A comprehensive tutorial: Using advanced techniques like prompt adaptation and adapters to transform open-source unimodal models into multimodal ones, including all variants of LLaMA-Adapters, LLaVa, MiniGPT-4, and more.
Authors: Elahe Aghapour, Salar Rahili
INTRODUCTION
With recent advancements in large language models (LLMs), AI has become the spotlight of technology. We’re now more eager than ever to reach AGI-level intelligence. Yet, achieving a human-like understanding of our surroundings involves much more than just mastering language and text comprehension. Humans use their five senses to interact with the world and act based on these interactions to achieve goals. This highlights that the next step for us is to develop large models that incorporate multimodal inputs and outputs, bringing us closer to human-like capabilities. However, we face two main obstacles. First, we need a multimodal labeled dataset, which is not as accessible as text data. Second, we are already pushing the limits of compute capacity for training models with textual data. Increasing this capacity to include other modalities, especially high-dimensional ones like images and videos, is incredibly challenging.
These limitations have been a barrier for many AI researchers aiming to create capable multimodal models. So far, only a few well-established companies like Google, Meta, and OpenAI have managed to train such models. However, none of these prominent models are open source, and only a few APIs are available for public use. This has forced researchers, especially in academia, to find ways to build multimodal models without massive compute capabilities, relying instead on open-sourced pre-trained models, which are mostly single modal.
In this blog, we focus on successful, low-effort approaches to creating multi-modal models. Our criteria are centered on projects where the compute costs remain a few thousand dollars, assuming this is within the budget a typical lab can afford.
1- Parameter-Efficient Fine-Tuning (PEFT)
Before we dive into the proposed approaches for integrating and aligning two pre-trained models, we need to discuss the mechanics of fine-tuning a large model with limited compute power. Therefore, we’ll start by exploring Parameter-Efficient Fine-Tuning (PEFT) and then describe how these methods can be further used to align pre-trained models and build open-source multimodal models.
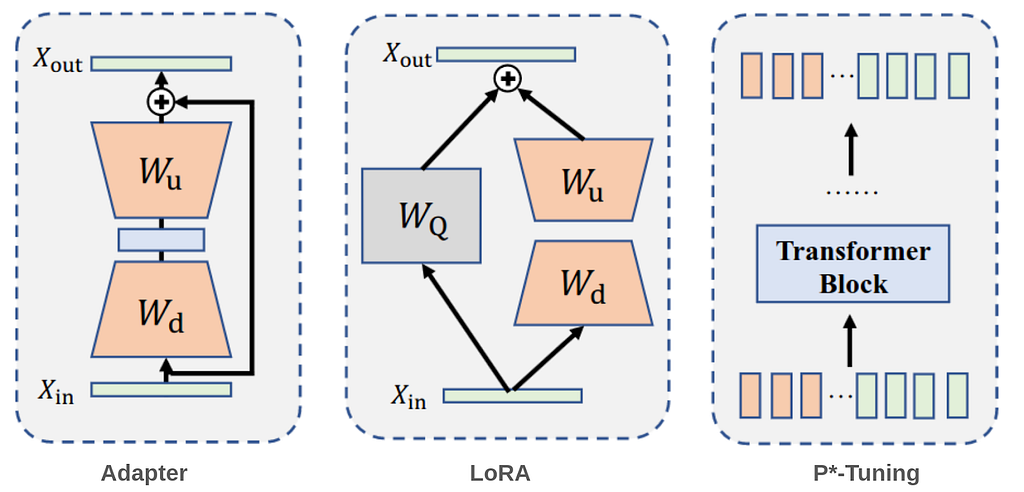
As model sizes continue to grow, the need for efficient fine-tuning methods becomes more critical. Fine-tuning all parameters in a large-scale pre-trained model is often impractical due to the substantial computational resources and time required. Parameter-efficient fine-tuning (PEFT) addresses this challenge by freezing the model’s parameters and only training the injected modules with a small number of parameters. Hence, only one copy of the large Transformer is stored with learned task specific lightweight PEFT modules, yielding a very small overhead for each additional task. This approach not only reduces resource demands but also accelerates the adaptation of models to new tasks, making it a practical and effective strategy in the era of ever-expanding models. PEFT approaches are very commonly used in LLMs and giant vision models and can be mainly divided into three categories as shown in Fig. 1: Among several methods that have been proposed, three have gotten significant attention from the community.
