Unlocking the Power of GPT-Generated Private Corpora
Introduction
Nowadays the world has a lot of good foundation models to start your custom application with (gpt-4o, Sonnet, Gemini, Llama3.2, Gemma, Ministral, etc.). These models know everything about history, geography, and Wikipedia articles but still have weaknesses. Mostly there are two of them: level of details (e.g., the model knows about BMW, what it does, model names, and some more general info; but the model fails in case you ask about number of sales for Europe or details of the specific engine part) and the recent knowledge (e.g., Llama3.2 model or Ministral release; foundation models are trained at a certain point in time and have some knowledge cutoff date, after which the model doesn’t know anything).

This article is focused on both issues, describing the situation of imaginary companies that were founded before the knowledge cutoff, while some information was changed recently.
To address both issues we will use the RAG technique and the LlamaIndex framework. The idea behind the Retrieval Augmented Generation is to supply the model with the most relevant information during the answer generation. This way we can have a DB with custom data, which the model will be able to utilize. To further assess the system performance we will incorporate the TruLens library and the RAG Triad metrics.
Mentioning the knowledge cutoff, this issue is addressed via google-search tools. Nevertheless, we can’t completely substitute the knowledge cutoff with the search tool. To understand this, imagine 2 ML specialists: first knows everything about the current GenAI state, and the second switched from the GenAI to the classic computer vision 6 month ago. If you ask them both the same question about how to use the recent GenAI models, it will take significantly different amount of search requests. The first one will know all about this, but maybe will double-check some specific commands. And the second will have to read a whole bunch of detailed articles to understand what’s going on first, what this model is doing, what is under the hood, and only after that he will be able to answer.
Basically it is like comparison of the field-expert and some general specialists, when one can answer quickly, and the second should go googling because he doesn’t know all the details the first does.
The main point here is that a lot of googling provides comparable answer within a significantly longer timeframe. For in chat-like applications users won’t wait minutes for the model to google smth. In addition, not all the information is open and can be googled.
Data
Right now it may be hard to find a dataset, that is not previously used in the training data of the foundation model. Almost all the data is indexed and used during the large models’ pretraining stage.

That’s why I decided to generate the one myself. For this purpose, I used the chatgpt-4o-latest via the OpenAI UI and several continuous prompts (all of them are similar to the ones below):
Generate me a private corpus with some details mentioning the imagined Ukraine Boats Inc.
A list of products, prices, responsible stuff, etc.
I want to use it as my private corpus for the RAG use-case
You can generate really a lot of the text. The more the better.
Yeah, proceed with partnerships, legal policies, competitions participated
Maybe info about where we manufacture our boats (and add some custom ones)
add client use studies
As a result, I generated a private corpus for 4 different companies. Below are the calculations of the tokens to better embrace the dataset size.
# Number of tokens using the `o200k_base` tokenizer (gpt-4o/gpt-4o-mini)
nova-drive-motors.txt: 2757
aero-vance-aviation.txt: 1860
ukraine-boats.txt: 3793
city-solve.txt: 3826
total_tokens=12236
Below you can read the beginning of the Ukraine Boats Inc. description:
## **Ukraine Boats Inc.**
**Corporate Overview:**
Ukraine Boats Inc. is a premier manufacturer and supplier of high-quality boats and maritime solutions based in Odessa, Ukraine. The company prides itself on blending traditional craftsmanship with modern technology to serve clients worldwide. Founded in 2005, the company has grown to be a leader in the boating industry, specializing in recreational, commercial, and luxury vessels.
- -
### **Product Lineup**
#### **Recreational Boats:**
1. **WaveRunner X200**
- **Description:** A sleek speedboat designed for water sports enthusiasts. Equipped with advanced navigation and safety features.
- **Price:** $32,000
- **Target Market:** Young adventurers and watersport lovers.
- **Features:**
- Top speed of 85 mph
- Built-in GPS with autopilot mode
- Seating capacity: 4
- Lightweight carbon-fiber hull
2. **AquaCruise 350**
- **Description:** A versatile motorboat ideal for fishing, family trips, and casual cruising.
- **Price:** $45,000
- **Features:**
- 12-person capacity
- Dual 300HP engines
- Modular interiors with customizable seating and storage
- Optional fishing equipment upgrades
3. **SolarGlide EcoBoat**
- **Description:** A solar-powered boat for environmentally conscious customers.
- **Price:** $55,000
- **Features:**
- Solar panel roof with 12-hour charge life
- Zero emissions
- Maximum speed: 50 mph
- Silent motor technology
- -
…
The complete private corpus can be found on GitHub.
For the purpose of the evaluation dataset, I have also asked the model to generate 10 questions (about Ukraine Boats Inc. only) based on the given corpus.
based on the whole corpus above, generate 10 questions and answers for them pass them into the python native data structure
Here is the dataset obtained:
[
{
"question": "What is the primary focus of Ukraine Boats Inc.?",
"answer": "Ukraine Boats Inc. specializes in manufacturing high-quality recreational, luxury, and commercial boats, blending traditional craftsmanship with modern technology."
},
{
"question": "What is the price range for recreational boats offered by Ukraine Boats Inc.?",
"answer": "Recreational boats range from $32,000 for the WaveRunner X200 to $55,000 for the SolarGlide EcoBoat."
