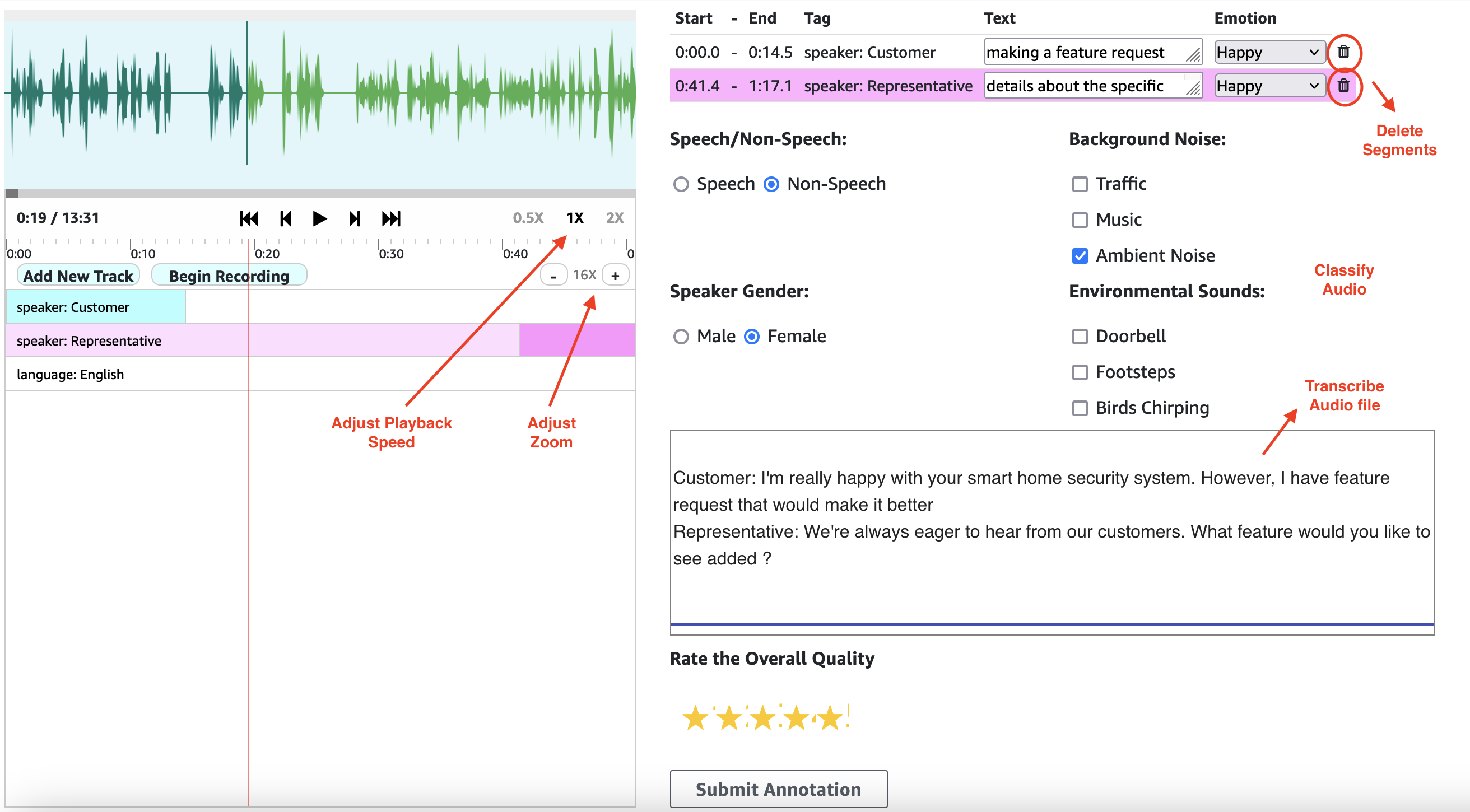

In this post, we show you how to implement an audio and video segmentation solution using SageMaker Ground Truth. We guide you through deploying the necessary infrastructure using AWS CloudFormation, creating an internal labeling workforce, and setting up your first labeling job. By the end of this post, you will have a fully functional audio/video segmentation workflow that you can adapt for various use cases, from training speech synthesis models to improving video generation capabilities.
Originally appeared here:
Enhance speech synthesis and video generation models with RLHF using audio and video segmentation in Amazon SageMaker