1- adapters: An adapter is essentially a small module, typically consisting of a downsample layer, nonlinearity, and an upsample layer with a skip connection to preserve the original input. This module is inserted into a pretrained model, with only the adapters being trained during fine-tuning.
2- LoRA injects trainable low-rank decomposition matrices into the model to approximate weight updates, significantly reducing the number of trainable parameters for downstream tasks. For a pre-trained weight matrix W of dimensions d×k, LoRA represents its update with a low-rank decomposition: W+ΔW=W+DU
where D has dimensions d×r and U has dimensions r×k. These matrices D and U are the tunable parameters. LoRA can be applied to the attention matrices and/or the feedforward module for efficient finetuning.
3- P*-tuning (prefix-tuning, prompt tuning) typically prepend a set of learnable prefix vectors or tokens to the input embedding, and only these so-called “soft prompts” are trained when fine-tuning on downstream tasks. The philosophy behind this approach is to assist the pre-trained models in understanding downstream tasks with the guidance of a sequence of extra “virtual tokens” information. Soft prompts are sequences of vectors that do not correspond to actual tokens in the vocabulary. Instead, they serve as intermediary representations that guide the model’s behavior to accomplish specific tasks, despite having no direct linguistic connection to the task itself.
Evaluating PEFT Techniques: Strengths and Limitations:
Adapters add a small number of parameters (3–4% of the total parameters) which makes them more efficient than full fine-tuning but less than prompt tuning or LoRA. However, they are capable of capturing complex task-specific information effectively due to the additional neural network layers and often achieve high performance on specific tasks by learning detailed task-specific features. On the downside, this approach makes the model deeper, which can complicate the optimization process and lead to longer training times.
LoRa adds only a small fraction of parameters (0.1% to 3%), making it highly efficient and scalable with very large models, making it suitable for adapting state-of-the-art LLMs and VLMs. However, LoRA’s adaptation is constrained to what can be expressed within the low-rank structure. While efficient, LoRA might be less flexible compared to adapters in capturing certain types of task-specific information.
P*- tuning is extremely parameter-efficient (often requiring less than 0.1%), as it only requires learning additional prompt tokens while keeping the original model parameters unchanged, thereby preserving the model’s generalization capabilities. However, it may not be able to capture complex task-specific information as effectively as other methods.
So far, we’ve reviewed new methods to fine-tune a large model with minimal compute power. This capability opens the door for us to combine two large models, each with billions of parameters, and fine-tune only a few million parameters to make them work together properly. This alignment allows one or both models to generate embeddings that are understandable by the other. Next, we’ll discuss three main approaches that demonstrate successful implementations of such a training regime.
2.1 Prompt adaptation:
LLaMA-Adapter presents a lightweight adaptation method to efficiently fine-tune the LLaMA model into an instruction-following model. This is achieved by freezing the pre-trained LLaMA 7B model and introducing a set of learnable adaptation prompts (1.2M parameters) into the topmost transformer layers. To avoid the initial instability and effectiveness issues caused by randomly initialized prompts, the adaptation prompts are zero-initialized. Additionally, a learnable zero-initialized gating factor is introduced to adaptively control the importance of the adaptation prompts.