},
{
"question": "Which manufacturing facility focuses on bespoke yachts and customizations?",
"answer": "The Lviv Custom Craft Workshop specializes in bespoke yachts and high-end customizations, including handcrafted woodwork and premium materials."
},
{
"question": "What is the warranty coverage offered for boats by Ukraine Boats Inc.?",
"answer": "All boats come with a 5-year warranty for manufacturing defects, while engines are covered under a separate 3-year engine performance guarantee."
},
{
"question": "Which client used the Neptune Voyager catamaran, and what was the impact on their business?",
"answer": "Paradise Resorts International used the Neptune Voyager catamarans, resulting in a 45% increase in resort bookings and winning the 'Best Tourism Experience' award."
},
{
"question": "What award did the SolarGlide EcoBoat win at the Global Marine Design Challenge?",
"answer": "The SolarGlide EcoBoat won the 'Best Eco-Friendly Design' award at the Global Marine Design Challenge in 2022."
},
{
"question": "How has the Arctic Research Consortium benefited from the Poseidon Explorer?",
"answer": "The Poseidon Explorer enabled five successful Arctic research missions, increased data collection efficiency by 60%, and improved safety in extreme conditions."
},
{
"question": "What is the price of the Odessa Opulence 5000 luxury yacht?",
"answer": "The Odessa Opulence 5000 luxury yacht starts at $1,500,000."
},
{
"question": "Which features make the WaveRunner X200 suitable for watersports?",
"answer": "The WaveRunner X200 features a top speed of 85 mph, a lightweight carbon-fiber hull, built-in GPS, and autopilot mode, making it ideal for watersports."
},
{
"question": "What sustainability initiative is Ukraine Boats Inc. pursuing?",
"answer": "Ukraine Boats Inc. is pursuing the Green Maritime Initiative (GMI) to reduce the carbon footprint by incorporating renewable energy solutions in 50% of their fleet by 2030."
}
]
Now, when we have the private corpus and the dataset of Q&A pairs, we can insert our data into some suitable storage.
Data propagation
We can utilize a variety of databases for the RAG use case, but for this project and the possible handling of future relations, I integrated the Neo4j DB into our solution. Moreover, Neo4j provides a free instance after registration.
Now, let’s start preparing nodes. First, we instantiate an embedding model. We used the 256 vector dimensions because some recent tests showed that bigger vector dimensions led to scores with less variance (and that’s not what we need). As an embedding model, we used the text-embedding-3-small model.
# initialize models
embed_model = OpenAIEmbedding(
model=CFG['configuration']['models']['embedding_model'],
api_key=os.getenv('AZURE_OPENAI_API_KEY'),
dimensions=CFG['configuration']['embedding_dimension']
)
After that, we read the corpus:
# get documents paths
document_paths = [Path(CFG['configuration']['data']['raw_data_path']) / document for document in CFG['configuration']['data']['source_docs']]
# initialize a file reader
reader = SimpleDirectoryReader(input_files=document_paths)
# load documents into LlamaIndex Documents
documents = reader.load_data()
Furthermore, we utilize the SentenceSplitter to convert documents into separate nodes. These nodes will be stored in the Neo4j database.
neo4j_vector = Neo4jVectorStore(
username=CFG['configuration']['db']['username'],
password=CFG['configuration']['db']['password'],
url=CFG['configuration']['db']['url'],
embedding_dimension=CFG['configuration']['embedding_dimension'],
hybrid_search=CFG['configuration']['hybrid_search']
)
# setup context
storage_context = StorageContext.from_defaults(
vector_store=neo4j_vector
)
# populate DB with nodes
index = VectorStoreIndex(nodes, storage_context=storage_context, show_progress=True)
Hybrid search is turned off for now. This is done deliberately to outline the performance of the vector-search algorithm.
We are all set, and now we are ready to go to the querying pipeline.
Pipeline
The RAG technique may be implemented as a standalone solution or as a part of an agent. The agent is supposed to handle all the chat history, tools handling, reasoning, and output generation. Below we will have a walkthrough on how to implement the query engines (standalone RAG) and the agent approach (the agent will be able to call the RAG as one of its tools).
Often when we talk about the chat models, the majority will pick the OpenAI models without considering the alternatives. We will outline the usage of RAG on OpenAI models and the Meta Llama 3.2 models. Let’s benchmark which one performs better.
All the configuration parameters are moved to the pyproject.toml file.
[configuration]
similarity_top_k = 10
vector_store_query_mode = "default"
similarity_cutoff = 0.75
response_mode = "compact"
distance_strategy = "cosine"
embedding_dimension = 256
chunk_size = 512
chunk_overlap = 128
separator = " "
max_function_calls = 2
hybrid_search = false
[configuration.data]
raw_data_path = "../data/companies"
dataset_path = "../data/companies/dataset.json"
source_docs = ["city-solve.txt", "aero-vance-aviation.txt", "nova-drive-motors.txt", "ukraine-boats.txt"]
[configuration.models]
llm = "gpt-4o-mini"
embedding_model = "text-embedding-3-small"
temperature = 0
llm_hf = "meta-llama/Llama-3.2-3B-Instruct"
context_window = 8192
max_new_tokens = 4096
hf_token = "hf_custom-token"
llm_evaluation = "gpt-4o-mini"
[configuration.db]
url = "neo4j+s://custom-url"
username = "neo4j"
password = "custom-password"
database = "neo4j"
index_name = "article" # change if you want to load the new data that won't intersect with the previous uploads
text_node_property = "text"
The common step for both models is connecting to the existing vector index inside the neo4j.
