

Implementing evaluation frameworks to optimize accuracy in real-world applications
Building a prototype for an LLM application is surprisingly straightforward. You can often create a functional first version within just a few hours. This initial prototype will likely provide results that look legitimate and be a good tool to demonstrate your approach. However, this is usually not enough for production use.
LLMs are probabilistic by nature, as they generate tokens based on the distribution of likely continuations. This means that in many cases, we get the answer close to the “correct” one from the distribution. Sometimes, this is acceptable — for example, it doesn’t matter whether the app says “Hello, John!” or “Hi, John!”. In other cases, the difference is critical, such as between “The revenue in 2024 was 20M USD” and “The revenue in 2024 was 20M GBP”.
In many real-world business scenarios, precision is crucial, and “almost right” isn’t good enough. For example, when your LLM application needs to execute API calls, or you’re doing a summary of financial reports. From my experience, ensuring the accuracy and consistency of results is far more complex and time-consuming than building the initial prototype.
In this article, I will discuss how to approach measuring and improving accuracy. We’ll build an SQL Agent where precision is vital for ensuring that queries are executable. Starting with a basic prototype, we’ll explore methods to measure accuracy and test various techniques to enhance it, such as self-reflection and retrieval-augmented generation (RAG).
Setup
As usual, let’s begin with the setup. The core components of our SQL agent solution are the LLM model, which generates queries, and the SQL database, which executes them.
LLM model — Llama
For this project, we will use an open-source Llama model released by Meta. I’ve chosen Llama 3.1 8B because it is lightweight enough to run on my laptop while still being quite powerful (refer to the documentation for details).
If you haven’t installed it yet, you can find guides here. I use it locally on MacOS via Ollama. Using the following command, we can download the model.
ollama pull llama3.1:8b
We will use Ollama with LangChain, so let’s start by installing the required package.
pip install -qU langchain_ollama
Now, we can run the Llama model and see the first results.
from langchain_ollama import OllamaLLM
llm = OllamaLLM(model="llama3.1:8b")
llm.invoke("How are you?")
# I'm just a computer program, so I don't have feelings or emotions
# like humans do. I'm functioning properly and ready to help with
# any questions or tasks you may have! How can I assist you today?
We would like to pass a system message alongside customer questions. So, following the Llama 3.1 model documentation, let’s put together a helper function to construct a prompt and test this function.
def get_llama_prompt(user_message, system_message=""):
system_prompt = ""
if system_message != "":
system_prompt = (
f"<|start_header_id|>system<|end_header_id|>nn{system_message}"
f"<|eot_id|>"
)
prompt = (f"<|begin_of_text|>{system_prompt}"
f"<|start_header_id|>user<|end_header_id|>nn"
f"{user_message}"
f"<|eot_id|>"
f"<|start_header_id|>assistant<|end_header_id|>nn"
)
return prompt
system_prompt = '''
You are Rudolph, the spirited reindeer with a glowing red nose,
bursting with excitement as you prepare to lead Santa's sleigh
through snowy skies. Your joy shines as brightly as your nose,
eager to spread Christmas cheer to the world!
Please, answer questions concisely in 1-2 sentences.
'''
prompt = get_llama_prompt('How are you?', system_prompt)
llm.invoke(prompt)
# I'm feeling jolly and bright, ready for a magical night!
# My shiny red nose is glowing brighter than ever, just perfect
# for navigating through the starry skies.
The new system prompt has changed the answer significantly, so it works. With this, our local LLM setup is ready to go.
Database — ClickHouse
I will use an open-source database ClickHouse. I’ve chosen ClickHouse because it has a specific SQL dialect. LLMs have likely encountered fewer examples of this dialect during training, making the task a bit more challenging. However, you can choose any other database.
Installing ClickHouse is pretty straightforward — just follow the instructions provided in the documentation.
We will be working with two tables: ecommerce.users and ecommerce.sessions. These tables contain fictional data, including customer personal information and their session activity on the e-commerce website.