Furthermore, LLaMA-Adapter extends to multi-modal tasks by integrating visual information using a pre-trained visual encoder such as CLIP. Given an image as visual context, the global visual features are acquired through multi-scale feature aggregation and then projected into the dimension of the LLM’s adaptation prompt via a learnable projection network. The resulting overall image token is repeated K times, and element-wisely added to the K-length adaptation prompts at all L inserted transformer layers. Fine-tuning with LLaMA-Adapter takes less than one hour on 8 A100 GPUs. A similar approach is used in RobustGER, where LLMs are fine-tuned to perform denoising for generative error correction (GER) in automatic speech recognition. This process takes 1.5–4.5 hours of training on a single NVIDIA A40 GPU.
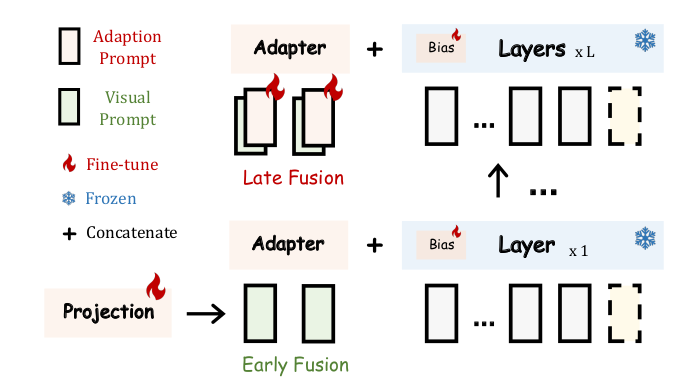
LLaMA-Adapter V2 focuses on instruction-following vision models that can also generalize well on open-ended visual instructions. To achieve this goal, three key improvements are presented over the original LLaMA-Adapter. First, it introduces more learnable parameters (14M) by unfreezing all the normalization layers in LLaMA and adding a learnable bias and scale factor to all linear layers in the transformer, which distributes the instruction-following capability across the entire model. Second, visual tokens are fed into the early layers of the language model, while the adaptation prompts are added to the top layers. This improves the integration of visual knowledge without disrupting the model’s instruction-following abilities (see Fig. 2). Third, a joint training paradigm for both image-text captioning data and language-only instruction data is employed. The visual projection layers are trained for image-text captioning data while the late adaptation prompts and the unfrozen norms are trained from the instruction-following data. Additionally, expert models like captioning and OCR systems are integrated during inference, enhancing image understanding without additional training costs. We weren’t able to find specific details on GPU requirements and the time needed for training. However, based on information from GitHub, it takes approximately 100 hours on a single A100 GPU.
2.2 Intermediate Module Training:

To create a multi-modal model, two or more unimodal foundation models can be connected through a learnable projection module. This module maps features from one modality to another, enabling the integration of different data types. For instance, a vision encoder can be connected to a large language model (LLM) via a projection module. Hence, as illustrated in Fig. 3, the LLM’s input consists of a sequence of projected image features and text. The training process typically involves two stages:
- Pretraining: The projection module is pretrained on a large dataset of paired examples to achieve cross-modality alignment.
- Fine-tuning: The projection module (with one or more unimodal models) is fine-tuned for specific downstream tasks, such as instruction-following tasks.
MiniGPT-4, aligns a frozen visual encoder, ViT-G/14, with a frozen LLM, Vicuna, using one projection layer. For visual encoder, the same pretrained visual perception component of BLIP-2 is utilized which consists of a ViT-G/14 and Q-former network. MiniGPT-4 adds a single learnable projection layer where its output is considered as a soft prompt for the LLM in the following format:
“###Human: <Img><ImageFeatureFromProjectionLayer></Img> TextTokens. ###Assistant:”.
Training the projection layer involves two stages. First, pretrain the projection layer on a large dataset of aligned image-text pairs to acquire vision-language knowledge. Then, fine-tune the linear projection layer with a smaller, high-quality dataset. In both stages, all other parameters are frozen. As a result, MiniGPT-4 is capable of producing more natural and reliable language outputs. MiniGPT-4 requires training approximately 10 hours on 4 A100 GPUs.
