

Top 10 engineering lessons every data analyst should know
The data analyst job combines skills from different domains:
- We need to have business understanding and domain knowledge to be able to solve actual business problems and take into account all the details.
- Maths, statistics, and fundamental machine learning skills help us perform rigorous analyses and reach reliable conclusions from data.
- Visualisation skills and storytelling allow us to deliver our message and influence the product.
- Last but not least, computer science and the basics of software engineering are key to our efficiency.
I’ve learned a lot about computer science at university. I’ve tried at least a dozen programming languages (from low-level assembler and CUDA to high-level Java and Scala) and countless tools. My very first job offer was for a backend engineer role. I’ve decided not to pursue this path, but all this knowledge and principles have been beneficial in my analytical career. So, I would like to share the main principles with you in this article.
Code is not for computers. It’s for people
I’ve heard this mantra from software engineers many times. It’s well explained in one of the programming bibles, “Clean Code”.
Indeed, the ratio of time spent reading versus writing is well over 10 to 1. We are constantly reading old code as part of the effort to write new code.
In most cases, an engineer prefers more wordy code that is easy to understand to the idiomatic one-liner.
I must confess that I sometimes break this rule and write extra-long pandas one-liners. For example, let’s look at the code below. Do you have any idea what this code is doing?
# ad-hoc only code
df.groupby(['month', 'feature'])[['user_id']].nunique()
.rename(columns = {'user_id': 'users'})
.join(df.groupby(['month'])[['user_id']].nunique()
.rename(columns = {'user_id': 'total_users'})).apply(
lambda x: 100*x['users']/x['total_users'], axis = 1)
.reset_index().rename(columns = {0: 'users_share'})
.pivot(index = 'month', columns = 'feature', values = 'users_share')
Honestly, it’ll probably take me a bit to get up to speed with this code in a month. To make this code more readable, we can split it into steps.
# maintainable code
monthly_features_df = df.groupby(['month', 'feature'])[['user_id']].nunique()
.rename(columns = {'user_id': 'users'})
monthly_total_df = df.groupby(['month'])[['user_id']].nunique()
.rename(columns = {'user_id': 'total_users'})
monthly_df = monthly_features_df.join(monthly_total_df).reset_index()
monthly_df['users_share'] = 100*monthly_df.users/monthly_df.total_users
monthly_df.pivot(index = 'month', columns = 'feature', values = 'users_share')
Hopefully, now it’s easier for you to follow the logic and see that this code shows the percentage of customers that use each feature every month. The future me would definitely be way happier to see a code like this and appreciate all the efforts.
Automate repetitive tasks
If you have monotonous tasks that you repeat frequently, I recommend you consider automation. Let me share some examples from my experience that you might find helpful.
The most common way for analysts to automate tasks is to create a dashboard instead of calculating numbers manually every time. Self-serve tools (configurable dashboards where stakeholders can change filters and investigate the data) can save a lot of time and allow us to focus on more sophisticated and impactful research.
If a dashboard is not an option, there are other ways of automation. I was doing weekly reports and sending them to stakeholders via e-mail. After some time, it became a pretty tedious task, and I started to think about automation. At this point, I used the basic tool — cron on a virtual machine. I scheduled a Python script that calculated up-to-date numbers and sent an e-mail.
When you have a script, you just need to add one line to the cron file. For example, the line below will execute analytical_script.py every Monday at 9:10 AM.
10 9 * * 1 python analytical_script.py
Cron is a basic but still sustainable solution. Other tools that can be used to schedule scripts are Airflow, DBT, and Jenkins. You might know Jenkins as a CI/CD (continuous integration & continuous delivery) tool that engineers often use. It might surprise you. It’s customisable enough to execute analytical scripts as well.
If you need even more flexibility, it’s time to think about web applications. In my first team, we didn’t have an A/B test tool, so for a long time, analysts had to analyse each update manually. Finally, we wrote a Flask web application so that engineers could self-serve. Now, there are lightweight solutions for web applications, such as Gradio or Streamlit, that you can learn in a couple of days.
You can find a detailed guide for Gradio in one of my previous articles.
Master your tools
Tools you use every day at work play a significant role in your efficiency and final results. So it’s worth mastering them.
Of course, you can use a default text editor to write code, but most people use IDEs (Integrated Development Environment). You will be spending a lot of your working time on this application, so it’s worth assessing your options.
