimately will make it harder for the model to learn anything meaningful. Instead, it is more common to encode prior knowledge about latitude and longitude in a nonparametric re-mapping that we call a positional encoder.
Introduction: Position Encoders in Transformers
To motivate the importance of choosing effective position encoder more broadly, let’s first examine the well-known position encoder in the transformer model. We start with the notion that the representation of a token input to an attention block should include some information about its position in the sequence it belongs to. The question is then: how should we encode the position index (0, 1, 2…) into a vector?
Assume we have a position-independent token embedding. One possible approach is to add or concatenate the index value directly to this embedding vector. Here is why this doesn’t work well:
- The similarity (dot product) between two embeddings — after their position has been encoded — should be independent of the total number of tokens in the sequence. The two last tokens of a sequence should record the same similarity whether the sequence is 5 or 50 words long.
- The similarity between two tokens should not depend on the absolute value of their positions, but only the relative distance between them. Even if the encoded indices were normalized to the range [0, 1], two adjacent tokens at positions 1 and 2 would record a lower similarity than the same two tokens later in the sequence.
The original “Attention is All You Need” paper [1] proposes instead to encode the position index pos into a discrete “snapshot” of k different sinusoids, where k is the dimension of the token embeddings. These snapshots are computed as follows:
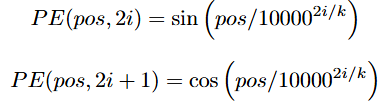
where i = 1, 2, …, k / 2. The resulting k-dimensional position embedding is then added elementwise to the corresponding token embedding.
The intuition behind this encoding is that the more snapshots are out of phase for any two embeddings, the further apart are their corresponding positions. The absolute value of two different positions will not influence how out of phase their snapshots are. Moreover, since the range of any sinusoid is the interval [-1, 1], the magnitude of the positional embeddings will not grow with sequence length.
I won’t go into more detail on this particular position encoder since there are several excellent blog posts that do so (see [2]). Hopefully, you can now see why it is important, in general, to think carefully about how position should be encoded.
Geographic Position Encoders
Let’s now turn to encoders for geographic position. We want to train a neural network to predict some variable of interest given a position on the surface of the Earth. How should we encode a position (λ, ϕ) in spherical coordinates — i.e. a longitude/latitude pair — into a vector that can be used as an input to our network?
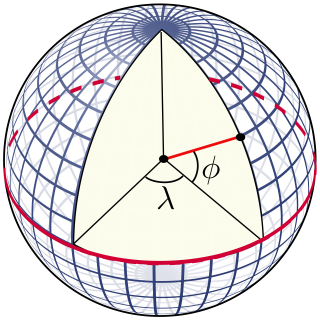
Simple approach
One possible approach would be to use latitude and longitude values directly as inputs. In this case our input feature space would be the rectangle [-π, π] × [0, π], which I will refer to as lat/lon space. As with position encoders for transformers, this simple approach unfortunately has its limitations:
- Notice that as you move towards the poles, the distance on the surface of the Earth covered by 1 unit of longitude (λ) decreases. Lat/lon space does not preserve distances on the surface of the Earth.
- Notice that the position on Earth corresponding to coordinates (λ, ϕ) should be identical to the position corresponding to (λ + 2π, ϕ). But in lat/lon space, these two coordinates are very far apart. Lat/lon space does not preserve periodicity: the way spherical coordinates wrap around the surface of the Earth.
To learn anything meaningful directly from inputs in lat/long space, a neural network must learn how to encode these properties about the curvature of the Earth’s surface on its own — a challenging task. How can we instead design a position encoder that already encodes these inductive biases? Let’s explore some early approaches to this problem and how they have evolved over time.
Early Position Encoders
Discretization-based (2015)
The first paper to propose featurizing geographic coordinates for use as input to a convolutional neural network is called “Improving Image Classification with Location Context” [3]. Published in 2015, this work proposes and evaluates many different featurization approaches with the goal of training better classification models for geo-tagged images.
The idea behind each of their approaches is to directly encode a position on Earth into a set of numerical features that can be computed from auxiliary data sources. Some examples include:
- Dividing the U.S. into evenly spaced grids in lat/lon space and using a one-hot encoding to encode a given location into a vector based on which grid it falls into.