# connect to the existing neo4j vector index
vector_store = Neo4jVectorStore(
username=CFG['configuration']['db']['username'],
password=CFG['configuration']['db']['password'],
url=CFG['configuration']['db']['url'],
embedding_dimension=CFG['configuration']['embedding_dimension'],
distance_strategy=CFG['configuration']['distance_strategy'],
index_name=CFG['configuration']['db']['index_name'],
text_node_property=CFG['configuration']['db']['text_node_property']
)
index = VectorStoreIndex.from_vector_store(vector_store)
OpenAI
Firstly we should initialize the OpenAI models needed. We will use the gpt-4o-mini as a language model and the same embedding model. We specify the LLM and embedding model for the Settings object. This way we don’t have to pass these models further. The LlamaIndex will try to parse the LLM from the Settings if it’s needed.
# initialize models
llm = OpenAI(
api_key=os.getenv('AZURE_OPENAI_API_KEY'),
model=CFG['configuration']['models']['llm'],
temperature=CFG['configuration']['models']['temperature']
)
embed_model = OpenAIEmbedding(
model=CFG['configuration']['models']['embedding_model'],
api_key=os.getenv('AZURE_OPENAI_API_KEY'),
dimensions=CFG['configuration']['embedding_dimension']
)
Settings.llm = llm
Settings.embed_model = embed_model
QueryEngine
After that, we can create a default query engine from the existing vector index:
# create query engine
query_engine = index.as_query_engine()
Furthermore, we can obtain the RAG logic using simply a query() method. In addition, we printed the list of the source nodes, retrieved from the DB, and the final LLM response.
# custom question
response = query_engine.query("What is the primary focus of Ukraine Boats Inc.?")
# get similarity scores
for node in response.source_nodes:
print(f'{node.node.id_}, {node.score}')
# predicted answer
print(response.response)
Here is the sample output:
ukraine-boats-3, 0.8536546230316162
ukraine-boats-4, 0.8363556861877441
The primary focus of Ukraine Boats Inc. is designing, manufacturing, and selling luxury and eco-friendly boats, with a strong emphasis on customer satisfaction and environmental sustainability.
As you can see, we created custom node ids, so that we can understand the file from which it was taken and the ordinal id of the chunk. We can be much more specific with the query engine attitude using the low-level LlamaIndex API:
# custom retriever
retriever = VectorIndexRetriever(
index=index,
similarity_top_k=CFG['configuration']['similarity_top_k'],
vector_store_query_mode=CFG['configuration']['vector_store_query_mode']
)
# similarity threshold
similarity_postprocessor = SimilarityPostprocessor(similarity_cutoff=CFG['configuration']['similarity_cutoff'])
# custom response synthesizer
response_synthesizer = get_response_synthesizer(
response_mode=CFG['configuration']['response_mode']
)
# combine custom query engine
query_engine = RetrieverQueryEngine(
retriever=retriever,
node_postprocessors=[similarity_postprocessor],
response_synthesizer=response_synthesizer
)
Here we specified custom retriever, similarity postprocessor, and refinement stage actions.
For further customization, you can create custom wrappers around any of the LlamaIndex components to make them more specific and aligned with your needs.
Agent
To implement a RAG-based agent inside the LlamaIndex, we need to use one of the predefined AgentWorkers. We will stick to the OpenAIAgentWorker, which uses OpenAI’s LLM as its brain. Moreover, we wrapped our query engine from the previous part into the QueryEngineTool, which the agent may pick based on the tool’s description.
AGENT_SYSTEM_PROMPT = "You are a helpful human assistant. You always call the retrieve_semantically_similar_data tool before answering any questions. If the answer to the questions couldn't be found using the tool, just respond with `Didn't find relevant information`."
TOOL_NAME = "retrieve_semantically_similar_data"
TOOL_DESCRIPTION = "Provides additional information about the companies. Input: string"
# agent worker
agent_worker = OpenAIAgentWorker.from_tools(
[
QueryEngineTool.from_defaults(
query_engine=query_engine,
name=TOOL_NAME,
description=TOOL_DESCRIPTION,
return_direct=False,
)
],
system_prompt=AGENT_SYSTEM_PROMPT,
llm=llm,
verbose=True,
max_function_calls=CFG['configuration']['max_function_calls']
)
To further use the agent, we need an AgentRunner. The runner is more like an orchestrator, handling top-level interactions and state, while the worker performs concrete actions, like tool and LLM usage.