Tuning the LLMs to follow instructions using machine-generated instruction-following data has been shown to improve zero-shot capabilities on new tasks. To explore this idea in the multimodality field, LLaVA connects LLM Vicuna, with a vision encoder, ViT-L/14, using a single linear layer for vision-language instruction following tasks. In the first stage, the projection layer is trained on a large image-text pairs dataset while the visual encoder and LLM weights are kept frozen. This stage creates a compatible visual tokenizer for the frozen LLM. In the second stage, the pre-trained projection layer and LLM weights are fine-tuned using a high-quality generated dataset of language-image instruction-following data. This stage enhances the model’s ability to follow multimodal instructions and perform specific tasks. LLaVA uses 8× A100s GPUs. The pretraining takes 4 hours, and the fine-tuning takes 4–8 hours depending on the specific task dataset. It showcases commendable proficiency in visual reasoning capabilities, although it falls short on academic benchmarks requiring short-form answers.
To improve the performance of LLaVA, in LLaVa-1.5:
- A two-layer MLP is added to connect the LLM to the vision encoder.
- The input image resolution has been scaled up using CLIP-ViT-L-336px, allowing for better detail perception.
- The Vicuna model has been scaled up to 13B parameters.
- Academic-task-oriented VQA data has been added, along with specific response formatting prompts to indicate the desired output format. When prompting for short-form answers, the prompt “Answer the question using a single word or phrase.” is appended to the VQA question.
The training finishes in ∼1 day on a single 8-A100 GPU and achieves state-of-the-art results on a wide range of benchmarks.
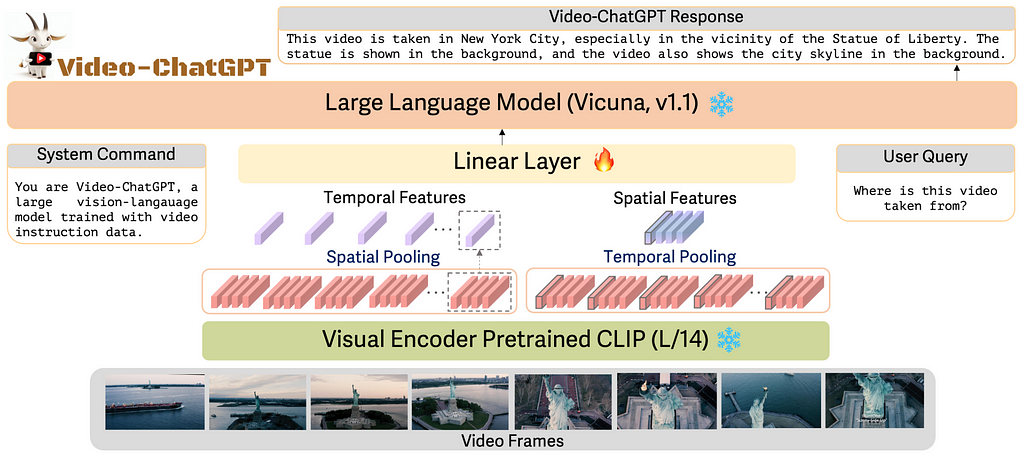
Video-ChatGPT focuses on creating a video-based conversational agent. Given the limited availability of video-caption pairs and the substantial resources required for training from scratch, it uses the pretrained image-based visual encoder, CLIP ViT-L/14 for video tasks and connect it with pretrained LLM Vicuna through a learnable linear projection model. ViT-L/14 encodes images, so for a given video sample with T frames, it generates T frame-level embeddings with dimensions h*w*D. As illustrated in Fig. 4. The process of obtaining video-level features involves two key steps:
- Spatial Video Features: These are obtained by average-pooling frame-level features across the temporal dimension to achieve an h*w*D dimension.
- Temporal Video Features: These are obtained by average-pooling across the spatial dimension to achieve T*D dimensions.
These temporal and spatial features are concatenated to form video-level features, which are then projected into the textual embedding space by a learnable linear layer. The model is trained on their curated, high-quality dataset of video-text pairs, and the training of the linear projection layer takes around 3 hours on 8 A100 40GB GPUs. This approach allows Video-ChatGPT to generate detailed and coherent conversations about video content.