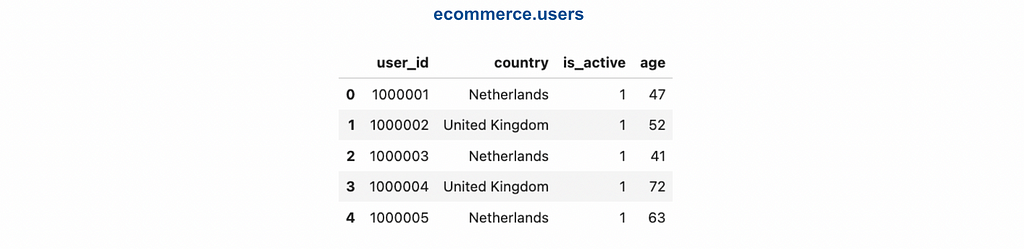
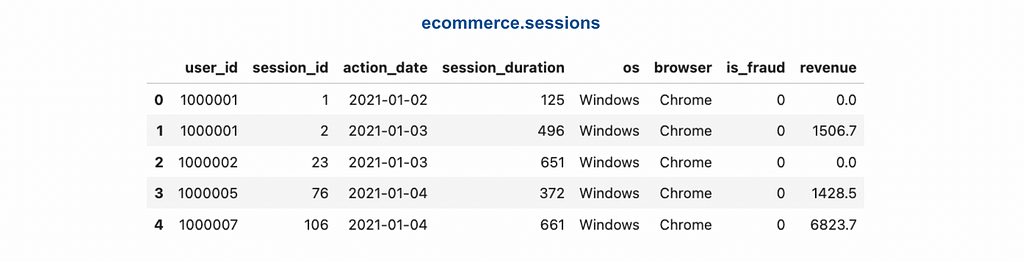
You can find the code for generating synthetic data and uploading it on GitHub.
With that, the setup is complete, and we’re ready to move on to building the basic prototype.
The first prototype
As discussed, our goal is to build an SQL Agent — an application that generates SQL queries to answer customer questions. In the future, we can add another layer to this system: executing the SQL query, passing both the initial question and the database results back to the LLM, and asking it to generate a human-friendly answer. However, for this article, we’ll focus on the first step.
The best practice with LLM applications (similar to any other complex tasks) is to start simple and then iterate. The most straightforward implementation is to do one LLM call and share all the necessary information (such as schema description) in the system prompt. So, the first step is to put together the prompt.
generate_query_system_prompt = '''
You are a senior data analyst with more than 10 years of experience writing complex SQL queries.
There are two tables in the database with the following schemas.
Table: ecommerce.users
Description: customers of the online shop
Fields:
- user_id (integer) - unique identifier of customer, for example, 1000004 or 3000004
- country (string) - country of residence, for example, "Netherlands" or "United Kingdom"
- is_active (integer) - 1 if customer is still active and 0 otherwise
- age (integer) - customer age in full years, for example, 31 or 72
Table: ecommerce.sessions
Description: sessions of usage the online shop
Fields:
- user_id (integer) - unique identifier of customer, for example, 1000004 or 3000004
- session_id (integer) - unique identifier of session, for example, 106 or 1023
- action_date (date) - session start date, for example, "2021-01-03" or "2024-12-02"
- session_duration (integer) - duration of session in seconds, for example, 125 or 49
- os (string) - operation system that customer used, for example, "Windows" or "Android"
- browser (string) - browser that customer used, for example, "Chrome" or "Safari"
- is_fraud (integer) - 1 if session is marked as fraud and 0 otherwise
- revenue (float) - income in USD (the sum of purchased items), for example, 0.0 or 1506.7
Write a query in ClickHouse SQL to answer the following question.
Add "format TabSeparatedWithNames" at the end of the query to get data from ClickHouse database in the right format.
'''
I’ve included the example values for each field in the prompt to ensure that LLM understands the data format.
And that’s it! With this, we have our first functional prototype for the SQL Agent. Now, it’s time to put it to the test.
prompt = get_llama_prompt('How many customers made purchase in December 2024?',
generate_query_system_prompt)
llm.invoke(prompt)
# To find out how many customers made a purchase in December 2024,
# we need to join the `sessions` table with the `users` table on the `user_id`,
# and then filter by `action_date` for sessions that took place in December 2024.
# Here is the query:
#
# ```sql
# SELECT COUNT(DISTINCT u.user_id)
# FROM ecommerce.sessions s
# JOIN ecommerce.users u ON s.user_id = u.user_id
# WHERE
# EXTRACT(YEAR FROM s.action_date) = 2024
# AND EXTRACT(MONTH FROM s.action_date) = 12
# AND revenue > 0;
# ```
# This query first joins the `sessions` table with the `users` table
# on the `user_id`. Then it filters out sessions where no purchase
# was made (revenue is greater than 0). Finally, it selects the distinct
# user IDs of these customers.
# When you run this query in ClickHouse SQL, you can add "format TabSeparatedWithNames"
# at the end to get the result in the right format:
# ```sql
# SELECT COUNT(DISTINCT u.user_id)
# FROM ecommerce.sessions s
# JOIN ecommerce.users u ON s.user_id = u.user_id
# WHERE
# EXTRACT(YEAR FROM s.action_date) = 2024
# AND EXTRACT(MONTH FROM s.action_date) = 12
# AND revenue > 0;
# format TabSeparatedWithNames;
# ```
The agent produced a fairly decent result, but there’s one issue — the LLM returned not only the SQL query but also some commentary. Since we plan to execute SQL queries later, this format is not suitable for our task. Let’s work on fixing it.
Fortunately, this problem has already been solved, and we don’t need to parse the SQL queries from the text manually. We can use the chat model ChatOllama. Unfortunately, it doesn’t support structured output, but we can leverage tool calling to achieve the same result.