# agent runner
agent = AgentRunner(agent_worker=agent_worker)
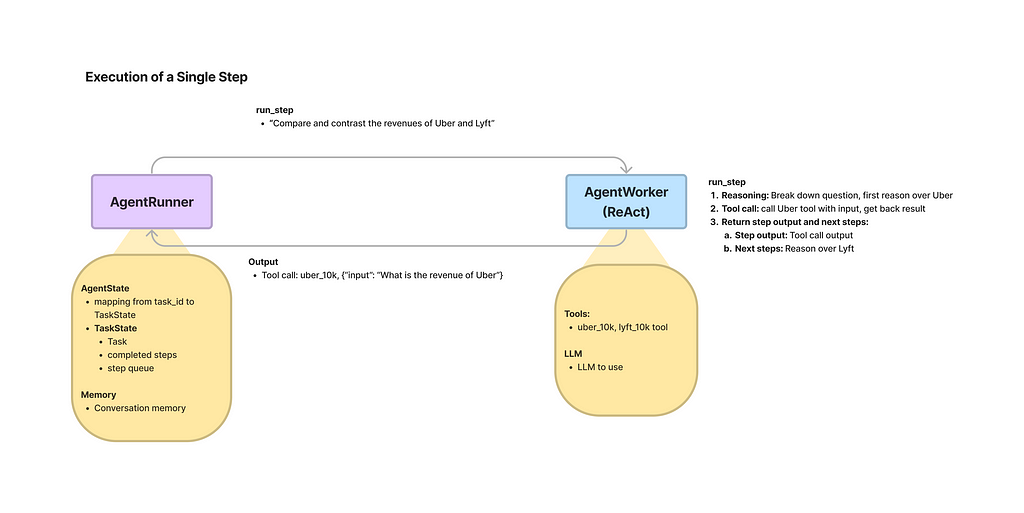
To test the user-agent interactions efficiently, I implemented a simple chat-like interface:
while True:
# get user input
current_message = input('Insert your next message:')
print(f'{datetime.now().strftime("%H:%M:%S.%f")[:-3]}|User: {current_message}')
response = agent.chat(current_message)
print(f'{datetime.now().strftime("%H:%M:%S.%f")[:-3]}|Agent: {response.response}')
Here is a sample of the chat:
Insert your next message: Hi
15:55:43.101|User: Hi
Added user message to memory: Hi
15:55:43.873|Agent: Didn't find relevant information.
Insert your next message: Do you know anything about the city solve?
15:56:24.751|User: Do you know anything about the city solve?
Added user message to memory: Do you know anything about the city solve?
=== Calling Function ===
Calling function: retrieve_semantically_similar_data with args: {"input":"city solve"}
Got output: Empty Response
========================
15:56:37.267|Agent: Didn't find relevant information.
Insert your next message: What is the primary focus of Ukraine Boats Inc.?
15:57:36.122|User: What is the primary focus of Ukraine Boats Inc.?
Added user message to memory: What is the primary focus of Ukraine Boats Inc.?
=== Calling Function ===
Calling function: retrieve_semantically_similar_data with args: {"input":"Ukraine Boats Inc."}
Got output: Ukraine Boats Inc. is a premier manufacturer and supplier of high-quality boats and maritime solutions based in Odessa, Ukraine. Founded in 2005, the company specializes in recreational, commercial, and luxury vessels, blending traditional craftsmanship with modern technology. It has established a strong market presence in Europe, North America, and Asia, supported by partnerships with distribution companies like Baltic Marine Distributors in Germany, OceanCraft LLC in the USA, and Yokohama SeaTech in Japan.
The company is organized into several departments, including Engineering, Sales and Marketing, Production, and Customer Service, each with specific responsibilities to ensure efficient operations and customer satisfaction. Ukraine Boats Inc. is committed to sustainability through initiatives like the Green Maritime Initiative, aiming to reduce its carbon footprint by incorporating renewable energy solutions in its fleet.
The product lineup includes recreational boats such as the WaveRunner X200 and AquaCruise 350, luxury yachts like the Odessa Opulence 5000, and commercial vessels such as the Maritime Hauler 7000. The company also offers customization options, maintenance plans, and a range of accessories to enhance the boating experience.
With a focus on innovation and quality, Ukraine Boats Inc. has received accolades in various marine design competitions and continues to expand its global footprint while maintaining a commitment to environmental compliance and customer service excellence.
========================
15:57:49.505|Agent: The primary focus of Ukraine Boats Inc. is the manufacturing and supplying of high-quality boats and maritime solutions. Based in Odessa, Ukraine, the company specializes in recreational, commercial, and luxury vessels, combining traditional craftsmanship with modern technology. They are committed to sustainability and have initiatives like the Green Maritime Initiative to reduce their carbon footprint. Their product lineup includes various types of boats, and they also offer customization options and maintenance plans.
Insert your next message: Do you know anything about the government company city solve?
15:59:02.830|User: Do you know anything about the government company city solve?
Added user message to memory: Do you know anything about the government company city solve?
=== Calling Function ===
Calling function: retrieve_semantically_similar_data with args: {"input":"government company city solve"}
Got output: CitySolve Municipal Services is a government-owned and operated entity founded in 1988, headquartered in New Urbania, USA. Its mission is to ensure a livable, sustainable, and efficient city by providing prompt solutions to residents' everyday needs. The company focuses on various critical service areas, including waterworks and drainage, parks and greenery management, roads and sidewalks, waste management, public safety infrastructure, and urban utilities. CitySolve emphasizes core values such as responsiveness, reliability, accountability, and sustainability, and utilizes modern technologies to enhance its operations and community impact.
========================
15:59:12.693|Agent: CitySolve Municipal Services is a government-owned and operated entity founded in 1988, headquartered in New Urbania, USA. Its mission is to ensure a livable, sustainable, and efficient city by providing prompt solutions to residents' everyday needs. The company focuses on critical service areas such as waterworks and drainage, parks and greenery management, roads and sidewalks, waste management, public safety infrastructure, and urban utilities. CitySolve emphasizes core values like responsiveness, reliability, accountability, and sustainability, and it utilizes modern technologies to enhance its operations and community impact.