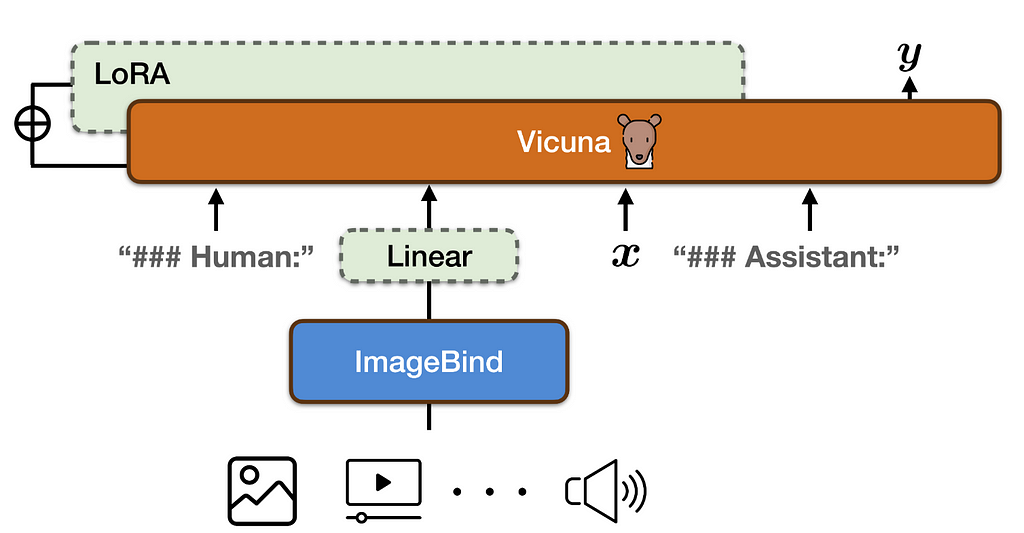
PandaGPT, while not connecting unimodal models, introduces the first general-purpose model capable of instruction-following by integrating the pretrained LLM Vicuna with the multimodal encoder ImageBind through a linear projection layer (see Fig. 5). The linear projection layer is trained, and Vicuna’s attention modules are fine-tuned using LoRA on 8×A100 40G GPUs for 7 hours, leveraging only image-language (multi-turn conversation) instruction-following data. Despite being trained exclusively on image-text pairs, PandaGPT exhibits emergent, zero-shot, cross-modal capabilities across multiple modalities by leveraging the binding property across six modalities (image/video, text, audio, depth, thermal, and IMU) inherited from the frozen ImageBind encoders. This enables PandaGPT to excel in tasks such as image/video-grounded question answering, image/video-inspired creative writing, visual and auditory reasoning, and more.
