

How data drift and concept drift matter to choose the right retraining strategy?
Introduction
Many people in the field of MLOps have probably heard a story like this:
Company A embarked on an ambitious quest to harness the power of machine learning. It was a journey fraught with challenges, as the team struggled to pinpoint a topic that would not only leverage the prowess of machine learning but also deliver tangible business value. After many brainstorming sessions, they finally settled on a use case that promised to revolutionize their operations. With excitement, they contracted Company B, a reputed expert, to build and deploy a ML model. Following months of rigorous development and testing, the model passed all acceptance criteria, marking a significant milestone for Company A, who looked forward to future opportunities.
However, as time passed, the model began producing unexpected results, rendering it ineffective for its intended use. Company A reached out to Company B for advice, only to learn that the changed circumstances required building a new model, necessitating an even higher investment as the original.
What went wrong? Was the model Company B created not as good as expected? Was Company A just unlucky that something unexpected happened?
Probably the issue was that even the most rigorous testing of a model before deployment does not guarantee that this model will perform well for an unlimited amount of time. The two most important aspects that impact a model’s performance over time are data drift and concept drift.
Data Drift: Also known as covariate shift, this occurs when the statistical properties of the input data change over time. If an ML model was trained on data from a specific demographic but the demographic characteristics of the input data change, the model’s performance can degrade. Imagine you taught a child multiplication tables until 10. It can quickly give you the correct answers for what is 3 * 7 or 4 * 9. However, one time you ask what is 4 * 13, and although the rules of multiplication did not change it may give you the wrong answer because it did not memorize the solution.
Concept Drift: This happens when the relationship between the input data and the target variable changes. This can lead to a degradation in model performance as the model’s predictions no longer align with the evolving data patterns. An example here could be spelling reforms. When you were a child, you may have learned to write “co-operate”, however now it is written as “cooperate”. Although you mean the same word, your output of writing that word has changed over time.
In this article I investigate how different scenarios of data drift and concept drift impact a model’s performance over time. Furthermore, I show what retraining strategies can mitigate performance degradation.
I focus on evaluating retraining strategies with respect to the model’s prediction performance. In practice more aspects like:
- Data Availability and Quality: Ensure that sufficient and high-quality data is available for retraining the model.
- Computational Costs: Evaluate the computational resources required for retraining, including hardware and processing time.
- Business Impact: Consider the potential impact on business operations and outcomes when choosing a retraining strategy.
- Regulatory Compliance: Ensure that the retraining strategy complies with any relevant regulations and standards, e.g. anti-discrimination.
need to be considered to identify a suitable retraining strategy.
Data Synthetization

To highlight the differences between data drift and concept drift I synthesized datasets where I controlled to what extent these aspects appear.
I generated datasets in 100 steps where I changed parameters incrementally to simulate the evolution of the dataset. Each step contains multiple data points and can be interpreted as the amount of data that was collected over an hour, a day or a week. After every step the model was re-evaluated and could be retrained.
To create the datasets, I first randomly sampled features from a normal distribution where mean µ and standard deviation σ depend on the step number s:

The data drift of feature xi depends on how much µi and σi are changing with respect to the step number s.
All features are aggregated as follows:

Where ci are coefficients that describe the impact of feature xi on X. Concept drift can be controlled by changing these coefficients with respect to s. A random number ε which is not available for model training is added to consider that the features do not contain complete information to predict the target y.
The target variable y is calculated by inputting X into a non-linear function. By doing this we create a more challenging task for the ML model since there is no linear relation between the features and the target. For the scenarios in this article, I chose a sine function.
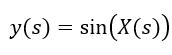
Scenario Analysis