You can find the most popular IDEs for Python from the JetBrains 2021 survey.
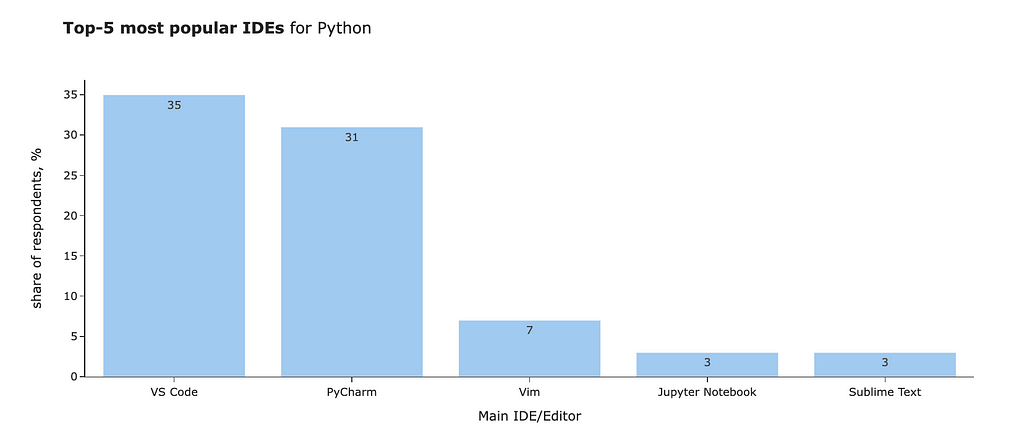
I usually use Python and Jupyter Notebooks for my day-to-day work. In my opinion, the best IDE for such tasks is JupyterLab. However, I’m trying other options right now to be able to use AI assistants. The benefits of auto-completion, which eliminates lots of boilerplate code, are invaluable for me, so I’m ready to take on switching costs. I encourage you to investigate different options and see what suits your work best.
The other helpful hack is shortcuts. You can do your tasks way faster with shortcuts than with a mouse, and it looks cool. I would start with Googling shortcuts for your IDE since you usually use this tool the most. From my practice, the most valuable commands are creating a new cell in a Notebook, running this cell, deleting it, and converting the cell into markdown.
If you have other tools that you use pretty often (such as Google Sheets or Slack), you can also learn commands for them.
The main trick with learning shortcuts is “practice, practice, practice” — you need to repeat it a hundred times to start doing it automatically. There are even plugins that push you to use shortcuts more (for example, this one from JetBrains).
Last but not least is CLI (command-line interface). It might look intimidating in the beginning, but basic knowledge of CLI usually pays off. I use CLI even to work with GitHub since it gives me a clear understanding of what’s going on exactly.
However, there are situations when it’s almost impossible to avoid using CLI, such as when working on a remote server. To interact confidently with a server, you need to learn less than ten commands. This article can help you gain basic knowledge about CLI.
Manage your environment
Continuing the topic of tools, setting up your environment is always a good idea. I have a Python virtual environment for day-to-day work with all the libraries I usually use.
Creating a new virtual environment is as easy as a couple of lines of code in your terminal (an excellent opportunity to start using CLI).
# creating venv
python -m venv routine_venv
# activating venv
source routine_venv/bin/activate
# installing ALL packages you need
pip install pandas plotly
# starting Juputer Notebooks
jupyter notebook
You can start your Jupyter from this environment or use it in your IDE.
It’s a good practice to have a separate environment for big projects. I usually do it only if I need an unusual stack (like PyTorch or yet another new LLM framework) or face some issues with library compatibility.
The other way to save your environment is by using Docker Containers. I use it for something more production-like, like web apps running on the server.
Think about program performance
To tell the truth, analysts often don’t need to think much about performance. When I got my first job in data analytics, my lead shared the practical approach to performance optimisations (and I have been using it ever since). When you’re thinking about performance, consider the total time vs efforts. Suppose I have a MapReduce script that runs for 4 hours. Should I optimise it? It depends.
- If I need to run it only once or twice, there’s not much sense in spending 1 hour to optimise this script to calculate numbers in just 1 hour.
- If I plan to run it daily, it’s worth the effort to make it faster and stop wasting computational resources (and money).
Since the majority of my tasks are one-time research, in most cases, I don’t need to optimise my code. However, it’s worth following some basic rules to avoid waiting for hours. Small tricks can lead to tremendous results. Let’s discuss such an example.