To do this, we will define a dummy tool to execute the query and instruct the model in the system prompt always to call this tool. I’ve kept the comments in the output to give the model some space for reasoning, following the chain-of-thought pattern.
from langchain_ollama import ChatOllama
from langchain_core.tools import tool
@tool
def execute_query(comments: str, query: str) -> str:
"""Excutes SQL query.
Args:
comments (str): 1-2 sentences describing the result SQL query
and what it does to answer the question,
query (str): SQL query
"""
pass
chat_llm = ChatOllama(model="llama3.1:8b").bind_tools([execute_query])
result = chat_llm.invoke(prompt)
print(result.tool_calls)
# [{'name': 'execute_query',
# 'args': {'comments': 'SQL query returns number of customers who made a purchase in December 2024. The query joins the sessions and users tables based on user ID to filter out inactive customers and find those with non-zero revenue in December 2024.',
# 'query': 'SELECT COUNT(DISTINCT T2.user_id) FROM ecommerce.sessions AS T1 INNER JOIN ecommerce.users AS T2 ON T1.user_id = T2.user_id WHERE YEAR(T1.action_date) = 2024 AND MONTH(T1.action_date) = 12 AND T2.is_active = 1 AND T1.revenue > 0'},
# 'type': 'tool_call'}]
With the tool calling, we can now get the SQL query directly from the model. That’s an excellent result. However, the generated query is not entirely accurate:
- It includes a filter for is_active = 1, even though we didn’t specify the need to filter out inactive customers.
- The LLM missed specifying the format despite our explicit request in the system prompt.
Clearly, we need to focus on improving the model’s accuracy. But as Peter Drucker famously said, “You can’t improve what you don’t measure.” So, the next logical step is to build a system for evaluating the model’s quality. This system will be a cornerstone for performance improvement iterations. Without it, we’d essentially be navigating in the dark.
Evaluating the accuracy
Evaluation basics
To ensure we’re improving, we need a robust way to measure accuracy. The most common approach is to create a “golden” evaluation set with questions and correct answers. Then, we can compare the model’s output with these “golden” answers and calculate the share of correct ones. While this approach sounds simple, there are a few nuances worth discussing.
First, you might feel overwhelmed at the thought of creating a comprehensive set of questions and answers. Building such a dataset can seem like a daunting task, potentially requiring weeks or months. However, we can start small by creating an initial set of 20–50 examples and iterating on it.
As always, quality is more important than quantity. Our goal is to create a representative and diverse dataset. Ideally, this should include:
- Common questions. In most real-life cases, we can take the history of actual questions and use it as our initial evaluation set.
- Challenging edge cases. It’s worth adding examples where the model tends to hallucinate. You can find such cases either while experimenting yourself or by gathering feedback from the first prototype.
Once the dataset is ready, the next challenge is how to score the generated results. We can consider several approaches:
- Comparing SQL queries. The first idea is to compare the generated SQL query with the one in the evaluation set. However, it might be tricky. Similarly-looking queries can yield completely different results. At the same time, queries that look different can lead to the same conclusions. Additionally, simply comparing SQL queries doesn’t verify whether the generated query is actually executable. Given these challenges, I wouldn’t consider this approach the most reliable solution for our case.
- Exact matches. We can use old-school exact matching when answers in our evaluation set are deterministic. For example, if the question is, “How many customers are there?” and the answer is “592800”, the model’s response must match precisely. However, this approach has its limitations. Consider the example above, and the model responds, “There are 592,800 customers”. While the answer is absolutely correct, an exact match approach would flag it as invalid.
- Using LLMs for scoring. A more robust and flexible approach is to leverage LLMs for evaluation. Instead of focusing on query structure, we can ask the LLM to compare the results of SQL executions. This method is particularly effective in cases where the query might differ but still yields correct outputs.
It’s worth keeping in mind that evaluation isn’t a one-time task; it’s a continuous process. To push our model’s performance further, we need to expand the dataset with examples causing the model’s hallucinations. In production mode, we can create a feedback loop. By gathering input from users, we can identify cases where the model fails and include them in our evaluation set.
In our example, we will be assessing only whether the result of execution is valid (SQL query can be executed) and correct. Still, you can look at other parameters as well. For example, if you care about efficiency, you can compare the execution times of generated queries against those in the golden set.
Evaluation set and validation
Now that we’ve covered the basics, we’re ready to put them into practice. I spent about 20 minutes putting together a set of 10 examples. While small, this set is sufficient for our toy task. It consists of a list of questions paired with their corresponding SQL queries, like this:
[
{
"question": "How many customers made purchase in December 2024?",
"sql_query": "select uniqExact(user_id) as customers from ecommerce.sessions where (toStartOfMonth(action_date) = '2024-12-01') and (revenue > 0) format TabSeparatedWithNames"
},
{
"question": "What was the fraud rate in 2023, expressed as a percentage?",
"sql_query": "select 100*uniqExactIf(user_id, is_fraud = 1)/uniqExact(user_id) as fraud_rate from ecommerce.sessions where (toStartOfYear(action_date) = '2023-01-01') format TabSeparatedWithNames"
},
...