- Looking up the U.S ZIP code that corresponds to a given location, then retrieving demographic data about this ZIP code from ACS (American Community Survey) related to age, sex, race, living conditions, and more. This is made into a numerical vector using one-hot encodings.
- For a chosen set of Instagram hashtags, counting how many hashtags are recorded at different distances from a given location and concatenating these counts into a vector.
- Retrieving color-coded maps from Google Maps for various features such as precipitation, land cover, congressional district, and concatenating the numerical color values from each into a vector.
Note that these positional encodings are not continuous and do not preserve distances on the surface of the Earth. In the first example, two nearby locations that fall into different grids will be equally distant in feature space as two locations from opposite sides of the country. Moreover, these features mostly rely on the availability of auxiliary data sources and must be carefully hand-crafted, requiring a specific choice of hashtags, map features, survey data, etc. These approaches do not generalize well to arbitrary locations on Earth.
WRAP (2019)
In 2019, a paper titled “Presence-Only Geographical Priors for Fine-Grained Image Classification” [4] took an important step towards the geographic position encoders commonly used today. Similar to the work from the previous section, this paper studies how to use geographic coordinates for improving image classification models.
The key idea behind their position encoder is to leverage the periodicity of sine and cosine functions to encode the way geographic coordinates wrap around the surface of the Earth. Given latitude and longitude (λ, ϕ), both normalized to the range [-1, 1], the WRAP position encoder is defined as:
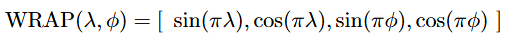
Unlike the approaches in the previous section, WRAP is continuous and easily computed for any position on Earth. The paper then shows empirically that training a fully-connected network on top of these features and combining them with latent image features can lead to improved performance on fine-grained image classification benchmarks.
The Double Fourier Sphere Method
The WRAP encoder appears simple, but it successfully encodes a key inductive bias about geographic position while remaining expressive and flexible. In order to see why this choice of position encoder is so powerful, we need to understand the Double Fourier Sphere (DFS) method [5].
DFS is a method of transforming any real-valued function f (x, y, z) defined on the surface of a unit sphere into a 2π-periodic function defined on a rectangle [-π, π] × [-π, π]. At a high level, DFS consists of two steps:
- Re-parametrize the function f (x, y, z) using spherical coordinates, where (λ, ϕ) ∈ [-π, π] × [0, π]
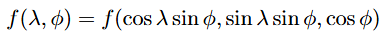
2. Define a new piece-wise function over the rectangle [-π, π] × [-π, π] based on the re-parametrized f (essentially “doubling it over”).
Notice that the DFS re-parametrization of the Earth’s surface (step 1.) preserves the properties we discussed earlier. For one, as ϕ tends to 0 or ± π (the Earth’s poles), the distance between two points (λ, ϕ) and (λ’, ϕ) after re-parametrization decreases. Moreover, the re-parametrization is periodic and smooth.
Fourier Theorem
It is a fact that any continuous, periodic, real-valued function can be represented as a weighted sum of sines and cosines. This is called the Fourier Theorem, and this weighted sum representation is called a Fourier series. It turns out that any DFS-transformed function can be represented with a finite set of sines and cosines. They are known as DFS basis functions, listed below:
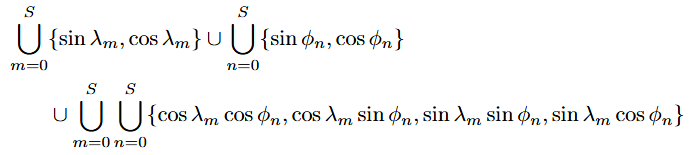
Here, ∪ denotes union of sets, and S is a collection of scales (i.e. frequencies) for the sinusoids.
DFS-Based Position Encoders
Notice that the set of DFS basis functions includes the four terms in the WRAP position encoder. “Sphere2Vec” [6] is the earliest publication to observe this, proposing a unified view of position encoders based on DFS. In fact, with this generalization in mind, we can construct a geographic position encoder by choosing any subset of the DFS basis functions — WRAP is just one such choice. Take a look at [7] for a comprehensive overview of various DFS-based position encoders.
Why are DFS-based encoders so powerful?