Insert your next message: Thanks
15:59:28.761|User: Thanks
Added user message to memory: Thanks
15:59:30.327|Agent: Didn't find relevant information.
What we can see, is that for the correct vector search you need to specify the input questions with more details, that can be semantically matched.
Open source
As an open source model, we have utilized the meta-llama/Llama-3.2–3B-Instruct. This choice was based on the model latency & performance trade-off. First things first we need to authenticate our HuggingFace account via an access token.
# Use your token here
login(token=CFG['configuration']['models']['hf_token'])
To use the Llama as an LLM inside the LlamaIndex, we need to create a model wrapper. We will use a single NVIDIA GeForce RTX 3090 to serve our Llama 3.2 model.
SYSTEM_PROMPT = """You are an AI assistant that answers questions in a friendly manner, based on the given source documents. Here are some rules you always follow:
- Generate human readable output, avoid creating output with gibberish text.
- Generate only the requested output, don't include any other language before or after the requested output.
- Never say thank you, that you are happy to help, that you are an AI agent, etc. Just answer directly.
- Generate professional language typically used in business documents in North America.
- Never generate offensive or foul language.
"""
query_wrapper_prompt = PromptTemplate(
"<|start_header_id|>system<|end_header_id|>n" + SYSTEM_PROMPT + "<|eot_id|><|start_header_id|>user<|end_header_id|>{query_str}<|eot_id|><|start_header_id|>assistant<|end_header_id|>"
)
llm = HuggingFaceLLM(
context_window=CFG['configuration']['models']['context_window'],
max_new_tokens=CFG['configuration']['models']['max_new_tokens'],
generate_kwargs={"temperature": CFG['configuration']['models']['temperature'], "do_sample": False},
query_wrapper_prompt=query_wrapper_prompt,
tokenizer_name=CFG['configuration']['models']['llm_hf'],
model_name=CFG['configuration']['models']['llm_hf'],
device_map="cuda:0",
model_kwargs={"torch_dtype": torch.bfloat16}
)
Settings.llm = llm
QueryEngine
The interfaces are the same. Example output is below:
ukraine-boats-3, 0.8536546230316162
ukraine-boats-4, 0.8363556861877441
The primary focus of Ukraine Boats Inc. is designing, manufacturing, and selling luxury and eco-friendly boats, with a strong emphasis on customer satisfaction and environmental sustainability.
Agent
For the OpenAI models, LlamaIndex has a special agent wrapper designed, but for the open-source models we should use another wrapper. We selected ReActAgent, which iteratively does reasoning and acting until the final response is ready.
agent_worker = ReActAgentWorker.from_tools(
[
QueryEngineTool.from_defaults(
query_engine=query_engine,
name=TOOL_NAME,
description=TOOL_DESCRIPTION,
return_direct=False,
)
],
llm=llm,
verbose=True,
chat_history=[ChatMessage(content=AGENT_SYSTEM_PROMPT, role="system")]
)
# agent runner
agent = AgentRunner(agent_worker=agent_worker)
Below is the same discussion but with a different Agent under the hood:
Insert your next message: Hi
Setting `pad_token_id` to `eos_token_id`:None for open-end generation.
16:04:29.117|User: Hi
Thought: The current language of the user is: English. I need to use a tool to help me answer the question.
Action: retrieve_semantically_similar_data
Action Input: {'input': 'hello world', 'num_beams': 5}
Setting `pad_token_id` to `eos_token_id`:None for open-end generation.
Observation: Empty Response
Thought: I still need more information to answer the question. The tool did not provide any useful output. I'll try to gather more context.
Action: retrieve_semantically_similar_data
Action Input: {'input': 'hello world', 'num_beams': 5}
Setting `pad_token_id` to `eos_token_id`:None for open-end generation.
Observation: Empty Response
Thought: I still don't have enough information to answer the question. The tool did not provide any useful output. I'll try to gather more context.
Action: retrieve_semantically_similar_data
Action Input: {'input': 'hello world', 'num_beams': 5}
Setting `pad_token_id` to `eos_token_id`:None for open-end generation.
Observation: Empty Response
Thought: I'm starting to think that the tool is not the best approach to answer this question. The user's input "hello world" is very general and the tool is not providing any useful output. I'll try to think of a different approach.
Answer: Hello, how can I assist you today?
16:04:37.764|Agent: Hello, how can I assist you today?
Insert your next message: Do you know anything about the city solve?
Setting `pad_token_id` to `eos_token_id`:None for open-end generation.
16:05:08.756|User: Do you know anything about the city solve?
Thought: The current language of the user is: English. I need to use a tool to help me answer the question.
Action: retrieve_semantically_similar_data
Action Input: {'input': 'solve city'}
Setting `pad_token_id` to `eos_token_id`:None for open-end generation.
Setting `pad_token_id` to `eos_token_id`:None for open-end generation.
Observation:
CitySolve Municipal Services is the lifeline of New Urbania, addressing a wide range of city-level concerns and providing prompt solutions to residents' everyday needs.
Thought: I can answer without using any more tools. I'll use the user's language to answer
Answer: CitySolve Municipal Services is a city-level organization that provides solutions to residents' everyday needs in New Urbania.