2.3 Adapter Mixture:
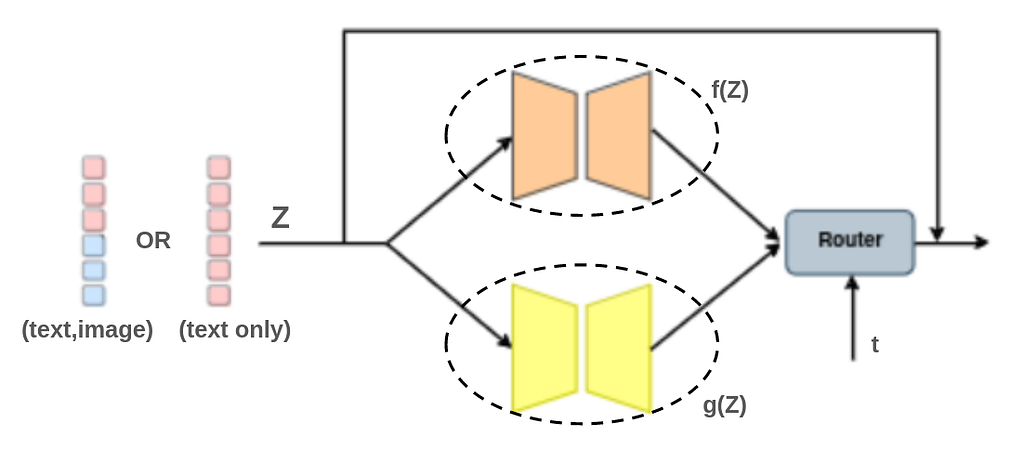
Cheap&Quick adopts lightweight adapters to integrate large language models (LLMs) and vision models for vision-language tasks. The paper proposes a Mixture-of-Modality Adapters (MMA), designed to facilitate switching between single- and multi-modal instructions without compromising performance. A learnable token t is proposed as the modality selector token. This token indicates the input features’ modality (i.e., unimodal or multimodal input) and informs the router module on how to combine the output of the learned adapters, as illustrated in Fig 6. The adapter is formulated as :
Z′=Z+s⋅router(f(Z),g(Z); t)
where Z is the input features, either unimodal or concatenated multimodal (image-text) features. Modules f and g share a common unimodal adapter architecture. s is a scaling factor, and the router(⋅) function determines the routing path based on the modality token t.
To demonstrate the effectiveness of MMA, the authors connected LLaMA and CLIP-ViT with a single linear layer and inserted MMA into both ViT and LLaMA before the multi-head attention modules. The adapters and projection layer (only 3.8M parameters) were trained with a mixture of text-only and text-image data on 8 A100 GPUs for 1.4 hours. This approach showed a significant reduction in training costs while maintaining high performance on vision-language tasks.
2.4 A Modality as Grounding Without Training
Up to this point, we have discussed papers that connect unimodal models to create a multimodal model. However, advancing toward AGI requires a multimodal model capable of handling data from different modalities for diverse tasks, ranging from calculus to generating images based on descriptions.
Recently, many papers have explored integrating pre-trained multi-modal models via language prompting into a unified model capable of handling various tasks across different modalities without additional training. In this approach, language serves as an intermediary for models to exchange information. Through prompt engineering (e.g., Visual ChatGPT, MM-REACT) or fine-tuning (e.g., Toolformer, GPT4Tools), LLMs can invoke specialized foundation models to handle various modality-specific tasks. While this topic is beyond the scope of our current blog post, you can refer to these papers for more detailed information.
In another similar work, MAGIC proposes a novel, training-free, plug-and-play framework and uses image embedding, through pre-trained CLIP, as the grounding foundation. This framework connects GPT-2 with CLIP to perform image-grounded text generation (e.g., image captioning) in a zero-shot manner. By incorporating the similarity between the image embeddings from CLIP and the top-k generated tokens from a pre-trained LLM at each time step into the decoding inference, the model effectively leverages visual information to guide text generation. Without any additional training, this approach demonstrates the capability to generate visually grounded stories given both an image and a text prompt.
3. High quality Curated data:
We have discussed various methods of aligning different modalities up to this point; however, it is important to remember that having curated, high-quality data in such training regimes is equally crucial. For instance, detailed and accurate instructions and responses significantly enhance the zero-shot performance of large language models on interactive natural language tasks. In the field of interactive vision-language tasks, the availability of high-quality data is often limited, prompting researchers to develop innovative methods for generating such data.
MiniGPT-4 proposes a two-stage method to curate a detailed, instruction-following image description dataset:
1-Data Generation: The pre-trained model from the first stage of training is used to generate detailed descriptions. For a given image, a carefully crafted prompt is used to enable the pre-trained model to produce detailed and informative image descriptions in multiple steps,
2- Post-Processing and Filtering: The generated image descriptions contain noisy or incoherent descriptions. In order to fix these issues, ChatGPT is employed to refine the generated descriptions according to specific post-processing requirements and standards, guided by a designed prompt. The refined dataset is then manually verified to ensure the correctness and quality of the image-text pairs.