Consider what happens when a linear layer is trained on top of a DFS-based position encoder: each output element of the network is a weighted sum of the chosen DFS basis functions. Hence, the network can be interpreted as a learned Fourier series. Since virtually any function defined on the surface of a sphere can be transformed using the DFS method, it follows that a linear layer trained on top of DFS basis functions is powerful enough to encode arbitrary functions on the sphere! This is akin to the universal approximation theorem for multilayer perceptrons.
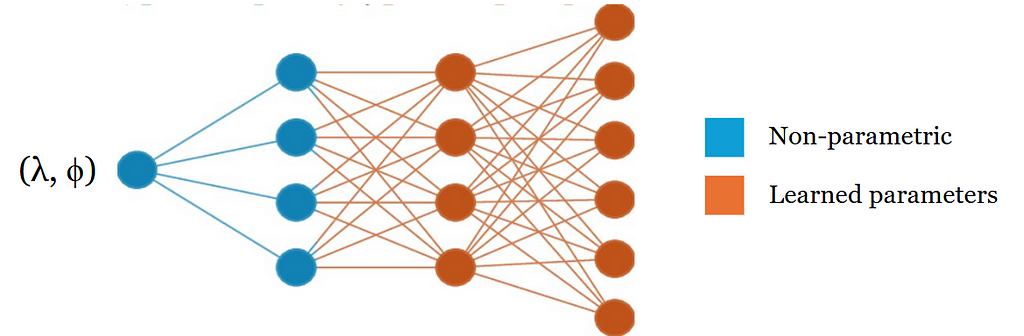
In practice, only a small subset of the DFS basis functions is used for the position encoder and a fully-connected network is trained on top of these. The composition of a non-parametric position encoder with a neural network is commonly referred to as a location encoder:
Geographic Location Encoders Today
As we have seen, a DFS-based position encoder can effectively encode inductive biases we have about the curvature of the Earth’s surface. One limitation of DFS-based encoders is that they assume a rectangular domain [-π, π] × [-π, π]. While this is mostly fine since the DFS re-parametrization already accounts for how distances get warped closer to the poles, this assumption breaks down at the poles themselves (ϕ = 0, ± π), which are lines in the rectangular domain that collapse to singular points on the Earth’s surface.
A different set of basis functions called spherical harmonics have recently emerged as an alternative. Spherical harmonics are basis functions that are natively defined on the surface of the sphere as opposed to a rectangle. They have been shown to exhibit fewer artifacts around the Earth’s poles compared to DFS-based encoders [7]. Notably, spherical harmonics are the basis functions used in the SatCLIP location encoder [8], a recent foundation model for geographic coordinates trained in the style of CLIP.
Though geographic position encoders began with discrete, hand-crafted features in the 2010s, these do not easily generalize to arbitrary locations and require domain-specific metadata such as land cover and demographic data. Today, geographic coordinates are much more commonly used as neural network inputs because simple yet meaningful and expressive ways of encoding them have emerged. With the rise of web-scale datasets which are often geo-tagged, the potential for using geographic coordinates as inputs for prediction tasks is now immense.
References
[1] A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, L. Kaiser & I. Polosukhin, Attention Is All You Need (2017), 31st Conference on Neural Information Processing Systems
[2] A Kazemnejad, Transformer Architecture: The Positional Encoding (2019), Amirhossein Kazemnejad’s Blog
[3] K. Tang, M. Paluri, L. Fei-Fei, R. Fergus, L. Bourdev, Improving Image Classification with Location Context (2015)
[4] O. Mac Aodha, E. Cole, P. Perona, Presence-Only Geographical Priors for Fine-Grained Image Classification (2019)
[5] Double Fourier Sphere Method, Wikipedia
[6] G. Mai, Y. Xuan, W. Zuo, K. Janowicz, N. Lao Sphere2Vec: Multi-Scale Representation Learning over a Spherical Surface for Geospatial Predictions (2022)
[7] M. Rußwurm, K. Klemmer, E. Rolf, R. Zbinden, D. Tuia, Geographic Location Encoding with Spherical Harmonics and Sinusoidal Representation Network (2024), ICLR 2024
[8] K. Klemmer, E. Rolf, C. Robinson, L. Mackey, M. Rußwurm, SatCLIP: Global, General-Purpose Location Embeddings with Satellite Imagery (2024)
Geographic Position Encoders was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
Originally appeared here:
Geographic Position Encoders