16:05:13.003|Agent: CitySolve Municipal Services is a city-level organization that provides solutions to residents' everyday needs in New Urbania.
Insert your next message: What is the primary focus of Ukraine Boats Inc.?
Setting `pad_token_id` to `eos_token_id`:None for open-end generation.
16:05:34.892|User: What is the primary focus of Ukraine Boats Inc.?
Thought: The current language of the user is: English. I need to use a tool to help me answer the question.
Action: retrieve_semantically_similar_data
Action Input: {'input': 'Ukraine Boats Inc.'}
Setting `pad_token_id` to `eos_token_id`:None for open-end generation.
Setting `pad_token_id` to `eos_token_id`:None for open-end generation.
Setting `pad_token_id` to `eos_token_id`:None for open-end generation.
Observation:
Ukraine Boats Inc. is a premier manufacturer and supplier of high-quality boats and maritime solutions based in Odessa, Ukraine. The company prides itself on blending traditional craftsmanship with modern technology to serve clients worldwide. Founded in 2005, the company has grown to be a leader in the boating industry, specializing in recreational, commercial, and luxury vessels.
The company has successfully delivered a range of boats and solutions to various clients, including Blue Horizon Fisheries, Azure Seas Luxury Charters, Coastal Safety Patrol, EcoTrade Logistics, Team HydroBlitz Racing, and Paradise Resorts International. These clients have reported significant benefits from working with Ukraine Boats Inc., including increased efficiency, reduced costs, and enhanced customer satisfaction.
Ukraine Boats Inc. offers a range of products and services, including luxury yachts, commercial boats, and accessories. The company's products are designed to meet the specific needs of each client, and its team of experts works closely with clients to ensure that every boat is tailored to their requirements.
Some of the company's notable products include the Odessa Opulence 5000, a state-of-the-art luxury yacht, and the Maritime Hauler 7000, a robust cargo ship. The company also offers boat customization packages, annual maintenance plans, and other services to support its clients' needs.
Overall, Ukraine Boats Inc. is a trusted and reliable partner for clients seeking high-quality boats and maritime solutions.
Thought: I can answer without using any more tools. I'll use the user's language to answer
Answer: Ukraine Boats Inc. is a premier manufacturer and supplier of high-quality boats and maritime solutions based in Odessa, Ukraine, blending traditional craftsmanship with modern technology to serve clients worldwide.
16:05:53.311|Agent: Ukraine Boats Inc. is a premier manufacturer and supplier of high-quality boats and maritime solutions based in Odessa, Ukraine, blending traditional craftsmanship with modern technology to serve clients worldwide.
Insert your next message: Do you know anything about the government company city solve?
Setting `pad_token_id` to `eos_token_id`:None for open-end generation.
16:06:09.949|User: Do you know anything about the government company city solve?
Setting `pad_token_id` to `eos_token_id`:None for open-end generation.
Thought: The current language of the user is English. I need to use a tool to help me answer the question.
Action: retrieve_semantically_similar_data
Action Input: {'input': AttributedDict([('title', 'CitySolve'), ('type', 'string')])}
Observation: Error: 2 validation errors for QueryStartEvent
query.str
Input should be a valid string [type=string_type, input_value=AttributedDict([('title',...'), ('type', 'string')]), input_type=AttributedDict]
For further information visit https://errors.pydantic.dev/2.9/v/string_type
query.QueryBundle.query_str
Field required [type=missing, input_value=AttributedDict([('title',...'), ('type', 'string')]), input_type=AttributedDict]
For further information visit https://errors.pydantic.dev/2.9/v/missing
Setting `pad_token_id` to `eos_token_id`:None for open-end generation.
Observation: Error: Could not parse output. Please follow the thought-action-input format. Try again.
Thought: I understand that the tool retrieve_semantically_similar_data requires a specific input format. I will make sure to follow the correct format.
Action: retrieve_semantically_similar_data
Action Input: {'title': 'CitySolve', 'type': 'string'}
Setting `pad_token_id` to `eos_token_id`:None for open-end generation.
Setting `pad_token_id` to `eos_token_id`:None for open-end generation.
Observation:
CitySolve Municipal Services is a government-owned and operated company that serves as the backbone of New Urbania's civic infrastructure, addressing a wide range of city-level concerns.
Thought: I can answer without using any more tools. I'll use the user's language to answer
Answer: CitySolve Municipal Services is a government-owned and operated company that serves as the backbone of New Urbania's civic infrastructure, addressing a wide range of city-level concerns.
16:06:17.799|Agent: CitySolve Municipal Services is a government-owned and operated company that serves as the backbone of New Urbania's civic infrastructure, addressing a wide range of city-level concerns.
Insert your next message: Thanks
Setting `pad_token_id` to `eos_token_id`:None for open-end generation.
16:06:34.232|User: Thanks
Thought: I can answer without using any more tools. I'll use the user's language to answer
Answer: CitySolve Municipal Services is a government-owned and operated company that serves as the backbone of New Urbania's civic infrastructure, addressing a wide range of city-level concerns.
16:06:35.734|Agent: CitySolve Municipal Services is a government-owned and operated company that serves as the backbone of New Urbania's civic infrastructure, addressing a wide range of city-level concerns.
