

Under The Hood Of The Generative AI For Video By OpenAI
How can AI transform a static image into a dynamic, realistic video? OpenAI’s Sora introduces an answer through the innovative use of spacetime patches.
In the rapidly evolving landscape of generative models, OpenAI’s Sora stands out as a significant milestone, promising to reshape our understanding and capabilities in video generation. We unpack the technology behind Sora and its potential to inspire a new generation of models in image, video, and 3D content creation.
The demo above was generated by OpenAI using the prompt: A cat waking up its sleeping owner demanding breakfast. The owner tries to ignore the cat, but the cat tries new tactics and finally the owner pulls out a secret stash of treats from under the pillow to hold the cat off a little longer. — With Sora we verge onto near indistinguishable realism with video content generation. The full model is yet to be fully released to the public as its undergoing testing.
How Sora’s Unique Approach Transforms Video Generation
In the world of generative models we have seen a number of approaches from GAN’s to auto-regressive, and diffusion models, all with their own strengths and limitations. Sora now introduces a paradigm shift with a new modelling techniques and flexibility to handle a broad range of duration’s, aspect ratios, and resolutions.
Sora combines both diffusion and transformer architectures together to create a diffusion transformer model and is able to provide features such as:
- Text-to-video: As we have seen
- Image-to-video: Bringing life to still images
- Video-to-video: Changing the style of video to something else
- Extending video in time: Forwards and backwards
- Create seamless loops: Tiled videos that seem like they never end
- Image generation: Still image is a movie of one frame (up to 2048 x 2048)
- Generate video in any format: From 1920 x 1080 to 1080 x 1920 and everything in between
- Simulate virtual worlds: Like Minecraft and other video games
- Create a video: Up to 1 minute in length with multiple shorts
Imagine for one moment you’re in a kitchen. The traditional video generation models like those from Pika and RunwayML a like the cooks that follow recipes to the letter. They can produce excellent dishes (videos) but are limited by the recipes (algorithms) they know. The cooks might specialize in baking cakes (short clips) or cooking pasta (specific types of videos), using specific ingredients (data formats) and techniques (model architectures).
Sora, on the other hand, is a new kind of chef who understand the fundamentals of flavor. This chef doesn’t just follow recipes; they invent new ones. The flexibility of Sora’s ingredients (data) and techniques (model architecture) is what allow Sora to produce a wide range of high-quality videos, akin to a master chef’s versatile culinary creations.
The Core of Sora’s Secret Ingredient: Exploring the Spacetime Patches
Spacetime patches are at the heart of Sora’s innovation, built on the earlier research from Google DeepMind on NaViT and ViT (Vision Transformers) based on the 2021 paper An Image is Worth 16×16 Words.
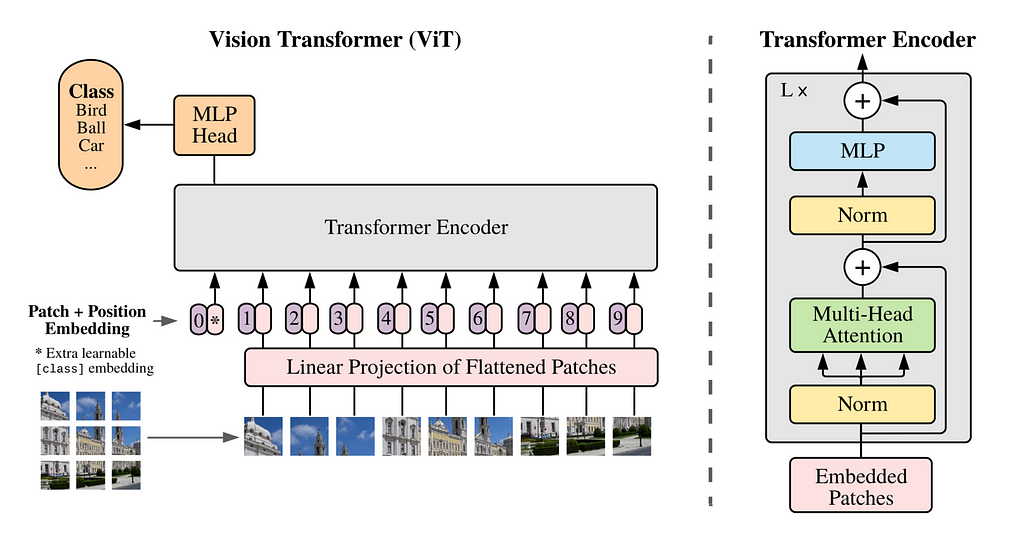
Traditionally with Vision Transformers we use a sequence of images “patches” to train a transformer model for image recognition instead of words for language transformers. The patches allow us to move away from convolutional neural networks for image processing.

However with vision transformers were constraint on image training data that was fixed in size and aspect ratio which limited the quality and required vast amounts of preprocessing of images.