Starting from the basics, the cornerstone of performance is big O notation. Simply put, big O notation shows the relation between execution time and the number of elements you work with. So, if my program is O(n), it means that if I increase the amount of data 10 times, execution will be ~10 times longer.
When writing code, it’s worth understanding the complexity of your algorithm and the main data structures. For example, finding out if an element is in a list takes O(n) time, but it only takes O(1) time in a set. Let’s see how it can affect our code.
I have 2 data frames with Q1 and Q2 user transactions, and for each transaction in the Q1 data frame, I would like to understand whether this customer was retained or not. Our data frames are relatively small — around 300-400K rows.
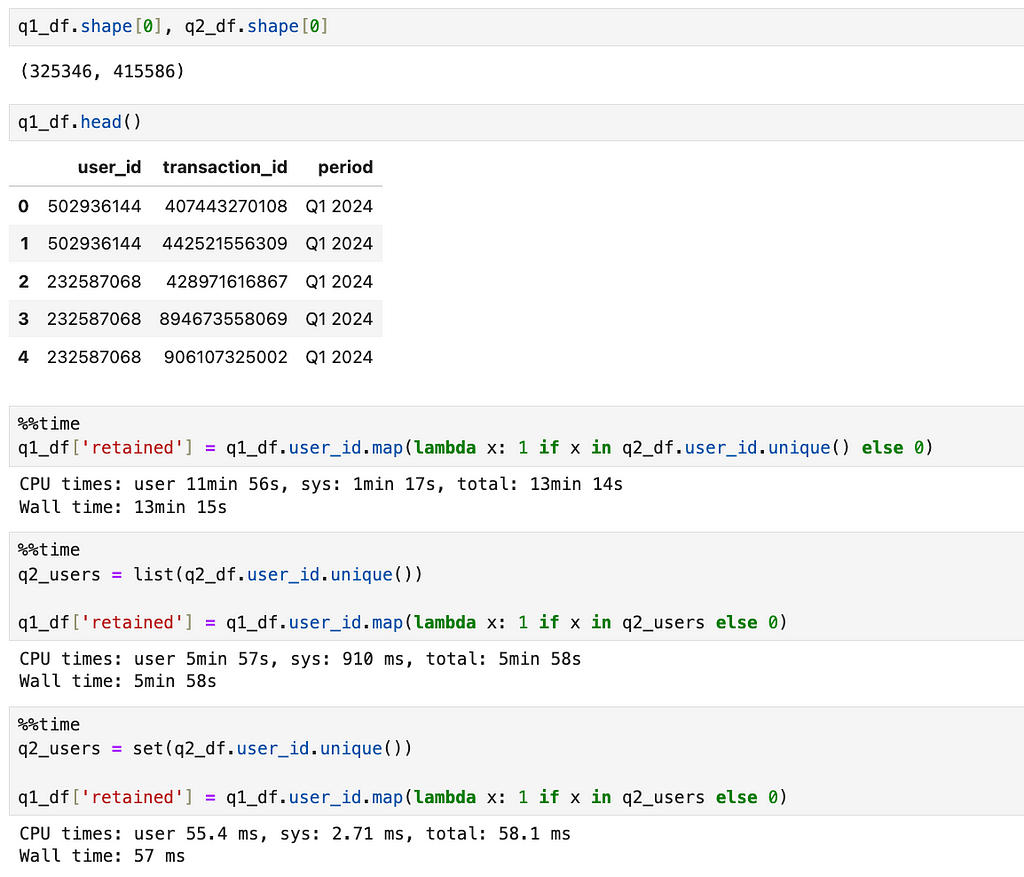
As you can see, performance differs a lot.
- The first approach is the worst one because, on each iteration (for each row in the Q1 dataset), we calculate the list of unique user_ids. Then, we look up the element in the list with O(n) complexity. This operation takes 13 minutes.
- The second approach, when we calculate the list first, is a bit better, but it still takes almost 6 minutes.
- If we pre-calculate a list of user_ids and convert it into the set, we will get the result in a blink of an eye.
As you can see, we can make our code more than 10K times faster with just basic knowledge. It’s a game-changer.
The other general advice is to avoid using plain Python and prefer to use more performant data structures, such as pandas or numpy. These libraries are faster because they use vectorised operations on arrays, which are implemented on C. Usually, numpy would show a bit better performance since pandas is built on top of numpy but has some additional functionality that slows it down a bit.