I created the following scenarios to analyze:
- Steady State: simulating no data or concept drift — parameters µ, σ, and c were independent of step s
- Distribution Drift: simulating data drift — parameters µ, σ were linear functions of s, parameters c is independent of s
- Coefficient Drift: simulating concept drift: parameters µ, σ were independent of s, parameters c are a linear function of s
- Black Swan: simulating an unexpected and sudden change — parameters µ, σ, and c were independent of step s except for one step when these parameters were changed
The COVID-19 pandemic serves as a quintessential example of a Black Swan event. A Black Swan is characterized by its extreme rarity and unexpectedness. COVID-19 could not have been predicted to mitigate its effects beforehand. Many deployed ML models suddenly produced unexpected results and had to be retrained after the outbreak.
For each scenario I used the first 20 steps as training data of the initial model. For the remaining steps I evaluated three retraining strategies:
- None: No retraining — the model trained on the training data was used for all remaining steps.
- All Data: All previous data was used to train a new model, e.g. the model evaluated at step 30 was trained on the data from step 0 to 29.
- Window: A fixed window size was used to select the training data, e.g. for a window size of 10 the training data at step 30 contained step 20 to 29.
I used a XG Boost regression model and mean squared error (MSE) as evaluation metric.
Steady State

The diagram above shows the evaluation results of the steady state scenario. As the first 20 steps were used to train the models the evaluation error was much lower than at later steps. The performance of the None and Window retraining strategies remained at a similar level throughout the scenario. The All Data strategy slightly reduced the prediction error at higher step numbers.
In this case All Data is the best strategy because it profits from an increasing amount of training data while the models of the other strategies were trained on a constant training data size.
Distribution Drift (Data Drift)