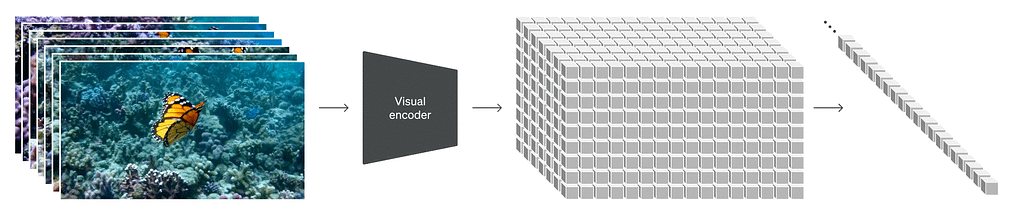
By treating videos as sequences of patches, Sora maintains the original aspect ratios and resolutions, similar to NaViT’s handling of images. This preservation is crucial for capturing the true essence of the visual data, enabling the model to learn from a more accurate representation of the world and thus giving Sora its near magical accuracy.
The method allows Sora to efficiently process a diverse array of visual data without the need for pre-processing steps like resizing or padding. This flexibility ensures that every piece of data contributes to the model’s understanding, much like how a chef uses a variety of ingredients to enhance a dish’s flavor profile.
The detailed and flexible handling of video data through spacetime patches lays the groundwork for sophisticated features such as accurate physics simulation and 3D consistency. These capabilities are essential for creating videos that not only look realistic but also adhere to the physical rules of the world, offering a glimpse into the potential for AI to create complex, dynamic visual content.
Feeding Sora: The Role of Diverse Data in Training
The quality and diversity of training data are crucial for the performance of generative models. Existing video models were traditionally trained on a more restrictive set of data, shorter lengths and narrow target.
Sora leverages a vast and varied dataset, including videos and images of different durations, resolutions, and aspect ratios. It’s ability to re-create digital worlds like Minecraft, its likely also included gameplay and simulated world footage from systems such as Unreal or Unity in its training set in order to capture all the angles and various styles of video content. This brings Sora to a “generalist” model just like GPT-4 for text.
This extensive training enables Sora to understand complex dynamics and generate content that is both diverse and high in quality. The approach mimics the way large language models are trained on diverse text data, applying a similar philosophy to visual content to achieve generalist capabilities.
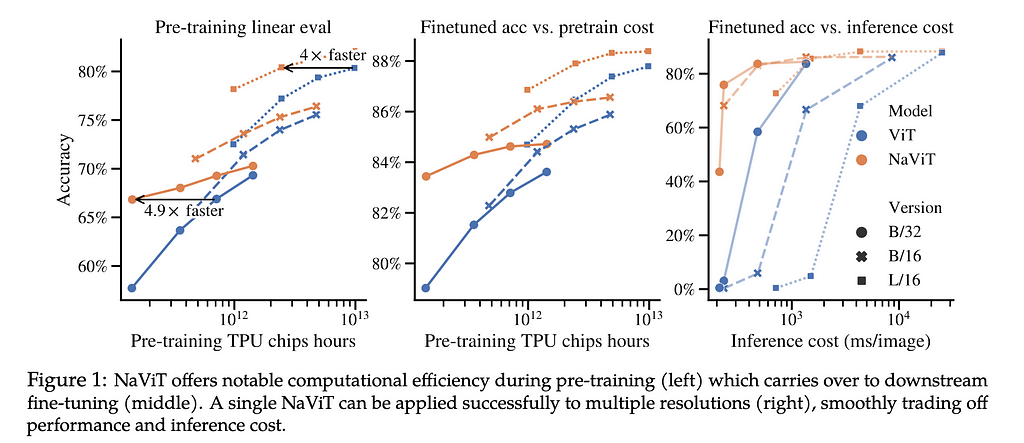
Just as the NaViT model demonstrates significant training efficiency and performance gains by packing multiple patches from different images into single sequences, Sora leverages spacetime patches to achieve similar efficiencies in video generation. This approach allows for more effective learning from a vast dataset, improving the model’s ability to generate high-fidelity videos yet lowering the compute required versus existing modeling architectures.
Bringing the Physical World to Life: Sora’s Mastery over 3D and Continuity
3D space and object permanence is one of the key standouts in the demo’s by Sora. Through its training on a wide range of video data without adapting or preprocessing the videos, Sora learns to model the physical world with impressive accuracy as its able to consume the training data in its original form.
It can generate digital worlds and videos where objects and characters move and interact in three-dimensional space convincingly, maintaining coherence even when they are occluded or leave the frame.
Looking Ahead: The Future Implications of Sora
Sora sets a new standard for what’s possible in generative models. This approach, much is likely to inspire the open-source community to experiment with and advance the capabilities in visual modalities, fueling a new generation of generative models that push the boundaries of creativity and realism.
The journey of Sora is just beginning, and as OpenAI put’s it “scaling video generation models is a promising path towards building general purpose simulators of the physical world”
Sora’s approach, blending the latest in AI research with practical applications, signals a bright future for generative models. As these technologies continue to evolve, they promise to redefine our interactions with digital content, making the creation of high-fidelity, dynamic videos more accessible and versatile.
Enjoyed This Story?
Vincent Koc is a highly accomplished, commercially-focused technologist and futurist with a wealth of experience focused in data-driven and digital disciplines.
Subscribe for free to get notified when Vincent publishes a new story. Or follow him on LinkedIn and X.
Get an email whenever Vincent Koc publishes.
Unless otherwise noted, all images are by the author
Explaining OpenAI Sora’s Spacetime Patches: The Key Ingredient was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
Originally appeared here:
Explaining OpenAI Sora’s Spacetime Patches: The Key Ingredient
Go Here to Read this Fast! Explaining OpenAI Sora’s Spacetime Patches: The Key Ingredient