Don’t forget the DRY principle.
DRY stands for “Don’t Repeat Yourself” and is self-explanatory. This principle praises structured modular code that you can easily reuse.
If you’re copy-pasting a chunk of code for the third time, it’s a sign to think about the code structure and how to encapsulate this logic.
The standard analytical task is data wrangling, and we usually follow the procedural paradigm. So, the most apparent way to structure the code is functions. However, you might follow objective-oriented programming and create classes. In my previous article, I shared an example of the objective-oriented approach to simulations.
The benefits of modular code are better readability, faster development and easier changes. For example, if you want to change your visualisation from a line chart to an area plot, you can do it in one place and re-run your code.
If you have a bunch of functions related to one particular domain, you can create a Python package for it to interact with these functions as with any other Python library. Here’s a detailed guide on how to do it.
Leverage testing
The other topic that is, in my opinion, undervalued in the analytical world is testing. Software engineers often have KPIs on the test coverage, which might also be useful for analysts. However, in many cases, our tests will be related to the data rather than the code itself.
The trick I’ve learned from one of my colleagues is to add tests on the data recency. We have multiple scripts for quarterly and annual reports that we run pretty rarely. So, he added a check to see whether the latest rows in the tables we’re using are after the end of the reporting period (it shows whether the table has been updated). In Python, you can use an assert statement for this.
assert last_record_time >= datetime.date(2023, 5, 31)
If the condition is fulfilled, then nothing will happen. Otherwise, you will get an AssertionError . It’s a quick and easy check that can help you spot problems early.
The other thing I prefer to validate is sum statistics. For example, if you’re slicing, dicing and transforming your data, it’s worth checking that the overall number of requests and metrics stays the same. Some common mistakes are:
- duplicates that emerged because of joins,
- filtered-out None values when you’re using pandas.groupby function,
- filtered-out dimensions because of inner joins.
Also, I always check data for duplicates. If you expect that each row will represent one user, then the number of rows should be equal to df.user_id.nunique() . If it’s false, something is wrong with your data and needs investigation.
The trickiest and most helpful test is the sense check. Let’s discuss some possible approaches to it.
- First, I would check whether the results make sense overall. For example, if 1-month retention equals 99% or I got 1 billion customers in Europe, there’s likely a bug in the code.
- Secondly, I will look for other data sources or previous research on this topic to validate that my results are feasible.
- If you don’t have other similar research (for example, you’re estimating your potential revenue after launching the product in a new market), I would recommend you compare your numbers to those of other existing segments. For example, if your incremental effect on revenue after launching your product in yet another market equals 5x current income, I would say it’s a bit too optimistic and worth revisiting assumptions.
I hope this mindset will help you achieve more feasible results.
Encourage the team to use Version Control Systems
Engineers use version control systems even for the tiny projects they are working on their own. At the same time, I often see analysts using Google Sheets to store their queries. Since I’m a great proponent and advocate for keeping all the code in the repository, I can’t miss a chance to share my thoughts with you.
Why have I been using a repository for 10+ years of my data career? Here are the main benefits:
- Reproducibility. Quite often, we need to tweak the previous research (for example, add one more dimension or narrow research down to a specific segment) or just repeat the earlier calculations. If you store all the code in a structured way, you can quickly reproduce your prior work. It usually saves a lot of time.
- Transparency. Linking code to the results of your research allows your colleagues to understand the methodology to the tiniest detail, which brings more trust and naturally helps to spot bugs or potential improvements.
- Knowledge sharing. If you have a catalogue that is easy to navigate (or you link your code to Task Trackers), it makes it super-easy for your colleagues to find your code and not start an investigation from scratch.
- Rolling back. Have you ever been in a situation when your code was working yesterday, but then you changed something, and now it’s completely broken? I’ve been there many times before I started committing my code regularly. Version Control systems allow you to see the whole version history and compare the code or rollback to the previous working version.
- Collaboration. If you’re working on the code in collaboration with others, you can leverage version control systems to track and merge the changes.
I hope you can see its potential benefits now. Let me briefly share my usual setup to store code:
- I use git + Github as a version control system, I’m this dinosaur who is still using the command line interface for git (it gives me the soothing feeling of control), but you can use the GitHub app or the functionality of your IDE.
- Most of my work is research (code, numbers, charts, comments, etc.), so I store 95% of my code as Jupyter Notebooks.