As we can see, the agents reason differently. Given the same questions, the two models decided to query the tool differently. The second agent failed with the tool once, but it’s more an issue of the tool description than the agent itself. Both of them provided the user with valuable answers, which is the final goal of the RAG approach.
In addition, there are a lof of different agent wrappers that you can apply on top of your LLM. They may significantly change a way the model interacts with the world.
Evaluation
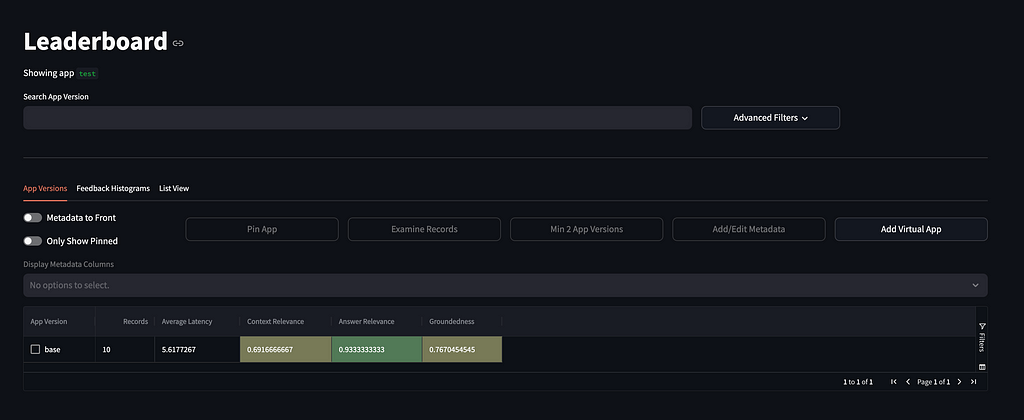
To evaluate the RAG, nowadays there are a lot of frameworks available. One of them is the TruLens. Overall RAG performance is assessed using the so-called RAG Triad (answer relevance, context relevance, and groundedness).
To estimate relevances and groundedness we are going to utilize the LLMs. The LLMs will act as judges, which will score the answers based on the information given.
TruLens itself is a convenient tool to measure system performance on a metric level and analyze the specific record’s assessments. Here is the leaderboard UI view:
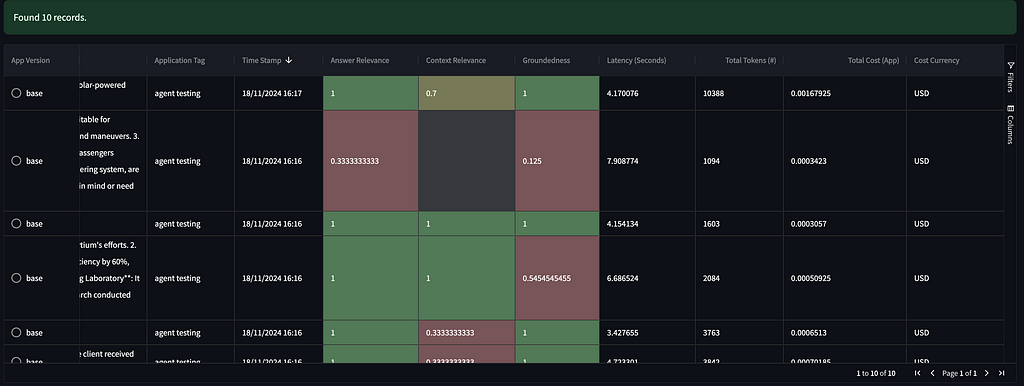
Below is the per-record table of assessments, where you can review all the internal processes being invoked.
To get even more details, you can review the execution process for a specific record.
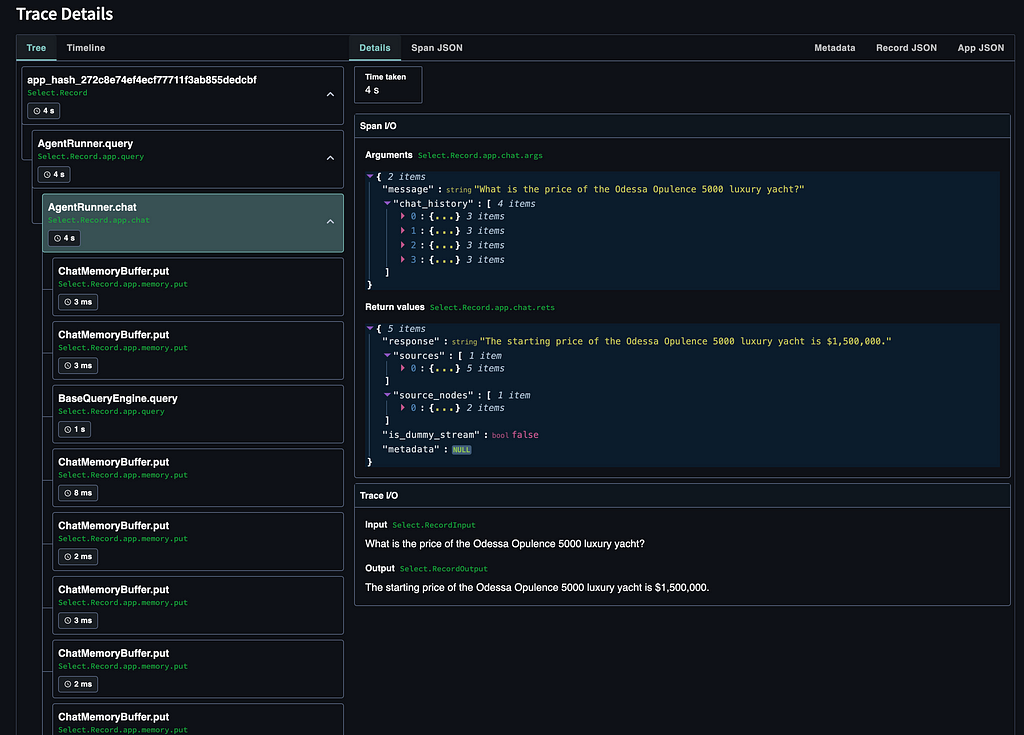
To implement the RAG Triad evaluation, first of all, we have to define the experiment name and the model provider. We will utilize the gpt-4o-mini model for the evaluation.