When the input data distributions changed, we can clearly see that the prediction error continuously increased if the model was not retrained on the latest data. Retraining on all data or on a data window resulted in very similar performances. The reason for this is that although All Data was using more data, older data was not relevant for predicting the most recent data.
Coefficient Drift (Concept Drift)
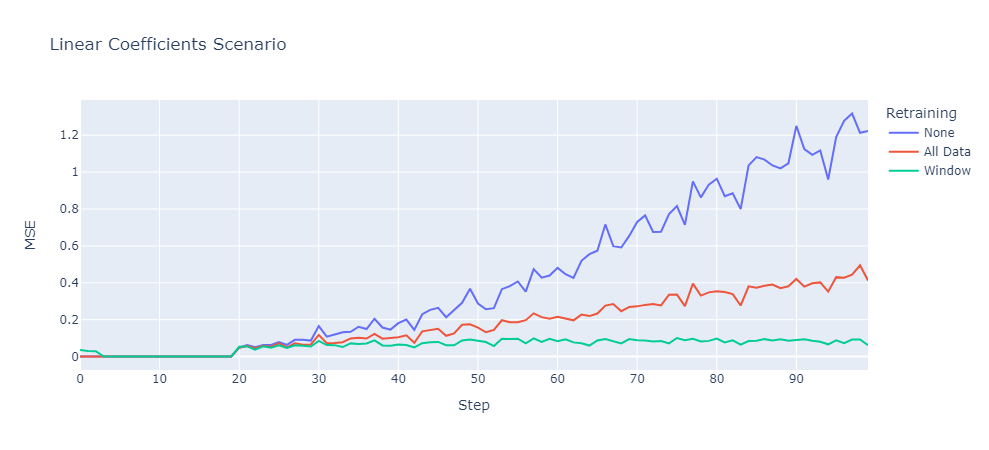
Changing coefficients means that the importance of features changes over time. In this case we can see that the None retraining strategy had drastic increase of the prediction error. Additionally, the results showed that retraining on all data also lead to a continuous increase of prediction error while the Window retraining strategy kept the prediction error on a constant level.
The reason why the All Data strategy performance also decreased over time was that the training data contained more and more cases where similar inputs resulted in different outputs. Hence, it became more challenging for the model to identify clear patterns to derive decision rules. This was less of a problem for the Window strategy since older data was ignore which allowed the model to “forget” older patterns and focus on most recent cases.
Black Swan
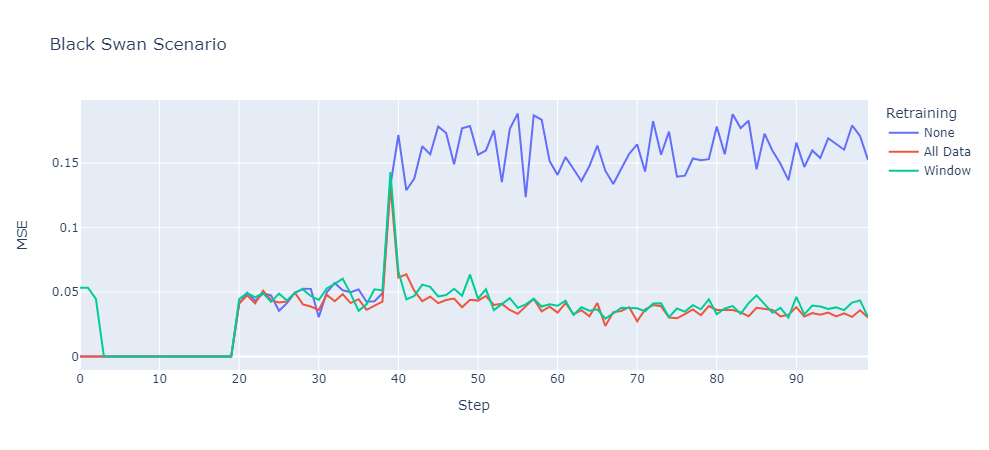
The black swan event occurred at step 39, the errors of all models suddenly increased at this point. However, after retraining a new model on the latest data, the errors of the All Data and Window strategy recovered to the previous level. Which is not the case with the None retraining strategy, here the error increased around 3-fold compared to before the black swan event and remained on that level until the end of the scenario.
In contrast to the previous scenarios, the black swan event contained both: data drift and concept drift. It is remarkable that the All Data and Window strategy recovered in the same way after the black swan event while we found a significant difference between these strategies in the concept drift scenario. Probably the reason for this is that data drift occurred at the same time as concept drift. Hence, patterns that have been learned on older data were not relevant anymore after the black swan event because the input data has shifted.
An example for this could be that you are a translator and you get requests to translate a language that you haven’t translated before (data drift). At the same time there was a comprehensive spelling reform of this language (concept drift). While translators who translated this language for many years may be struggling with applying the reform it wouldn’t affect you because you even didn’t know the rules before the reform.
To reproduce this analysis or explore further you can check out my git repository.
Conclusion
Identifying, quantifying, and mitigating the impact of data drift and concept drift is a challenging topic. In this article I analyzed simple scenarios to present basic characteristics of these concepts. More comprehensive analyses will undoubtedly provide deeper and more detailed conclusions on this topic.
Here is what I learned from this project:
Mitigating concept drift is more challenging than data drift. While data drift could be handled by basic retraining strategies concept drift requires a more careful selection of training data. Ironically, cases where data drift and concept drift occur at the same time may be easier to handle than pure concept drift cases.
A comprehensive analysis of the training data would be the ideal starting point of finding an appropriate retraining strategy. Thereby, it is essential to partition the training data with respect to the time when it was recorded. To make the most realistic assessment of the model’s performance, the latest data should only be used as test data. To make an initial assessment regarding data drift and concept drift the remaining training data can be split into two equally sized sets with the older data in one set and the newer data in the other. Comparing feature distributions of these sets allows to assess data drift. Training one model on each set and comparing the change of feature importance would allow to make an initial assessment on concept drift.
No retraining turned out to be the worst option in all scenarios. Furthermore, in cases where model retraining is not taken into consideration it is also more likely that data to evaluate and/or retrain the model is not collected in an automated way. This means that model performance degradation may be unrecognized or only be noticed at a late stage. Once developers become aware that there is a potential issue with the model precious time would be lost until new data is collected that can be used to retrain the model.
Identifying the perfect retraining strategy at an early stage is very difficult and may be even impossible if there are unexpected changes in the serving data. Hence, I think a reasonable approach is to start with a retraining strategy that performed well on the partitioned training data. This strategy should be reviewed and updated the time when cases occurred where it did not address changes in the optimal way. Continuous model monitoring is essential to quickly notice and react when the model performance decreases.
If not otherwise stated all images were created by the author.
Evaluating Model Retraining Strategies was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
Originally appeared here:
Evaluating Model Retraining Strategies
Go Here to Read this Fast! Evaluating Model Retraining Strategies