- I link my code to the Jira tickets. I usually have a tasks folder in my repository and name subfolders as ticket keys (for example, ANALYTICS-42). Then, I place all the files related to the task in this subfolder. With such an approach, I can find code related to (almost) any task in seconds.
There are a bunch of nuances of working with Jupyter Notebooks in GitHub that are worth noting.
First, think about the output. When committing a Jupyter Notebook to the repository, you save input cells (your code or comments) and output. So, it’s worth being conscious about whether you actually want to share the output. It might contain PII or other sensitive data that I wouldn’t advise committing. Also, the output might be pretty big and non-informative, so it will just clutter your repository. When you’re saving 10+ MB Jupyter Notebook with some random data output, all your colleagues will load this data to their computers with the next git pull command.
Charts in output might be especially problematic. We all like excellent interactive Plotly charts. Unfortunately, they are not rendered on GitHub UI, so your colleagues likely won’t see them. To overcome this obstacle, you might switch the output type for Plotly to PNG or JPEG.
import plotly.io as pio
pio.renderers.default = "jpeg"
You can find more details about Plotly renderers in the documentation.
Last but not least, Jupyter Notebooks diffs are usually tricky. You would often like to understand the difference between 2 versions of the code. However, the default GitHub view won’t give you much helpful info because there is too much clutter due to changes in notebook metadata (like in the example below).
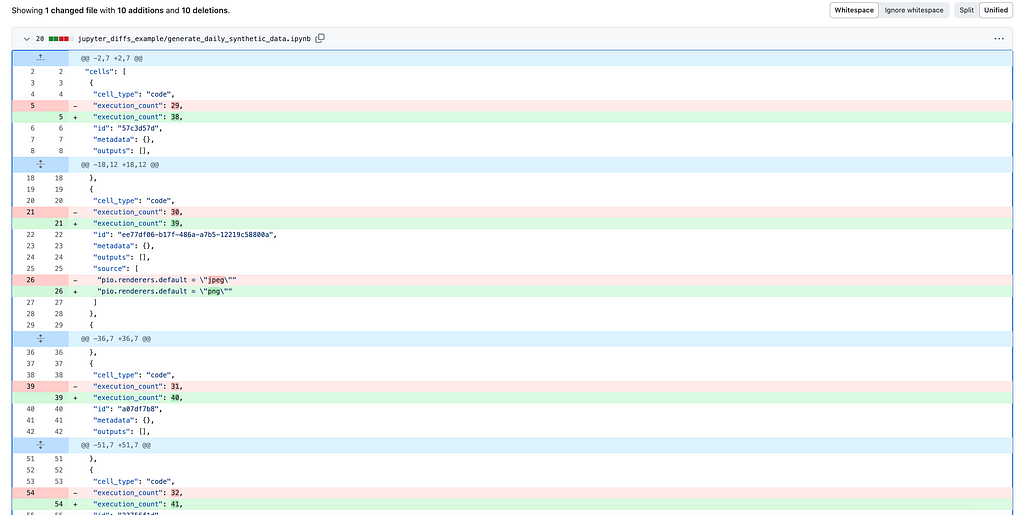
Actually, GitHub has almost solved this issue. A rich diffs functionality in feature preview can make your life way easier — you just need to switch it on in settings.
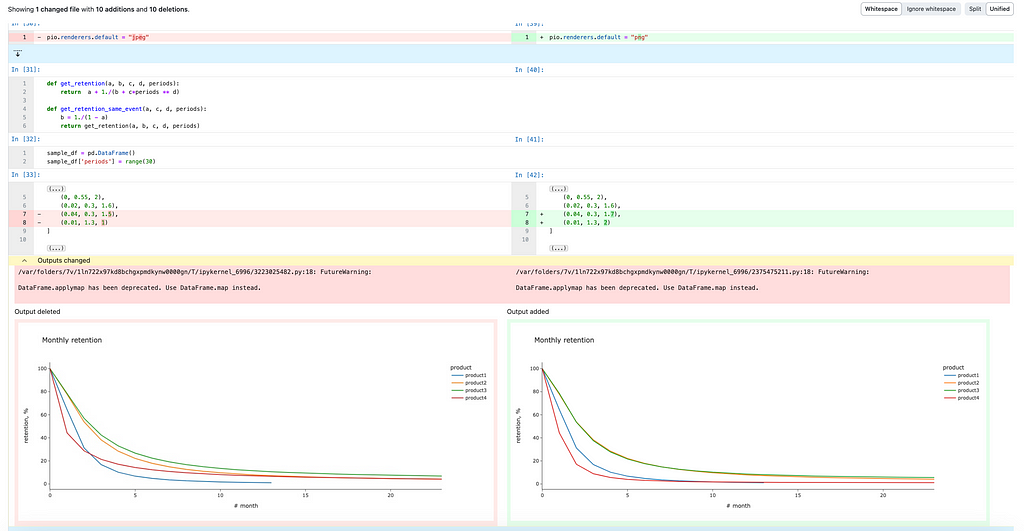
With this feature, we can easily see that there were just a couple of changes. I’ve changed the default renderer and parameters for retention curves (so a chart has been updated as well).
