

On multi-modal LLM Flamingo’s vision encoder
Designing Multi-modal LLM is hard.
The state-of-the-art multi-modal LLMs are primarily based on existing LLM architectures, with modifications specifically addressing different sources of input, and that’s where the difficulty comes from. The latest Nvidia paper divides the commonly used multi-modal architectures into two categories:
- decoder-based;
- cross-attention-based.
One of my previous medium articles discussed the latest paper from Meta, using decoder-based architecture, which converts an input image into a latent vector using a VAE encoder to address the issue that the image space is continuous and different from the discrete text space.
However, the problem with cross-attention-based architecture is different. For example, in the multi-modal LLM model Flamingo, the critical issue is converting the vision embedding from a generic vision model of varying temporal and spatial dimensions into the cross-attention layer to match the language input dimension.
In this post, I will dive deep into Flamingo’s unique design on top of the vision encoder, the Perceiver Resampler, to explain how this issue was solved. Furthermore, I will explore the Perceiver Resampler’s origin — the Induced Set Attention Block from Set Transformer, which further inspired DeepMind’s Perceiver model for learning fixed-length latent embeddings from generic input data.
Set Transformer
Published in 2019, the Set Transformer work extended the original Transformer model on sets to solve permutation-invariant problems like Set Anomaly Detection, Point Cloud Classification, etc. Inspired by the sparse Gaussian process where a small set of inducing variables could adequately approximate the posterior of an input, the Set Transformer uses the Induced Set Attention Blocks (ISAB) defined below:
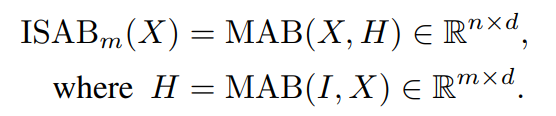
MAB(X, Y) is the transformers’ original multi-head attention block, where query = X, key/value = Y. The ISAB block is almost identical to two stacked multi-head attention blocks, except that the input key/value is replaced by the inducing matrix I. The original set X is of dimension N*D, and I is of dimension M*D, representing M 1*D inducing points. A visualization is shown below.
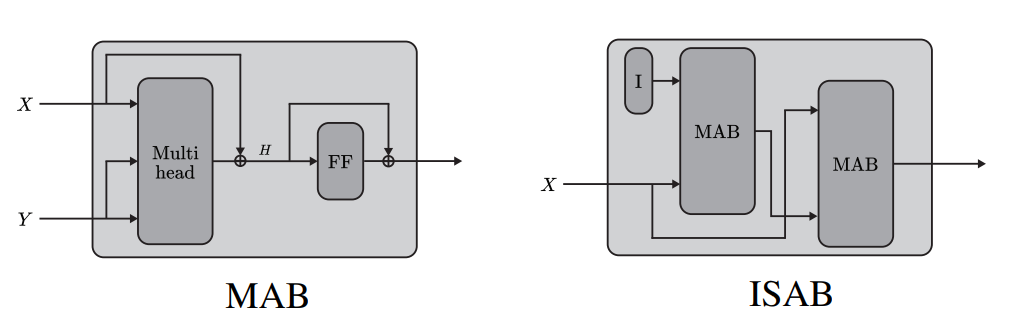
Note that the design of the ISAB is to save computational cost. The reason is that the M could be much smaller than the original N dimension, which makes the time complexity of ISAB O(N*d) much smaller than the original self-attention complexity O(N**2*d).