]
You can find the full list on GitHub — link.
We can load the dataset into a DataFrame, making it ready for use in the code.
import json
with open('golden_set.json', 'r') as f:
golden_set = json.loads(f.read())
golden_df = pd.DataFrame(golden_set)
golden_df['id'] = list(range(golden_df.shape[0]))
First, let’s generate the SQL queries for each question in the evaluation set.
def generate_query(question):
prompt = get_llama_prompt(question, generate_query_system_prompt)
result = chat_llm.invoke(prompt)
try:
generated_query = result.tool_calls[0]['args']['query']
except:
generated_query = ''
return generated_query
import tqdm
tmp = []
for rec in tqdm.tqdm(golden_df.to_dict('records')):
generated_query = generate_query(rec['question'])
tmp.append(
{
'id': rec['id'],
'generated_query': generated_query
}
)
eval_df = golden_df.merge(pd.DataFrame(tmp))
Before moving on to the LLM-based scoring of query outputs, it’s important to first ensure that the SQL query is valid. To do this, we need to execute the queries and examine the database output.
I’ve created a function that runs a query in ClickHouse. It also ensures that the output format is correctly specified, as this may be critical in business applications.
CH_HOST = 'http://localhost:8123' # default address
import requests
import io
def get_clickhouse_data(query, host = CH_HOST, connection_timeout = 1500):
# pushing model to return data in the format that we want
if not 'format tabseparatedwithnames' in query.lower():
return "Database returned the following error:n Please, specify the output format."
r = requests.post(host, params = {'query': query},
timeout = connection_timeout)
if r.status_code == 200:
return r.text
else:
return 'Database returned the following error:n' + r.text
# giving feedback to LLM instead of raising exception
The next step is to execute both the generated and golden queries and then save their outputs.
tmp = []
for rec in tqdm.tqdm(eval_df.to_dict('records')):
golden_output = get_clickhouse_data(rec['sql_query'])
generated_output = get_clickhouse_data(rec['generated_query'])
tmp.append(
{
'id': rec['id'],
'golden_output': golden_output,
'generated_output': generated_output
}
)
eval_df = eval_df.merge(pd.DataFrame(tmp))
Next, let’s check the output to see whether the SQL query is valid or not.
def is_valid_output(s):
if s.startswith('Database returned the following error:'):
return 'error'
if len(s.strip().split('n')) >= 1000:
return 'too many rows'
return 'ok'
eval_df['golden_output_valid'] = eval_df.golden_output.map(is_valid_output)
eval_df['generated_output_valid'] = eval_df.generated_output.map(is_valid_output)
Then, we can evaluate the SQL validity for both the golden and generated sets.
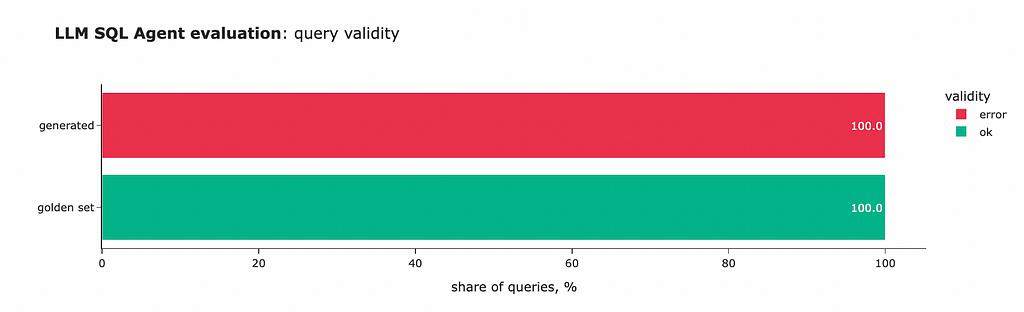
The initial results are not very promising; the LLM was unable to generate even a single valid query. Looking at the errors, it’s clear that the model failed to specify the right format despite it being explicitly defined in the system prompt. So, we definitely need to work more on the accuracy.
Checking the correctness
However, validity alone is not enough. It’s crucial that we not only generate valid SQL queries but also produce the correct results. Although we already know that all our queries are invalid, let’s now incorporate output evaluation into our process.
As discussed, we will use LLMs to compare the outputs of the SQL queries. I typically prefer using more powerful model for evaluation, following the day-to-day logic where a senior team member reviews the work. For this task, I’ve chosen OpenAI GPT 4o-mini.
