

Results point to a promising approach
A potential application of LLMs that has attracted attention and investment is around their ability to generate SQL queries. Querying large databases with natural language unlocks several compelling use cases, from increasing data transparency to improving accessibility for non-technical users.
However, as with any AI-generated content, the question of evaluation is important. How can we determine if an LLM-generated SQL query is correct and produces the intended results? Our recent research dives into this question and explores the effectiveness of using LLM as a judge to evaluate SQL generation.
Summary of Findings
LLM as a judge shows initial promise in evaluating SQL generation, with F1 scores between 0.70 and 0.76 using OpenAI’s GPT-4 Turbo in this experiment. Including relevant schema information in the evaluation prompt can significantly reduce false positives. While challenges remain — including false negatives due to incorrect schema interpretation or assumptions about data — LLM as a judge provides a solid proxy for AI SQL generation performance, especially as a quick check on results.
Methodology and Results
This study builds upon previous work done by the Defog.ai team, who developed an approach to evaluate SQL queries using golden datasets and queries. The process involves using a golden dataset question for AI SQL generation, generating test results “x” from the AI-generated SQL, using a pre-existing golden query on the same dataset to produce results “y,” and then comparing results “x” and “y” for accuracy.
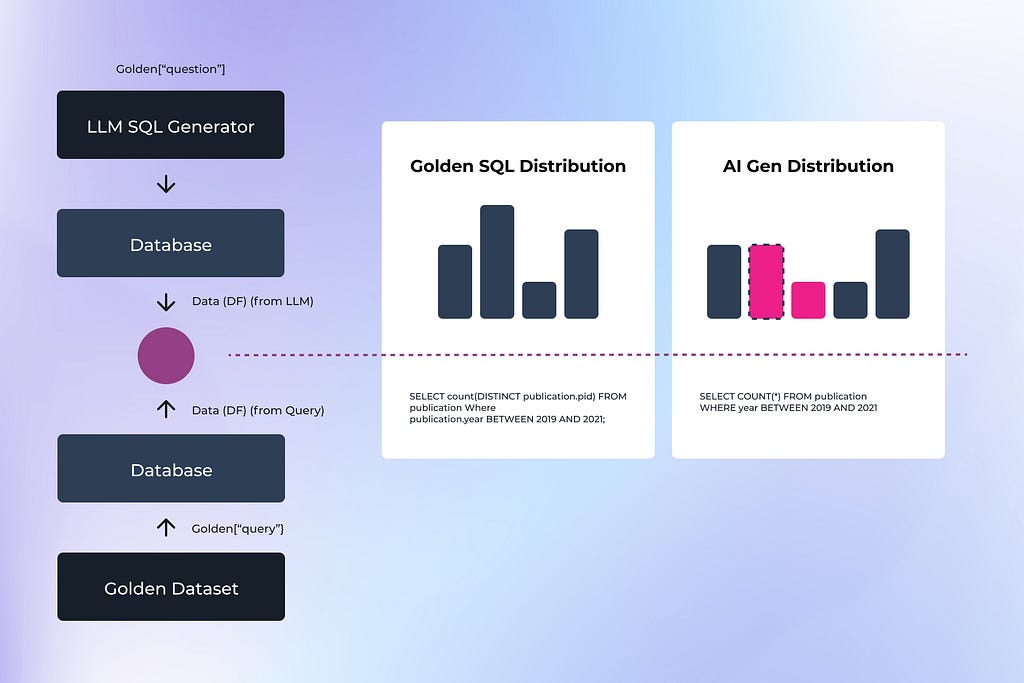
For this comparison, we first explored traditional methods of SQL evaluation, such as exact data matching. This approach involves a direct comparison of the output data from the two queries. For instance, when evaluating a query about author citations, any differences in the number of authors or their citation counts would result in a mismatch and failure. While straightforward, this method does not handle edge cases, such as how to handle zero-count bins or slight variations in numeric outputs.

We then tried a more nuanced approach: using an LLM-as-a-judge. Our initial tests with this method, using OpenAI’s GPT-4 Turbo without including database schema information in the evaluation prompt, yielded promising results with F1 scores between 0.70 and 0.76. In this setup, the LLM judged the generated SQL by examining only the question and the resulting query.

