
Introducing a practical agent-engineering framework
Introduction
With a little over a year since the launch of ChatGPT, it is clear that public perception of “AI” has shifted dramatically. Part of this is a by-product of increased general awareness but it has more so been influenced by the realization that AI-powered systems may be (already are?) capable of human-level competence and performance. In many ways, ChatGPT has served as a proof-of-concept demonstration for AI as a whole. The work on this demonstration kicked off more than a half century ago and has now yielded compelling evidence that we are closer to a reality where we can ‘create machines that perform functions that require intelligence when performed by people,’ to borrow Ray Kurzweil’s definition. It should be no surprise then that the discussions and development around AI Agents have exploded in recent months. They are the embodiment of aspirations that AI has always aimed for.
To be clear, the concept of AI agents is by no means a new one. Our imaginations have been there many times over — C-3PO of Star Wars fame is embodied AI at its finest, capable of human-level natural language comprehension, dialogue, and autonomous action. In the more formal setting of academics, Norvig and Russell’s textbook on AI, Artificial Intelligence: A Modern Approach, states that intelligent agents are the main unifying theme. The ideas around AI agents, whether born in science or fiction, all seem a bit more realizable with the arrival of models like ChatGPT, Claude, and Gemini, which are broadly competent in diverse knowledge domains and equipped with strong comprehension and capability for human-level dialogue. Add in new capabilities like “vision” and function calling, and the stage is set for the proliferation of AI agent development.
As we barrel down the path toward the development of AI agents, it seems necessary to begin transitioning from prompt engineering to something broader, a.k.a. agent engineering, and establishing the appropriate frameworks, methodologies, and mental models to design them effectively. In this article, I set out to explore some of the key ideas and precepts of agent engineering within the LLM context.
Let’s explore on a high level the key sections of the Agent Engineering Framework. We begin with the ‘Agent Capabilities Requirements,’ where we aim to clearly define what the agent needs to do and how proficient it needs to be. In ‘Agent Engineering and Design,’ we evaluate the technologies available to us and begin thinking through the anatomy and orchestration of our agent(s).
This early-stage articulation of the framework is intended to be a practical mental model and is admittedly not comprehensive on all fronts. But I believe there is value in starting somewhere and then refining and enhancing over time.
The Agent Engineering Framework
Introduction
What is the purpose of building an AI agent? Does it have a job or a role? Actions in support of goals? Or goals in support of actions? Is a multi-capability agent better than a multi-agent swarm for a particular job? The beauty of human language is that it is flexible and allows us to metaphorically extend concepts in many directions. The downside to this is that can lead to ambiguity. In articulating the framework, I am purposefully trying to avoid parsing semantic distinctions between key terms, since many of them can be used interchangeably. We strive instead to surface concepts that generalize in their application to AI Agent Engineering broadly. As a result the framework at this stage is more of a mental model that aims to guide the thought process around Agent Engineering. The core ideas are relatively straightforward as you can see in the below graphic:
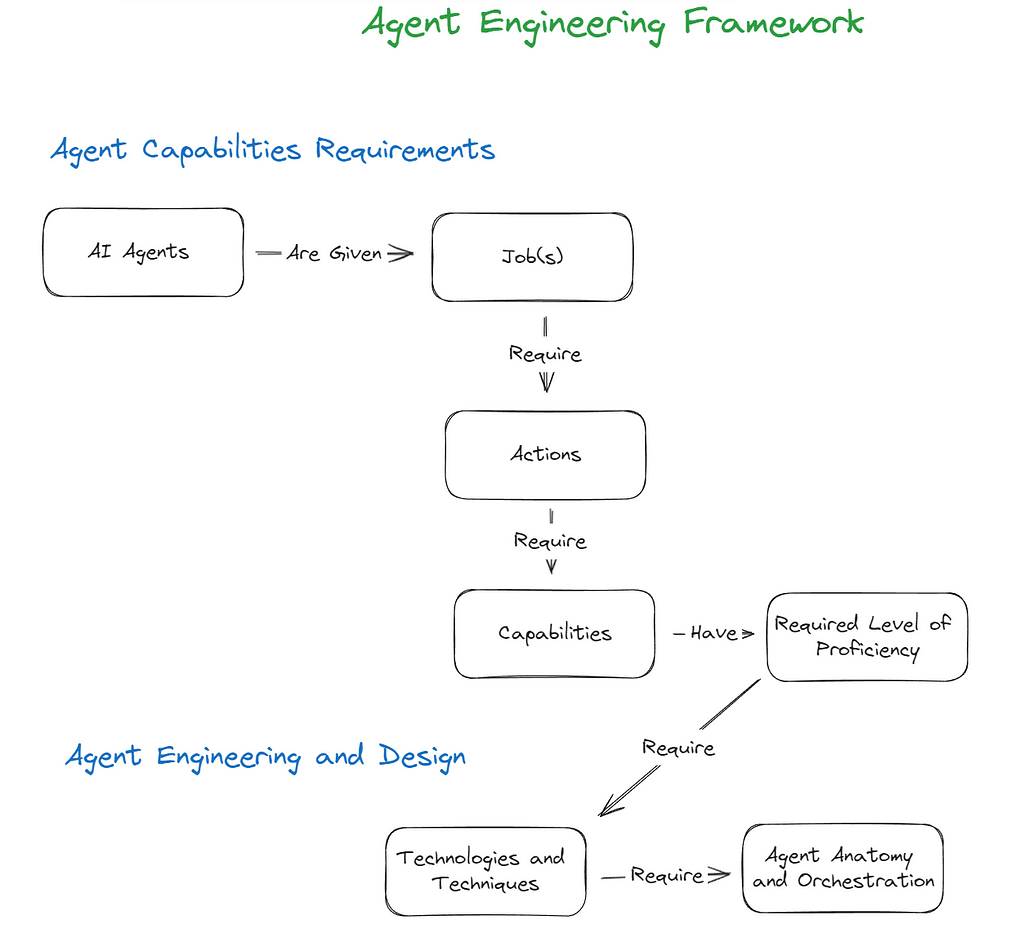
- AI agents are given Job(s)
- Job(s) require Action(s) to complete
- Performing Action(s) requires Capabilities
- Capabilities have a Required Level of Proficiency