Ask for a code review
Engineers do peer reviews for (almost) all changes to the code. This process allows one to spot bugs early, stop bad actors or effectively share knowledge in the team.
Of course, it’s not a silver bullet: reviewers can miss bugs, or a bad actor might introduce a breach into the popular open-source project. For example, there was quite a scary story of how a backdoor was planted into a compression tool widely used in popular Linux distributions.
However, there is evidence that code review actually helps. McConnell shares the following stats in his iconic book “Code Complete”.
… software testing alone has limited effectiveness — the average defect detection rate is only 25 percent for unit testing, 35 percent for function testing, and 45 percent for integration testing. In contrast, the average effectiveness of design and code inspections are 55 and 60 percent.
Despite all these benefits, analysts often don’t use code review at all. I can understand why it might be challenging:
- Analytical teams are usually smaller, and spending limited resources on double-checking might not sound reasonable.
- Quite often, analysts work in different domains, and you might end up being the only person who knows this domain well enough to do a code review.
However, I really encourage you to do a code review, at least for critical things to mitigate risks. Here are the cases when I ask colleagues to double-check my code and assumptions:
- When I’m using data in a new domain, it’s always a good idea to ask an expert to review the assumptions used;
- All the tasks related to customer communications or interventions since errors in such data might lead to significant impact (for example, we’ve communicated wrong information to customers or deactivated wrong people);
- High-stakes decisions: if you plan to invest six months of the team’s effort into the project, it’s worth double- and triple-checking;
- When results are unexpected: the first hypothesis to test when I see surprising results is to check for an error in code.
Of course, it’s not an exhaustive list, but I hope you can see my reasoning and use common sense to define when to reach out for code review.
Stay up-to-date
The famous Lewis Caroll quote represents the current state of the tech domain quite well.
… it takes all the running you can do, to keep in the same place. If you want to get somewhere else, you must run at least twice as fast as that.
Our field is constantly evolving: new papers are published every day, libraries are updated, new tools emerge and so on. It’s the same story for software engineers, data analysts, data scientists, etc.
There are so many sources of information right now that there’s no problem to find it:
- weekly e-mails from Towards Data Science and some other subscriptions,
- following experts on LinkedIn and X (former Twitter),
- subscribing to e-mail updates for the tools and libraries I use,
- attending local meet-ups.
A bit more tricky is to avoid being drowned by all the information. I try to focus on one thing at a time to prevent too much distraction.
Summary
That’s it with the software engineering practices that can be helpful for analysts. Let me quickly recap them all here:
- Code is not for computers. It’s for people.
- Automate repetitive tasks.
- Master your tools.
- Manage your environment.
- Think about program performance.
- Don’t forget the DRY principle.
- Leverage testing.
- Encourage the team to use Version Control Systems.
- Ask for a code review.
- Stay up-to-date.
Data analytics combines skills from different domains, so I believe we can benefit greatly from learning the best practices of software engineers, product managers, designers, etc. By adopting the tried-and-true techniques of our colleagues, we can improve our effectiveness and efficiency. I highly encourage you to explore these adjacent domains as well.
Thank you a lot for reading this article. I hope this article was insightful for you. If you have any follow-up questions or comments, please leave them in the comments section.
Reference
All the images are produced by the author unless otherwise stated.
Acknowledgements
I can’t miss a chance to express my heartfelt thanks to my partner, who has been sharing his engineering wisdom with me for ages and has reviewed all my articles.
From Code to Insights: Software Engineering Best Practices for Data Analysts was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
Originally appeared here:
From Code to Insights: Software Engineering Best Practices for Data Analysts