

DEEP LEARNING PAPERS
5-Minute Deep Dive into the Paper
Introduction
Last week, NVIDIA published a fascinating paper (LLaMA-Mesh: Unifying 3D Mesh Generation with Language Models) that allows the generation of 3D mesh objects using natural language.
In simple words, if you can say, “Tell me a joke,” now you can say, “Give me the 3D mesh for a car,” and it can give the output in the OBJ format (more on this shortly) containing the output.
If you’d like to try out few examples, you can do so here — https://huggingface.co/spaces/Zhengyi/LLaMA-Mesh
The most amazing part for me was that it did so without extending the vocabulary or introducing new tokens as is typical for most fine-tuning tasks.
But first, what is a 3D mesh?
A 3D mesh is a digital representation of a 3D object that consists of vertices, edges, and faces.
For example, consider a cube. It has 8 vertices (the corners), 12 edges (the lines connecting the corners), and 6 faces (the square sides). This is a basic 3D mesh representation of a cube. The cube’s vertices (v) define its corners, and the faces (f) describe how those corners connect to form the surfaces.
Here is an example of OBJ file that represents the geometry of the 3D object
# Vertices
v: (0, 0, 0)
v: (1, 0, 0)
v: (1, 1, 0)
v: (0, 1, 0)
v: (0, 0, 1)
v: (1, 0, 1)
v: (1, 1, 1)
v: (0, 1, 1)
# Faces
f 1 2 3 4
f 5 6 7 8
f 1 5 8 4
f 2 6 7 3
f 4 3 7 8
f 1 2 6 5
These numbers are then interpreted by software that will render the final image i.e. 3D cube. (or you can use HuggingFace spaces like this to render the object)
As objects increase in complexity (compared to the simple cube above), they will have thousands or even millions of vertices, edges, and faces to create detailed shapes and textures. Additionally, they will have more dimensions to capture things like texture, direction it is facing, etc.
Realistically speaking, this is what the obj file for an everyday object (a bench) would look like:
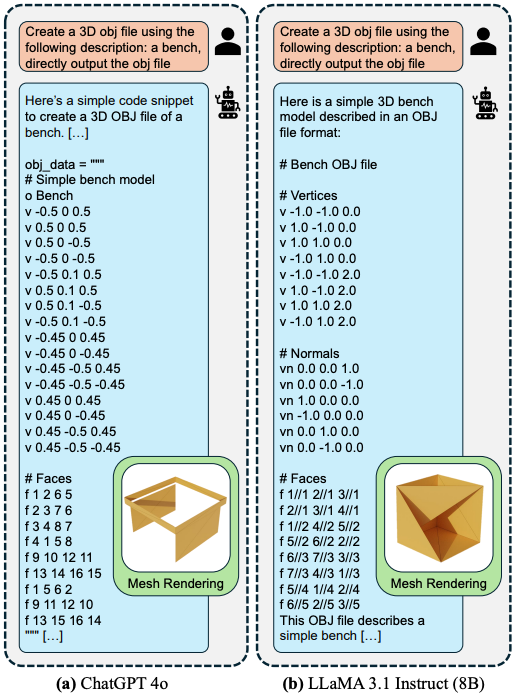
As you may have noticed from the image above, LLMs like GPT4o and LLama3.1 are capable, to some extent, of producing the obj file out-of-the-box. However, if you look at the rendered mesh image of the bench in both cases, you can see why fine-tuning is necessary from a quality standpoint.
How is an LLM able to work with 3D mesh?
It is common knowledge that LLMs understand text by converting tokens (like cat) into token ids (like 456). Similarly, in order to work with the standard OBJ format, we must somehow convert the vertices coordinates which are typically decimals into integers.
They use vertex quantization to achieve this in the paper and split a single coordinate into multiple tokens (similar to how a long word like operational would be split into two tokens — oper and ational as per GPT4o tokenizer). As expected, reducing the number of tokens to represent the decimal has a normal precision-cost tradeoff.