- The Required Level of Proficiency requires Technologies and & Techniques
- Technologies and Techniques require Orchestration
Agent Capabilities Requirements
The Job to be Done
The initial step in designing an AI agent is to clearly outline what the agent is supposed to do. What are the primary jobs, tasks or goals the agent needs to accomplish? This could be framed as a high-level objective or broken down into specific jobs and tasks. You may decide to use a multi-agent swarm approach and assign each agent a task. The language and level of detail can vary. For example:
- An e-commerce chat bot’s job might involve handling general inquiries, analyzing customer behavior, and making product recommendations.
- A content creation agent’s job could entail brainstorming content ideas, and drafting articles or blog posts.
Note that in both of these cases, labels such as jobs, tasks, goals, etc. could be used interchangeably within the context of what the agent is supposed to do.
The Actions to Take to Perform the Job
Once the jobs to be done are defined, the next step is to determine the specific actions the agent needs to perform relative to that job. The focus moves from simply defining what the agent is supposed to achieve to specifying how it will get done through concrete actions. At this stage it is also important to begin considering the appropriate level of autonomy for the agent. For instance:
For a content creation agent, the actions might include:
- Calling another agent for content trend insights.
- Generating a list of content ideas based on those trends and target audience preferences.
- Drafting articles or blog posts.
- Taking instruction from a human user on edits and adjustments.
The content creation agent might autonomously generate and draft content, with a human editor providing final approval. Or a separate agent editor may be employed to do a first review before a human editor gets involved.
The Capabilities Needed
Now that we have outlined the actions that our agents need to take to perform the job(s) we proceed to articulating the capabilities needed to enable those actions. They can include everything from natural language dialogue, information retrieval, content generation, data analysis, continuous learning and more. They can also be expressed on a more technical level such as API calls, function calls etc. For example for our content creation agent the desired capabilities might be:
- Dynamic calling of the content trend agent’s API.
- Brainstorming and summarization capabilities.
- Tone appropriate content generation on current topics and trends.
- The ability to act on human provided instructions for editing content.
- Memory
It is important ultimately to focus on expressing the capabilities in ways that do not constrain the choices and eventual selection of which technologies to work with. For example, although we all are all quite enamored with LLMs, Large Action Models (LAMs) are evolving quickly and may be relevant for enabling the desired capabilities.
Required Proficiency Level of the Capabilities
While identifying the capabilities necessary for an agent to perform its job is a crucial step, it is equally important to assess and define the proficiency level required for each of these capabilities. This involves setting specific benchmarks and performance metrics that must be met for the agent and its capabilities to be considered proficient. These benchmarks can include accuracy, efficiency, and reliability.
For example, for our content creation agent, desired proficiency levels might include:
- Function calling reliability of 75%.
- Explainability of failed function calls of 99.99%.
- Function calling of the content trend agent that results in relevant topics at least 75% of the time on first attempt.
- Generation of content ideas that result in desirable topics 75% of the time.
- Retrieval of precise information with a precision rate of 99.99%.