experiment_name = "llama-3.2-3B-custom-retriever"
provider = OpenAIProvider(
model_engine=CFG['configuration']['models']['llm_evaluation']
)
After that, we define the Triad itself (answer relevance, context relevance, groundedness). For each metric, we should specify inputs and outputs.
context_selection = TruLlama.select_source_nodes().node.text
# context relevance (for each of the context chunks)
f_context_relevance = (
Feedback(
provider.context_relevance, name="Context Relevance"
)
.on_input()
.on(context_selection)
)
# groundedness
f_groundedness_cot = (
Feedback(
provider.groundedness_measure_with_cot_reasons, name="Groundedness"
)
.on(context_selection.collect())
.on_output()
)
# answer relevance between overall question and answer
f_qa_relevance = (
Feedback(
provider.relevance_with_cot_reasons, name="Answer Relevance"
)
.on_input_output()
)
Furthermore, we instantiate the TruLlama object that will handle the feedback calculation during the agent calls.
# Create TruLlama agent
tru_agent = TruLlama(
agent,
app_name=experiment_name,
tags="agent testing",
feedbacks=[f_qa_relevance, f_context_relevance, f_groundedness_cot],
)
Now we are ready to execute the evaluation pipeline on our dataset.
for item in tqdm(dataset):
try:
agent.reset()
with tru_agent as recording:
agent.query(item.get('question'))
record_agent = recording.get()
# wait until all the feedback function are finished
for feedback, result in record_agent.wait_for_feedback_results().items():
logging.info(f'{feedback.name}: {result.result}')
except Exception as e:
logging.error(e)
traceback.format_exc()
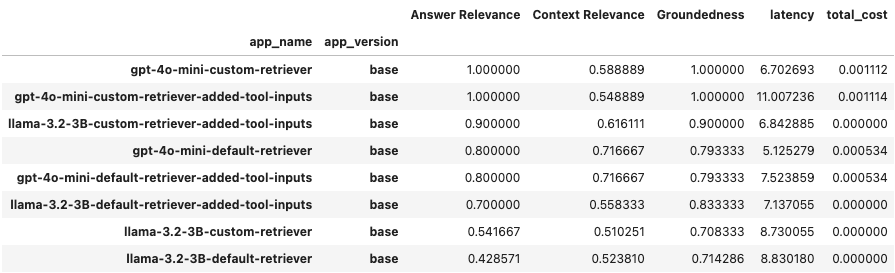
We have conducted experiments using the 2 models, default/custom query engines, and extra tool input parameters description (ReAct agent struggled without the explicit tool input params description, trying to call non-existing tools to refactor the input). We can review the results as a DataFrame using a get_leaderboard() method.
Conclusion
We obtained a private corpus, incorporating GPT models for the custom dataset generation. The actual corpus content is pretty interesting and diverse. That’s the reason why a lot of models are successfully fine-tuned using the GPT-generated samples right now.
Neo4j DB provides convenient interfaces for a lot of frameworks while having one of the best UI capabilities (Aura). In real projects, we often have relations between the data, and GraphDB is a perfect choice for such use cases.
On top of the private corpus, we implemented different RAG approaches (standalone and as a part of the agent). Based on the RAG Triad metrics, we observed that an OpenAI-based agent works perfectly, while a well-prompted ReAct agent performs relatively the same. A big difference was in the usage of a custom query engine. That’s reasonable because we configured some specific procedures and thresholds that align with our data. In addition, both solutions have high groundedness, which is very important for RAG applications.
Another interesting takeaway is that the Agent call latency of the Llama3.2 3B and gpt-4o-mini API was pretty much the same (of course the most time took the DB call, but the difference is still not that big).
Though our system works pretty well, there are a lot of improvements to be done, such as keyword search, rerankers, neighbor chunking selection, and the ground truth labels comparison. These topics will be discussed in the next articles on the RAG applications.
Private corpus, alongside the code and prompts, can be found on GitHub.
P.S.
I want to thank my colleagues: Alex Simkiv, Andy Bosyi, and Nazar Savchenko for productive conversations, collaboration, and valuable advice as well as the entire MindCraft.ai team for their constant support.
From Retrieval to Intelligence: Exploring RAG, Agent+RAG, and Evaluation with TruLens was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
Originally appeared here:
From Retrieval to Intelligence: Exploring RAG, Agent+RAG, and Evaluation with TruLens