To achieve vertex quantization, they scale all three axes in the mesh to the range (0, 64) and quantize the coordinates to the nearest integer, i.e. each of the 3 axes can take a value between 0 and 64 (in this case 39, 19 and 35). Finally, by reading and generating such a format, the LLM is able to work with 3D objects.
What was the training procedure for LlaMa-Mesh?
LLama-Mesh was created by fine-tuning LLama3.1–8B instruct model using the SFT (Supervised Fine Tuning) method to improve its mesh understanding and generation capabilities.
Since it is an SFT, we need to provide it with input-output examples of Text-3D instructions. Here’s an example:
Input
User: Create a 3D obj file using the following description: a 3D model of a car.
Output
Assistant: <start of mesh> v 0 3 4 v 0 4 6 v 0 3 … f 1 3 2 f 4 3 5 … . <end of mesh>
In addition to generating the 3D mesh, LLama-Mesh is also capable of interpreting the 3d mesh. To this end, its training data also contained several examples for mesh understanding and mesh generation as part of a conversation-style format. Here are a few examples from the dataset

Most interesting bits from the paper
- LlaMa-Mesh can communicate with both text and 3D objects without needing special tokenizers or extending the LLM’s vocabulary (thanks to the use of OBJ format and the vertex quantization discussed above which can effectively tokenize 3D mesh data into discrete tokens that LLMs can process seamlessly).

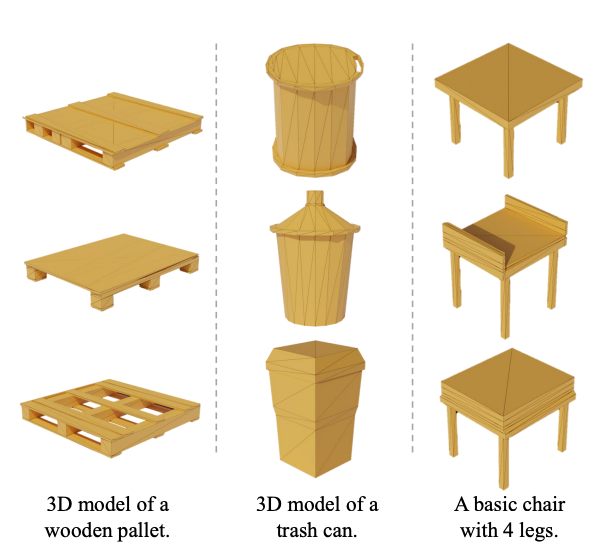
- LlaMa-Mesh can generate diverse shapes from the same input text.
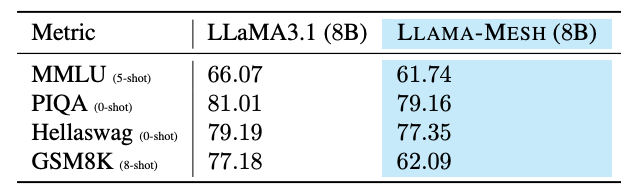
- Even though the fine-tuning process slightly degraded the model’s underlying language understanding and reasoning capabilities (they call it out as a limitation imposed by the choice of instruction dataset, and size of the smaller 8B model), it is offset by the fact that the fine-tuned model can generate high-quality OBJ files for 3D mesh generation.
Why should you care about this paper?
I am already amazed by the capabilities of large language models to generate human-like text, code, and reason with visual content. Adding 3D mesh to this list is just brilliant.
LLMs like LLaMa-Mesh have the potential to revolutionize various industries including gaming, education, and healthcare.
It can be useful for generating realistic assets like characters, environments, and objects directly from text descriptions for video games.
Similarly, it can speed up the product development and ideation process as any company will require a design so they know what to create.
It can also be useful for architectural designs for buildings, machinery, bridges, and other infrastructure projects. Finally, in the edtech space, it can be used for embedding interactive 3D simulations within the training material.
The paper is a straightforward and quick read, and I highly encourage you to do it.
Paper page — https://arxiv.org/pdf/2411.09595
Code — https://github.com/nv-tlabs/LLaMA-Mesh
Nvidia’s Blog — https://research.nvidia.com/labs/toronto-ai/LLaMA-Mesh/
Generate 3D Images with Nvidia’s LLaMa-Mesh was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
Originally appeared here:
Generate 3D Images with Nvidia’s LLaMa-Mesh
Go Here to Read this Fast! Generate 3D Images with Nvidia’s LLaMa-Mesh