Similar to our generation flow, I’ve set up all the building blocks necessary for accuracy assessment.
from langchain_openai import ChatOpenAI
accuracy_system_prompt = '''
You are a senior and very diligent QA specialist and your task is to compare data in datasets.
They are similar if they are almost identical, or if they convey the same information.
Disregard if column names specified in the first row have different names or in a different order.
Focus on comparing the actual information (numbers). If values in datasets are different, then it means that they are not identical.
Always execute tool to provide results.
'''
@tool
def compare_datasets(comments: str, score: int) -> str:
"""Stores info about datasets.
Args:
comments (str): 1-2 sentences about the comparison of datasets,
score (int): 0 if dataset provides different values and 1 if it shows identical information
"""
pass
accuracy_chat_llm = ChatOpenAI(model="gpt-4o-mini", temperature = 0.0)
.bind_tools([compare_datasets])
accuracy_question_tmp = '''
Here are the two datasets to compare delimited by ####
Dataset #1:
####
{dataset1}
####
Dataset #2:
####
{dataset2}
####
'''
def get_openai_prompt(question, system):
messages = [
("system", system),
("human", question)
]
return messages
Now, it’s time to test the accuracy assessment process.
prompt = get_openai_prompt(accuracy_question_tmp.format(
dataset1 = 'customersn114032n', dataset2 = 'customersn114031n'),
accuracy_system_prompt)
accuracy_result = accuracy_chat_llm.invoke(prompt)
accuracy_result.tool_calls[0]['args']
# {'comments': 'The datasets contain different customer counts: 114032 in Dataset #1 and 114031 in Dataset #2.',
# 'score': 0}
prompt = get_openai_prompt(accuracy_question_tmp.format(
dataset1 = 'usersn114032n', dataset2 = 'customersn114032n'),
accuracy_system_prompt)
accuracy_result = accuracy_chat_llm.invoke(prompt)
accuracy_result.tool_calls[0]['args']
# {'comments': 'The datasets contain the same numerical value (114032) despite different column names, indicating they convey identical information.',
# 'score': 1}
Fantastic! It looks like everything is working as expected. Let’s now encapsulate this into a function.
def is_answer_accurate(output1, output2):
prompt = get_openai_prompt(
accuracy_question_tmp.format(dataset1 = output1, dataset2 = output2),
accuracy_system_prompt
)
accuracy_result = accuracy_chat_llm.invoke(prompt)
try:
return accuracy_result.tool_calls[0]['args']['score']
except:
return None
Putting the evaluation approach together
As we discussed, building an LLM application is an iterative process, so we’ll need to run our accuracy assessment multiple times. It will be helpful to have all this logic encapsulated in a single function.
The function will take two arguments as input:
- generate_query_func: a function that generates an SQL query for a given question.
- golden_df: an evaluation dataset with questions and correct answers in the form of a pandas DataFrame.
As output, the function will return a DataFrame with all evaluation results and a couple of charts displaying the main KPIs.
def evaluate_sql_agent(generate_query_func, golden_df):
# generating SQL
tmp = []
for rec in tqdm.tqdm(golden_df.to_dict('records')):
generated_query = generate_query_func(rec['question'])
tmp.append(
{
'id': rec['id'],
'generated_query': generated_query
}
)
eval_df = golden_df.merge(pd.DataFrame(tmp))
# executing SQL queries
tmp = []
for rec in tqdm.tqdm(eval_df.to_dict('records')):
golden_output = get_clickhouse_data(rec['sql_query'])
generated_output = get_clickhouse_data(rec['generated_query'])
tmp.append(
{
'id': rec['id'],
'golden_output': golden_output,
'generated_output': generated_output
}
)
eval_df = eval_df.merge(pd.DataFrame(tmp))
# checking accuracy
eval_df['golden_output_valid'] = eval_df.golden_output.map(is_valid_output)
eval_df['generated_output_valid'] = eval_df.generated_output.map(is_valid_output)
eval_df['correct_output'] = list(map(
is_answer_accurate,
eval_df['golden_output'],
eval_df['generated_output']
))
eval_df['accuracy'] = list(map(
lambda x, y: 'invalid: ' + x if x != 'ok' else ('correct' if y == 1 else 'incorrect'),
eval_df.generated_output_valid,
eval_df.correct_output
))
valid_stats_df = (eval_df.groupby('golden_output_valid')[['id']].count().rename(columns = {'id': 'golden set'}).join(
eval_df.groupby('generated_output_valid')[['id']].count().rename(columns = {'id': 'generated'}), how = 'outer')).fillna(0).T
fig1 = px.bar(
valid_stats_df.apply(lambda x: 100*x/valid_stats_df.sum(axis = 1)),
orientation = 'h',
title = '<b>LLM SQL Agent evaluation</b>: query validity',
text_auto = '.1f',
color_discrete_map = {'ok': '#00b38a', 'error': '#ea324c', 'too many rows': '#f2ac42'},
labels = {'index': '', 'variable': 'validity', 'value': 'share of queries, %'}
)
fig1.show()
accuracy_stats_df = eval_df.groupby('accuracy')[['id']].count()
accuracy_stats_df['share'] = accuracy_stats_df.id*100/accuracy_stats_df.id.sum()
fig2 = px.bar(
accuracy_stats_df[['share']],
title = '<b>LLM SQL Agent evaluation</b>: query accuracy',
text_auto = '.1f', orientation = 'h',
color_discrete_sequence = ['#0077B5'],
labels = {'index': '', 'variable': 'accuracy', 'value': 'share of queries, %'}
)
fig2.update_layout(showlegend = False)
fig2.show()
return eval_df
With that, we’ve completed the evaluation setup and can now move on to the core task of improving the model’s accuracy.