Perceiver
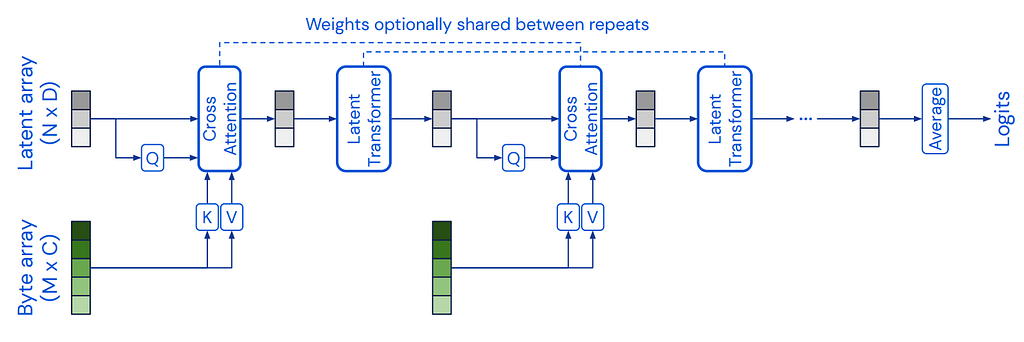
Inspired by the use of inducing points as query matrix from Set Transformer, the Perceiver model, proposed by DeepMind, separated the query matrix as a short sequence of learnable latent embeddings (e.g., N=512) while the key and value pair to be a byte array that is an ultra-long sequence input (e.g., M=224*224 pixels).
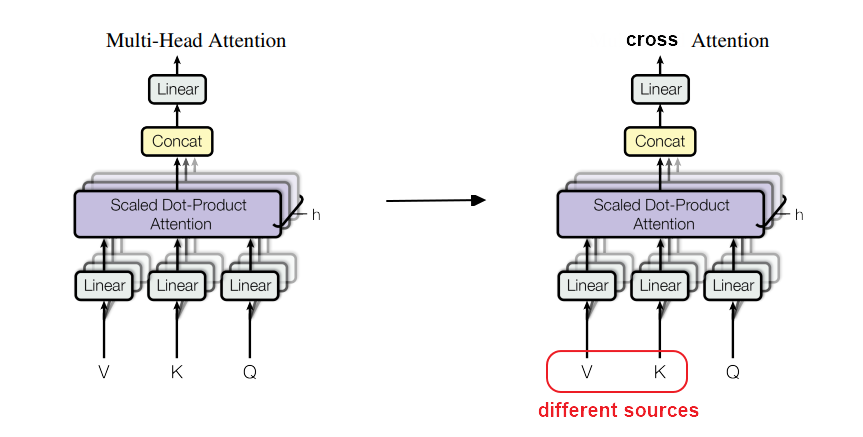
The cross attention is borrowed from the decoder part of the original transformer, where the query and key/value come from different sources, and in this case, unlearnable representations:
Since K and V are input “constants,” the Perceiver transformer layer computational complexity becomes only relative to the latent space, which is O(N**2), and is also called a latent transformer. Decoupled from the input size, the latent transformers could quickly scale up to 48 layers, which is a great advantage over traditional transformer designs.
Flamingo’s Vision Encoder and Perceiver Resampler
Instead of applying the Perceiver directly, Flamingo first uses a pre-trained, CNN-based, weight-frozen Normalizer-Free ResNet (NFNet) to extract image/video features, then adds a learnable temporal positional embedding and flattens them to the 1D sequence. The Perceiver Resampler is attached to the vision encoder to learn a fixed-size latent embedding before being passed into the cross-attention layer of the leading architecture.