LLaVA proposes a method to generate multimodal instruction-following data by querying ChatGPT/GPT-4 based on widely available image-text pair data. They designed a prompt that consists of an image caption, bounding boxes to localize objects in the scene, and a few examples for in-context learning. This method leverages the existing rich dataset and the capabilities of ChatGPT/GPT-4 to produce highly detailed and accurate multimodal data.
Video-ChatGPT utilized two approaches for generating high-quality video instruction data.
1- Human-Assisted Annotation: Expert annotators enrich given video-caption pairs by adding comprehensive details to the captions
2- Semi-Automatic Annotation: This involves a multi-step process leveraging several pretrained models:
- Pretrained BLIP-2 and GRiT models are used for analyzing key frames in the videos. BLIP-2 generates frame-level captions, while GRiT provides detailed descriptions of scene objects. Additionally, the pretrained Tag2Text model generates tags for each key frame of the video.
- A specialized filtering mechanism is employed to remove any captions from BLIP-2 or GRiT that do not match the Tag2Text frame-level tags.
- The GPT-3.5 model is used to merge the filtered captions and generate a singular, coherent video-level caption.
MIMIC-IT generated a dataset of 2.8 million multimodal instruction-response pairs, aimed at enhancing Vision-Language Models (VLMs) in perception, reasoning, and planning. To demonstrate the importance of high-quality data, they fine-tuned OpenFlamingo using the MIMIC-IT dataset on 8 A100 GPUs over 3 epochs in one day. The resulting model outperforms OpenFlamingo, demonstrating superior in-context and zero-shot learning capabilities.
The opinions expressed in this blog post are solely our own and do not reflect those of our employer.
References:
[1] LLaMA-Adapter: Zhang, Renrui, et al. “Llama-adapter: Efficient fine-tuning of language models with zero-init attention.” (2023).
[2] LLaMA-Adapter V2: Gao, Peng, et al. “Llama-adapter v2: Parameter-efficient visual instruction model.” (2023).
[3] MiniGPT-4: Zhu, Deyao, et al. “Minigpt-4: Enhancing vision-language understanding with advanced large language models.” (2023).
[4] LLaVA: Liu, Haotian, et al. “Visual instruction tuning.” (2024).
[5] LLaVa-1.5: Liu, Haotian, et al. “Improved baselines with visual instruction tuning.” (2024).
[6] Video-ChatGPT: Maaz, Muhammad, et al. “Video-chatgpt: Towards detailed video understanding via large vision and language models.” (2023).
[7] PandaGPT: Su, Yixuan, et al. “Pandagpt: One model to instruction-follow them all.” (2023).
[8] Cheap&Quick: Luo, Gen, et al. “Cheap and quick: Efficient vision-language instruction tuning for large language models.” (2024).
[9] RobustGER: Hu, Yuchen, et al. “Large Language Models are Efficient Learners of Noise-Robust Speech Recognition.” (2024).
[10] MAGIC: Su, Yixuan, et al. “Language models can see: Plugging visual controls in text generation.” (2022).
[11] Visual ChatGPT: Wu, Chenfei, et al. “Visual chatgpt: Talking, drawing and editing with visual foundation models.” (2023).
[12] MM-REACT: Yang, Zhengyuan, et al. “Mm-react: Prompting chatgpt for multimodal reasoning and action.” (2023).
[13] Toolformer: Schick, Timo, et al. “Toolformer: Language models can teach themselves to use tools.” (2024).
[14] GPT4Tools: Yang, Rui, et al. “Gpt4tools: Teaching large language model to use tools via self-instruction.” (2024).
[15] MIMIC-IT: Li, Bo, et al. “Mimic-it: Multi-modal in-context instruction tuning.” (2023).
[16] He, Junxian, et al. “Towards a unified view of parameter-efficient transfer learning.” (2021).
From Unimodals to Multimodality: DIY Techniques for Building Foundational Models was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
Originally appeared here:
From Unimodals to Multimodality: DIY Techniques for Building Foundational Models