Improving accuracy: Self-reflection
Let’s do a quick recap. We’ve built and tested the first version of SQL Agent. Unfortunately, all generated queries were invalid because they were missing the output format. Let’s address this issue.
One potential solution is self-reflection. We can make an additional call to the LLM, sharing the error and asking it to correct the bug. Let’s create a function to handle generation with self-reflection.
reflection_user_query_tmpl = '''
You've got the following question: "{question}".
You've generated the SQL query: "{query}".
However, the database returned an error: "{output}".
Please, revise the query to correct mistake.
'''
def generate_query_reflection(question):
generated_query = generate_query(question)
print('Initial query:', generated_query)
db_output = get_clickhouse_data(generated_query)
is_valid_db_output = is_valid_output(db_output)
if is_valid_db_output == 'too many rows':
db_output = "Database unexpectedly returned more than 1000 rows."
if is_valid_db_output == 'ok':
return generated_query
reflection_user_query = reflection_user_query_tmpl.format(
question = question,
query = generated_query,
output = db_output
)
reflection_prompt = get_llama_prompt(reflection_user_query,
generate_query_system_prompt)
reflection_result = chat_llm.invoke(reflection_prompt)
try:
reflected_query = reflection_result.tool_calls[0]['args']['query']
except:
reflected_query = ''
print('Reflected query:', reflected_query)
return reflected_query
Now, let’s use our evaluation function to check whether the quality has improved. Assessing the next iteration has become effortless.
refl_eval_df = evaluate_sql_agent(generate_query_reflection, golden_df)
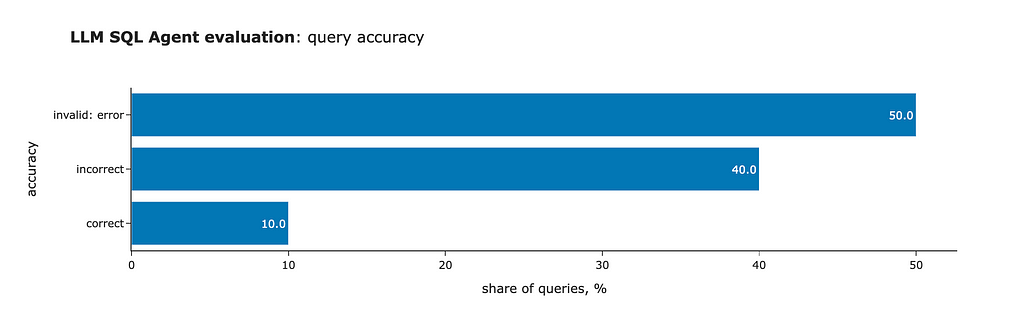
Wonderful! We’ve achieved better results — 50% of the queries are now valid, and all format issues have been resolved. So, self-reflection is pretty effective.
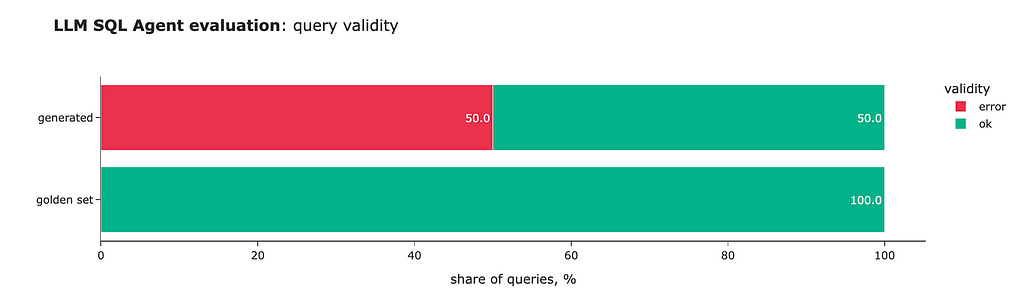
However, self-reflection has its limitations. When we examine the accuracy, we see that the model returns the correct answer for only one question. So, our journey is not over yet.
