

This blog post will go into detail about a cost-saving architecture for LLM-driven apps as seen in the “FrugalGPT” paper
Large Language Models open up a new frontier for computer science, however, they are (as of 2024) significantly more expensive to run than almost anything else in computer science. For companies looking to minimize their operating costs, this poses a serious problem. The “FrugalGPT: How to Use Large Language Models While Reducing Cost and Improving Performance” paper introduces one framework to reduce operating costs significantly while maintaining quality.
How to Measure the Cost of LLM
There are multiple ways to determine the cost of running a LLM (electricity use, compute cost, etc.), however, if you use a third-party LLM (a LLM-as-a-service) they typically charge you based on the tokens you use. Different vendors (OpenAI, Anthropic, Cohere, etc.) have different ways of counting the tokens, but for the sake of simplicity, we’ll consider the cost to be based on the number of tokens processed by the LLM.
The most important part of this framework is the idea that different models cost different amounts. The authors of the paper conveniently assembled the below table highlighting the difference in cost, and the difference between them is significant. For example, AI21’s output tokens cost an order of magnitude more than GPT-4’s does in this table!

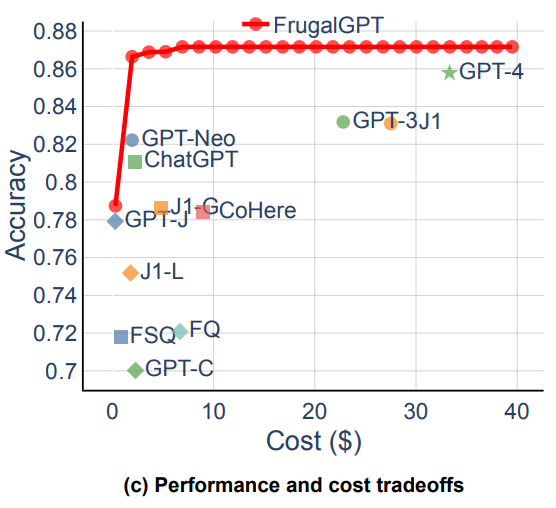
As a part of cost optimization we always need to figure out a way to optimize the answer quality while minimizing the cost. Typically, higher cost models are often higher performing models, able to give higher quality answers than lower cost ones. The general relationship can be seen in the below graph, with Frugal GPT’s performance overlaid on top in red.
Maximizing Quality with Cascading LLMS
Using the vast cost difference between models, the researchers’ FrugalGPT system relies on a cascade of LLMs to give the user an answer. Put simply, the user query begins with the cheapest LLM, and if the answer is good enough, then it is returned. However, if the answer is not good enough, then the query is passed along to the next cheapest LLM.
The researchers used the following logic: if a less expensive model answers a question incorrectly, then it is likely that a more expensive model will give the answer correctly. Thus, to minimize costs the chain is ordered from least expensive to most expensive, assuming that quality goes up as you get more expensive.
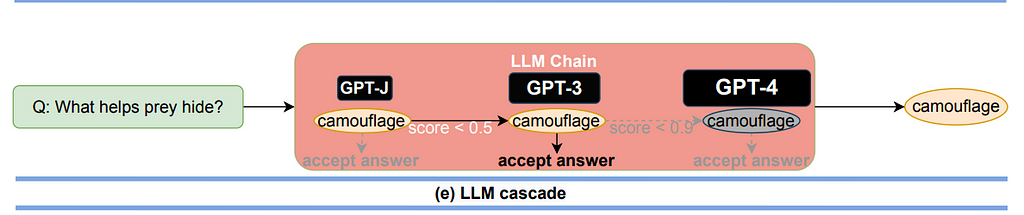
This setup relies on reliably determining when an answer is good enough and when it isn’t. To solve for this, the authors created a DistilBERT model that would take the question and answer then assign a score to the answer. As the DistilBERT model is exponentially smaller than the other models in the sequence, the cost to run it is almost negligible compared to the others.
Better Average Quality Than Just Querying the Best LLM
One might naturally ask, if quality is most important, why not just query the best LLM and work on ways to reduce the cost of running the best LLM?
When this paper came out GPT-4 was the best LLM they found, yet GPT-4 did not always give a better answer than the FrugalGPT system! (Eagle-eyed readers will see this as part of the cost vs performance graph from before) The authors speculate that just as the most capable person doesn’t always give the right answer, the most complex model won’t either. Thus, by having the answer go through a filtering process with DistilBERT, you are removing any answers that aren’t up to par and increasing the odds of a good answer.
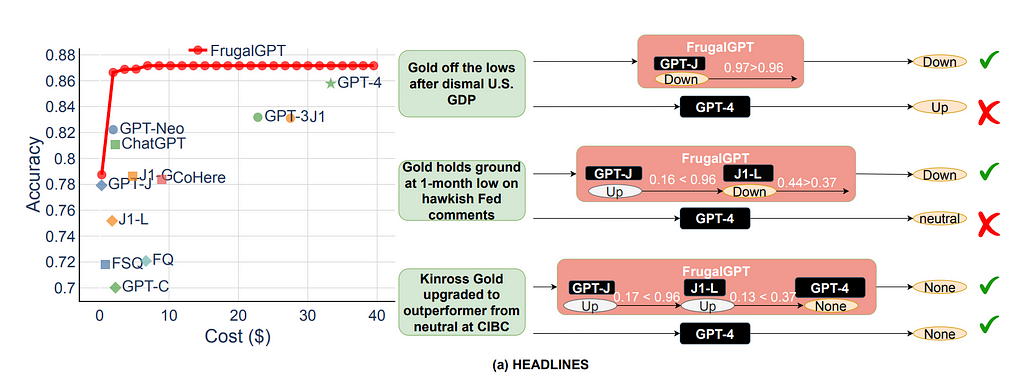
Consequently, this system not only reduces your costs but can also increase quality more so than just using the best LLM!
Moving Forwards with Cost Savings
The results of this paper are fascinating to consider. For me, it raises questions about how we can go even further with cost savings without having to invest in further model optimization.
One such possibility is to cache all model answers in a vector database and then do a similarity search to determine if the answer in the cache works before starting the LLM cascade. This would significantly reduce costs by replacing a costly LLM operation with a comparatively less expensive query and similarity operation.
Additionally, it makes you wonder if outdated models can still be worth cost-optimizing, as if you can reduce their cost per token, they can still create value on the LLM cascade. Similarly, the key question here is at what point do you get diminishing returns by adding new LLMs onto the chain.
Questions for Further Study
As the world creates more LLMs and we increasingly build systems that use them, we will want to find cost-effective ways to run them. This paper creates a strong framework for future builders to expand on, making me wonder about how far this framework can go.
In my opinion, this framework applies really well for general queries that do not have different answers based on different users, such as a tutor LLM. However, for use cases where answers differ based on the user, say a LLM that acts as a customer service agent, the scoring system would have to be aware of who the LLM was talking with.
Finding a framework that saves money for user-specific interactions will be important for the future.
[1] Chen, L., et al., FrugalGPT: How to Use Large Language Models While Reducing Cost and Improving Performance (2023), arXiv
FrugalGPT and Reducing LLM Operating Costs was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
Originally appeared here:
FrugalGPT and Reducing LLM Operating Costs
Go Here to Read this Fast! FrugalGPT and Reducing LLM Operating Costs