- Generation of edits with a user feedback satisfaction rate of 90% or higher.
- Generation of final drafts with a user feedback satisfaction rate of 90% or higher.
Agent Engineering & Design
Mapping Required Proficiencies to Technologies and Techniques
Once the needed capabilities and required proficiency levels are specified, the next step is to determine how we can meet these requirements. This involves evaluating a fast growing arsenal of available technologies and techniques including LLMs, RAG, Guardrails, specialized APIs, and other ML/AI models to assess if they can achieve the specified proficiency levels. In all cases it is helpful to consider what any given technology or technique is best at on a high-level and the cost/benefit implications. I will superficially discuss a few here but it will be limited in scope and scale as there are myriad possibilities.
Broad Knowledge Proficiency
Broad knowledge refers to the general understanding and information across a wide range of topics and domains. This type of knowledge is essential for creating AI agents that can effectively engage in dialogue, understand context, and provide relevant responses across various subjects.
- LLMs — If your Agent’s capabilities require broad knowledge proficiency, the good news is that LLM development continues unabated. From open source models like LlaMA3 to the latest proprietary models from OpenAI, Anthropic and Google there are no shortage of options for technologies that provide high density coherence across such a vast expanse of human language and knowledge.
- Prompt Engineering — This dynamic and very active area of development essentially focuses on how to activate the contextually appropriate knowledge domains that are modeled by LLMs. Because of the kaleidoscopic qualities of language, mastery of this art can have a dramatic impact on proficiency levels of our Agent’s capabilities.
Specific Knowledge Proficiency
Specific knowledge involves a deeper understanding of particular domains or topics. This type of knowledge is necessary for tasks that require detailed expertise and familiarity with specialized content. What technologies/techniques might we consider as we aim at our proficiency targets?
- Retrieval-Augmented Generation (RAG) — RAG combines the generative capabilities of LLMs with information retrieval systems to incorporate information from external sources. This could be precise information or specific knowledge (e.g. a description of a unique method) that the LLM is able to “comprehend” in context because of it’s broad knowledge proficiency.
- Model Fine-Tuning — Fine-tuning LLMs on context-specific datasets adapt models to generate more contextually relevant responses in particular settings. Although not as popular as RAG, as Agent Engineering continues to gain traction we might find that proficiency requirements steer us toward this technique more often.
Precise Information
Precise information refers to highly accurate and specific data points that are critical for tasks requiring exact answers.
- Function Calling (aka Tool Use) — We are all wary of the AI agent that hallucinates regarding specific facts that are indisputable. If the required level of proficiency demands, we might turn to function calling to retrieve the specific information. For instance, an e-commerce agent might use a pricing API to provide the latest product prices or a stock market API to give real-time updates on stock values.
- Guardrails — Guardrails can help ensure that the agent provides precise and accurate information within its responses. This can involve rule-based constraints, directed conversational design, and intent pre-processing.
Agent Anatomy and Orchestration
Now that we have a firm grasp of what the Agent’s job is, the capabilities and proficiency levels required and the technologies available to enable them, we shift our focus to the anatomy and orchestration of the agent either in a solo configuration or some type of swarm or ecosystem. Should capabilities be registered to one agent, or should each capability be assigned to a unique agent that operates within a swarm? How do we develop capabilities and agents that can be re-purposed with minimum effort? This topic alone involves multiple articles and so we won’t dive into it further here. In some respects this is where the “rubber meets the road” and we find ourselves weaving together multiple technologies and techniques to breathe life into our Agents.
Conclusion
The journey from Prompt Engineering to Agent Engineering is just beginning, and there is much to learn and refine along the way. This first stab at an Agent Engineering Framework proposes a practical approach to designing AI agents by outlining a high-level mental model that can serve as a useful starting point in that evolution. The models and techniques available for building Agents will only continue to proliferate, creating a distinct need for frameworks that generalize away from any one specific technology or class of technologies. By clearly defining what an agent needs to do, outlining the actions required to perform these tasks, and specifying the necessary capabilities and proficiency levels, we set a strong and flexible foundation for our design and engineering efforts. It further provides a structure for our agents and their capabilities to be improved and evolve over time.
Thanks for reading and I hope you find the Agent Engineering Framework helpful in you agent oriented endeavors. Stay tuned for future refinements of framework and elaborations on various topics mentioned. If you would like to discuss the framework or other topics I have written about further, do not hesitate to connect with me on LinkedIn.
Unless otherwise noted, all images in this article are by the author.
From Prompt Engineering to Agent Engineering was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
Originally appeared here:
From Prompt Engineering to Agent Engineering
Go Here to Read this Fast! From Prompt Engineering to Agent Engineering