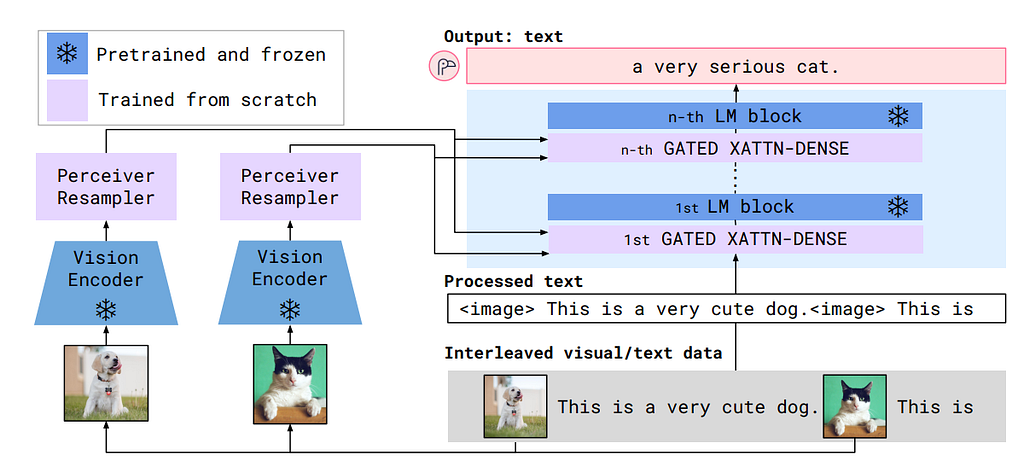
Like DeepMind’s Preceiver model, the Percerver Resampler uses constant input embeddings as keys/values and the learnable latent vectors as queries. Note that no spatial encoding is used here, and the rationale is that the previous vision encoder, NFNet, is a convolution-based model with spatial information embedded in the channel information. To increase performance, the learnable vectors are concatenated to the key/value vectors in the cross-attention computation.
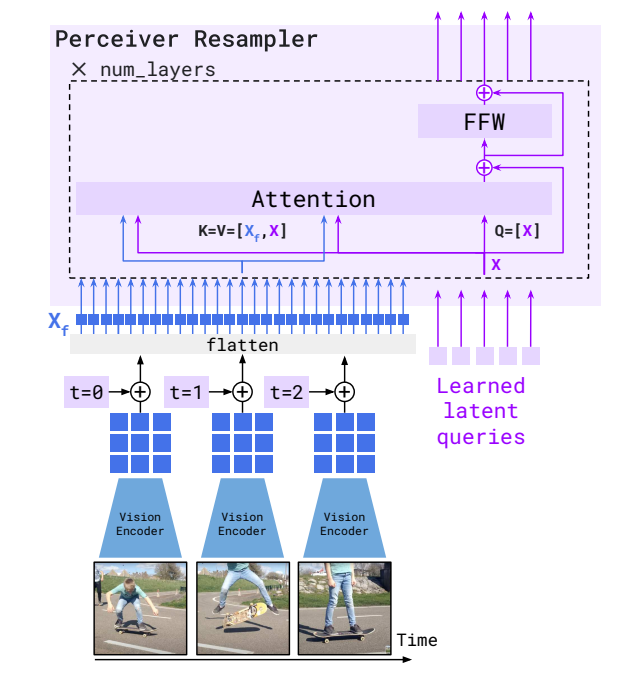
The detailed algorithm is given below:

Summary
This article gives a detailed walk-through of the vision encoder part of the Flamingo architecture. The vision encoder has a unique design, the Perceiver Resampler, which originated from the Set Transformer and the Perceiver model and could minimize the cross-attention computation cost while leveraging information from both the spatial and temporal domains.
References
- Dai et al., NVLM: Open Frontier-Class Multimodal LLMs. arXiv 2024.
- Zhou et al., Transfusion: Predict the Next Token and Diffuse Images with One Multi-Modal Model. arXiv 2024.
- Alayrac et al., Flamingo: a Visual Language Model for Few-Shot Learning. NeurIPS 2022.
- Jaegle et al., Perceiver: General Perception with Iterative Attention. ICML 2021.
- Brock at al., High-Performance Large-Scale Image Recognition Without Normalization. arXiv 2021.
- Lee et al., Set Transformer: A Framework for Attention-based Permutation-Invariant Neural Networks. ICML 2019. Slides
- Vaswani et al., Attention Is All You Need. NeurIPS 2017.
- Stanford CS25: V1 I DeepMind’s Perceiver and Perceiver IO: new data family architecture, https://www.youtube.com/watch?v=wTZ3o36lXoQ
- HuggingFace, Perceiver Model Doc. https://huggingface.co/docs/transformers/v4.34.0/en/model_doc/perceiver
From Set Transformer to Perceiver Sampler was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
Originally appeared here:
From Set Transformer to Perceiver Sampler
Go Here to Read this Fast! From Set Transformer to Perceiver Sampler