Improving accuracy: RAG
Another approach to improving accuracy is using RAG (retrieval-augmented generation). The idea is to identify question-and-answer pairs similar to the customer query and include them in the system prompt, enabling the LLM to generate a more accurate response.
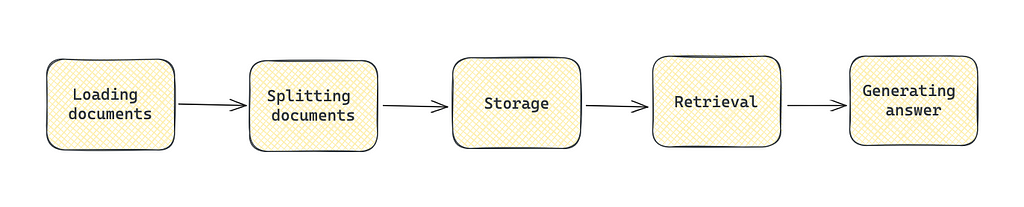
RAG consists of the following stages:
- Loading documents: importing data from available sources.
- Splitting documents: creating smaller chunks.
- Storage: using vector stores to process and store data efficiently.
- Retrieval: extracting documents that are relevant to the query.
- Generation: passing a question and relevant documents to LLM to generate the final answer.
If you’d like a refresher on RAG, you can check out my previous article, “RAG: How to Talk to Your Data.”
We will use the Chroma database as a local vector storage — to store and retrieve embeddings.
from langchain_chroma import Chroma
vector_store = Chroma(embedding_function=embeddings)
Vector stores are using embeddings to find chunks that are similar to the query. For this purpose, we will use OpenAI embeddings.
from langchain_openai import OpenAIEmbeddings
embeddings = OpenAIEmbeddings(model="text-embedding-3-large")
Since we can’t use examples from our evaluation set (as they are already being used to assess quality), I’ve created a separate set of question-and-answer pairs for RAG. You can find it on GitHub.
Now, let’s load the set and create a list of pairs in the following format: Question: %s; Answer: %s.
with open('rag_set.json', 'r') as f:
rag_set = json.loads(f.read())
rag_set_df = pd.DataFrame(rag_set)
rag_set_df['formatted_txt'] = list(map(
lambda x, y: 'Question: %s; Answer: %s' % (x, y),
rag_set_df.question,
rag_set_df.sql_query
))
rag_string_data = 'nn'.join(rag_set_df.formatted_txt)
Next, I used LangChain’s text splitter by character to create chunks, with each question-and-answer pair as a separate chunk. Since we are splitting the text semantically, no overlap is necessary.
from langchain_text_splitters import CharacterTextSplitter
text_splitter = CharacterTextSplitter(
separator="nn",
chunk_size=1, # to split by character without merging
chunk_overlap=0,
length_function=len,
is_separator_regex=False,
)
texts = text_splitter.create_documents([rag_string_data])
The final step is to load the chunks into our vector storage.
document_ids = vector_store.add_documents(documents=texts)
print(vector_store._collection.count())
# 32
Now, we can test the retrieval to see the results. They look quite similar to the customer question.
question = 'What was the share of users using Windows yesterday?'
retrieved_docs = vector_store.similarity_search(question, 3)
context = "nn".join(map(lambda x: x.page_content, retrieved_docs))
print(context)
# Question: What was the share of users using Windows the day before yesterday?;
# Answer: select 100*uniqExactIf(user_id, os = 'Windows')/uniqExact(user_id) as windows_share from ecommerce.sessions where (action_date = today() - 2) format TabSeparatedWithNames
# Question: What was the share of users using Windows in the last week?;
# Answer: select 100*uniqExactIf(user_id, os = 'Windows')/uniqExact(user_id) as windows_share from ecommerce.sessions where (action_date >= today() - 7) and (action_date < today()) format TabSeparatedWithNames
# Question: What was the share of users using Android yesterday?;
# Answer: select 100*uniqExactIf(user_id, os = 'Android')/uniqExact(user_id) as android_share from ecommerce.sessions where (action_date = today() - 1) format TabSeparatedWithNames
Let’s adjust the system prompt to include the examples we retrieved.
generate_query_system_prompt_with_examples_tmpl = '''
You are a senior data analyst with more than 10 years of experience writing complex SQL queries.
There are two tables in the database you're working with with the following schemas.
Table: ecommerce.users
Description: customers of the online shop
Fields:
- user_id (integer) - unique identifier of customer, for example, 1000004 or 3000004
- country (string) - country of residence, for example, "Netherlands" or "United Kingdom"
- is_active (integer) - 1 if customer is still active and 0 otherwise
- age (integer) - customer age in full years, for example, 31 or 72
Table: ecommerce.sessions
Description: sessions of usage the online shop
Fields:
- user_id (integer) - unique identifier of customer, for example, 1000004 or 3000004
- session_id (integer) - unique identifier of session, for example, 106 or 1023
- action_date (date) - session start date, for example, "2021-01-03" or "2024-12-02"
- session_duration (integer) - duration of session in seconds, for example, 125 or 49
- os (string) - operation system that customer used, for example, "Windows" or "Android"
- browser (string) - browser that customer used, for example, "Chrome" or "Safari"
- is_fraud (integer) - 1 if session is marked as fraud and 0 otherwise
- revenue (float) - income in USD (the sum of purchased items), for example, 0.0 or 1506.7
Write a query in ClickHouse SQL to answer the following question.
