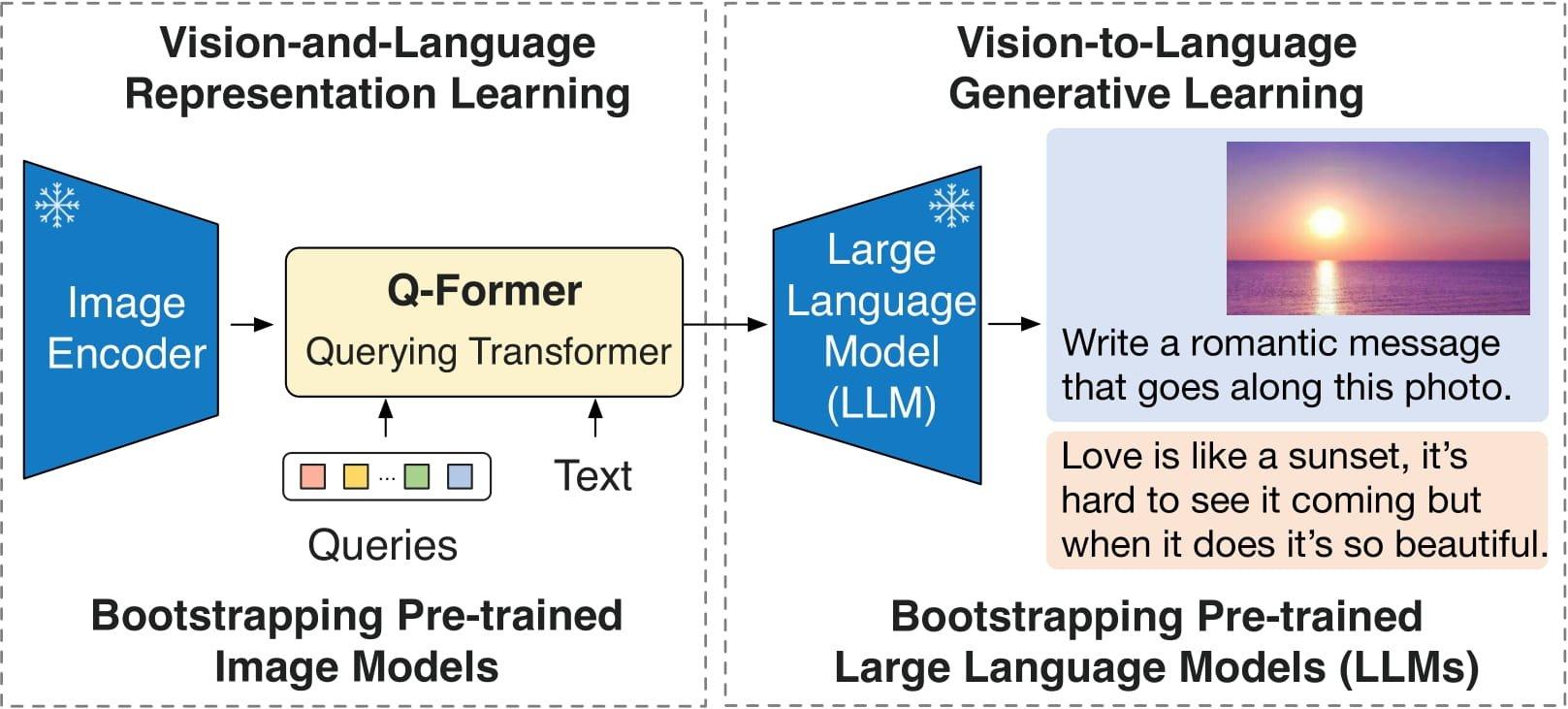

This post shows you how to predict domain-specific product attributes from product images by fine-tuning a VLM on a fashion dataset using Amazon SageMaker, and then using Amazon Bedrock to generate product descriptions using the predicted attributes as input. So you can follow along, we’re sharing the code in a GitHub repository.
Originally appeared here:
Generating fashion product descriptions by fine-tuning a vision-language model with SageMaker and Amazon Bedrock