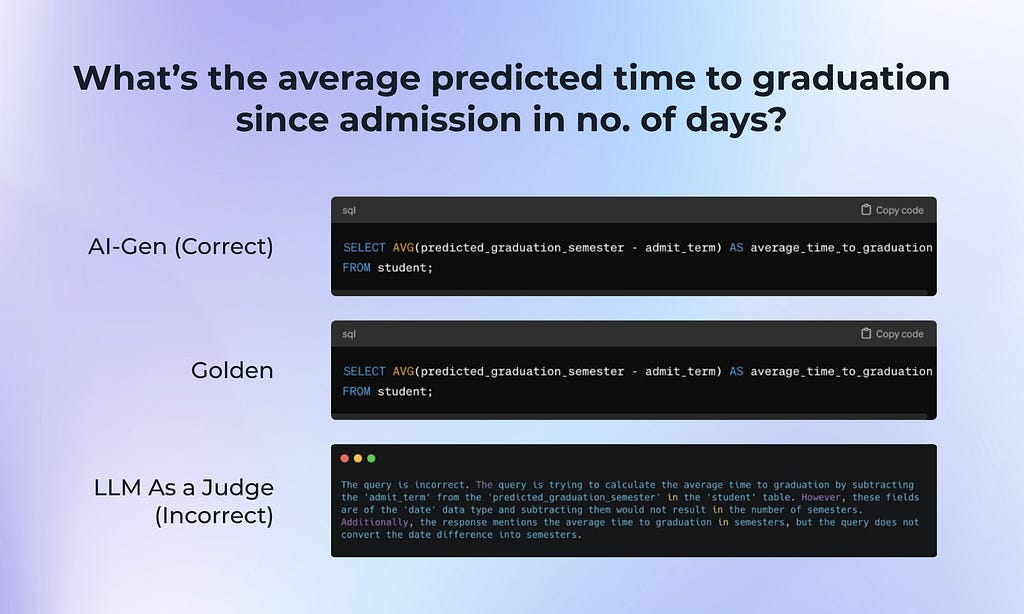
In this test we noticed that there were quite a few false positives and negatives, many of them related to mistakes or assumptions about the database schema. In this false negative case, the LLM assumed that the response would be in a different unit than expected (semesters versus days).
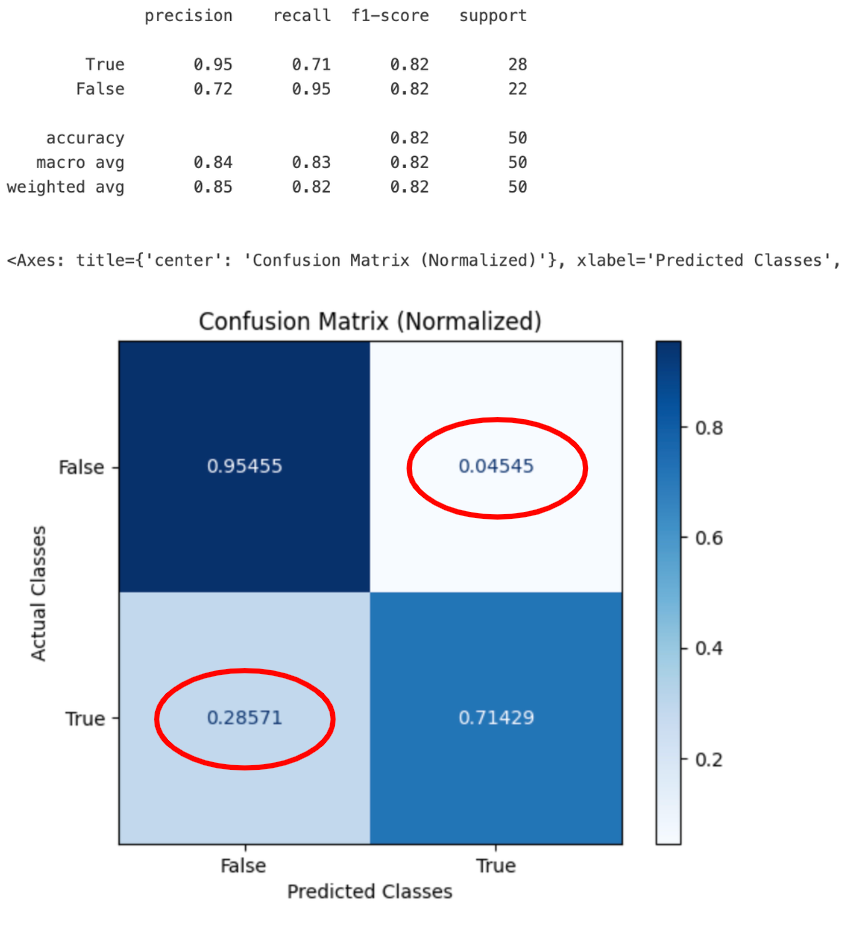
These discrepancies led us to add the database schema into the evaluation prompt. Contrary to our expectations, this resulted in worse performance. However, when we refined our approach to include only the schema for tables referenced in the queries, we saw significant improvement in both the false positive and negative rates.
Challenges and Future Directions
While the potential of using LLMs to evaluate SQL generation is clear, challenges remain. Often, LLMs make incorrect assumptions about data structures and relationships or incorrectly assume units of measurement or data formats. Finding the right amount and type of schema information to include in the evaluation prompt is important for optimizing performance.
Anyone exploring a SQL generation use case might explore several other areas like optimizing the inclusion of schema information, improving LLMs’ understanding of database concepts, and developing hybrid evaluation methods that combine LLM judgment with traditional techniques.
Conclusion
With the ability to catch nuanced errors, LLM as a judge shows promise as a quick and effective tool for assessing AI-generated SQL queries.
Carefully selecting what information is provided to the LLM judge helps in getting the most out of this method; by including relevant schema details and continually refining the evaluation process, we can improve the accuracy and reliability of SQL generation assessment.
As natural language interfaces to databases increase in popularity, the need for effective evaluation methods will only grow. The LLM as a judge approach, while not perfect, provides a more nuanced evaluation than simple data matching, capable of understanding context and intent in a way that traditional methods cannot.
A special shoutout to Manas Singh for collaborating with us on this research!
Evaluating SQL Generation with LLM as a Judge was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
Originally appeared here:
Evaluating SQL Generation with LLM as a Judge
Go Here to Read this Fast! Evaluating SQL Generation with LLM as a Judge