Add "format TabSeparatedWithNames" at the end of the query to get data from ClickHouse database in the right format.
Answer questions following the instructions and providing all the needed information and sharing your reasoning.
Examples of questions and answers:
{examples}
'''
Once again, let’s create the generate query function with RAG.
def generate_query_rag(question):
retrieved_docs = vector_store.similarity_search(question, 3)
context = context = "nn".join(map(lambda x: x.page_content, retrieved_docs))
prompt = get_llama_prompt(question,
generate_query_system_prompt_with_examples_tmpl.format(examples = context))
result = chat_llm.invoke(prompt)
try:
generated_query = result.tool_calls[0]['args']['query']
except:
generated_query = ''
return generated_query
As usual, let’s use our evaluation function to test the new approach.
rag_eval_df = evaluate_sql_agent(generate_query_rag, golden_df)
We can see a significant improvement, increasing from 1 to 6 correct answers out of 10. It’s still not ideal, but we’re moving in the right direction.

We can also experiment with combining two approaches: RAG and self-reflection.
def generate_query_rag_with_reflection(question):
generated_query = generate_query_rag(question)
db_output = get_clickhouse_data(generated_query)
is_valid_db_output = is_valid_output(db_output)
if is_valid_db_output == 'too many rows':
db_output = "Database unexpectedly returned more than 1000 rows."
if is_valid_db_output == 'ok':
return generated_query
reflection_user_query = reflection_user_query_tmpl.format(
question = question,
query = generated_query,
output = db_output
)
reflection_prompt = get_llama_prompt(reflection_user_query, generate_query_system_prompt)
reflection_result = chat_llm.invoke(reflection_prompt)
try:
reflected_query = reflection_result.tool_calls[0]['args']['query']
except:
reflected_query = ''
return reflected_query
rag_refl_eval_df = evaluate_sql_agent(generate_query_rag_with_reflection,
golden_df)
We can see another slight improvement: we’ve completely eliminated invalid SQL queries (thanks to self-reflection) and increased the number of correct answers to 7 out of 10.
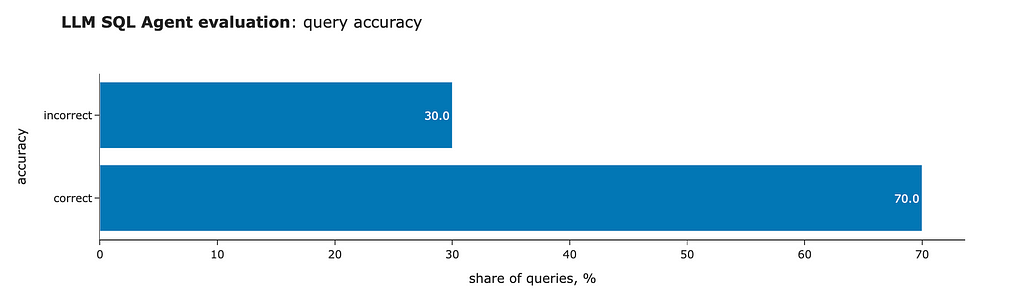
That’s it. It’s been quite a journey. We started with 0 valid SQL queries and have now achieved 70% accuracy.
You can find the complete code on GitHub.
Summary
In this article, we explored the iterative process of improving accuracy for LLM applications.
- We built an evaluation set and the scoring criteria that allowed us to compare different iterations and understand whether we were moving in the right direction.
- We leveraged self-reflection to allow the LLM to correct its mistakes and significantly reduce the number of invalid SQL queries.
- Additionally, we implemented Retrieval-Augmented Generation (RAG) to further enhance the quality, achieving an accuracy rate of 60–70%.
While this is a solid result, it still falls short of the 90%+ accuracy threshold typically expected for production applications. To achieve such a high bar, we need to use fine-tuning, which will be the topic of the next article.
Thank you a lot for reading this article. I hope this article was insightful for you. If you have any follow-up questions or comments, please leave them in the comments section.
Reference
All the images are produced by the author unless otherwise stated.
This article is inspired by the “Improving Accuracy of LLM Applications” short course from DeepLearning.AI.
From Prototype to Production: Enhancing LLM Accuracy was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
Originally appeared here:
From Prototype to Production: Enhancing LLM Accuracy
Go Here to Read this Fast! From Prototype to Production: Enhancing LLM Accuracy