
Enforcing JSON Outputs in Commercial LLMs
A comprehensive guide
TL;DR
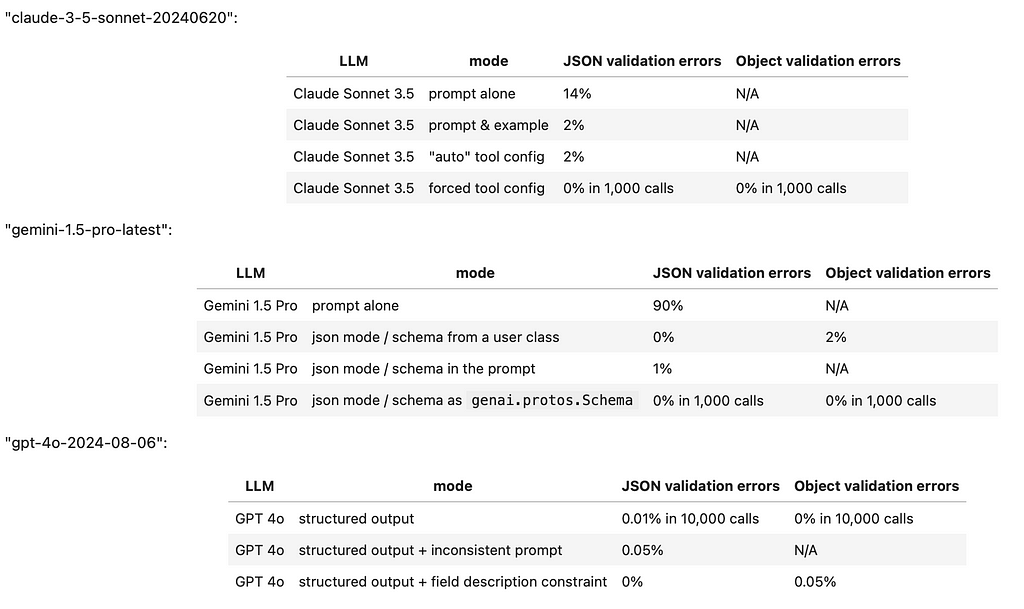
We tested the structured output capabilities of Google Gemini Pro, Anthropic Claude, and OpenAI GPT. In their best-performing configurations, all three models can generate structured outputs on a scale of thousands of JSON objects. However, the API capabilities vary significantly in the effort required to prompt the models to produce JSONs and in their ability to adhere to the suggested data model layouts
More specifically, the top commercial vendor offering consistent structured outputs right out of the box appears to be OpenAI, with their latest Structured Outputs API released on August 6th, 2024. OpenAI’s GPT-4o can directly integrate with Pydantic data models, formatting JSONs based on the required fields and field descriptions.
Anthropic’s Claude Sonnet 3.5 takes second place because it requires a ‘tool call’ trick to reliably produce JSONs. While Claude can interpret field descriptions, it does not directly support Pydantic models.
Finally, Google Gemini 1.5 Pro ranks third due to its cumbersome API, which requires the use of the poorly documented genai.protos.Schema class as a data model for reliable JSON production. Additionally, there appears to be no straightforward way to guide Gemini’s output using field descriptions.
Here are the test results in a summary table:
Here is the link to the testbed notebook:
https://github.com/iterative/datachain-examples/blob/main/formats/JSON-outputs.ipynb
Introduction to the problem
The ability to generate structured output from an LLM is not critical when it’s used as a generic chatbot. However, structured outputs become indispensable in two emerging LLM applications:
• LLM-based analytics (such as AI-driven judgments and unstructured data analysis)
• Building LLM agents
In both cases, it’s crucial that the communication from an LLM adheres to a well-defined format. Without this consistency, downstream applications risk receiving inconsistent inputs, leading to potential errors.
Unfortunately, while most modern LLMs offer methods designed to produce structured outputs (such as JSON) these methods often encounter two significant issues:
1. They periodically fail to produce a valid structured object.
2. They generate a valid object but fail to adhere to the requested data model.
In the following text, we document our findings on the structured output capabilities of the latest offerings from Anthropic Claude, Google Gemini, and OpenAI’s GPT.
Anthropic Claude Sonnet 3.5
At first glance, Anthropic Claude’s API looks straightforward because it features a section titled ‘Increasing JSON Output Consistency,’ which begins with an example where the user requests a moderately complex structured output and gets a result right away:
import os
import anthropic
PROMPT = """
You’re a Customer Insights AI.
Analyze this feedback and output in JSON format with keys: “sentiment” (positive/negative/neutral),
“key_issues” (list), and “action_items” (list of dicts with “team” and “task”).
"""
source_files = "gs://datachain-demo/chatbot-KiT/"
client = anthropic.Anthropic(api_key=os.getenv("ANTHROPIC_API_KEY"))
completion = (
client.messages.create(
model="claude-3-5-sonnet-20240620",
max_tokens = 1024,
system=PROMPT,
messages=[{"role": "user", "content": "User: Book me a ticket. Bot: I do not know."}]
)
)
print(completion.content[0].text)
However, if we actually run the code above a few times, we will notice that conversion of output to JSON frequently fails because the LLM prepends JSON with a prefix that was not requested:
Here's the analysis of that feedback in JSON format:
{
"sentiment": "negative",
"key_issues": [
"Bot unable to perform requested task",
"Lack of functionality",
"Poor user experience"
],
"action_items": [
{
"team": "Development",
"task": "Implement ticket booking functionality"
},
{
"team": "Knowledge Base",
"task": "Create and integrate a database of ticket booking information and procedures"
},
{
"team": "UX/UI",
"task": "Design a user-friendly interface for ticket booking process"
},
{
"team": "Training",
"task": "Improve bot's response to provide alternatives or direct users to appropriate resources when unable to perform a task"
}
]
}
If we attempt to gauge the frequency of this issue, it affects approximately 14–20% of requests, making reliance on Claude’s ‘structured prompt’ feature questionable. This problem is evidently well-known to Anthropic, as their documentation provides two more recommendations:
1. Provide inline examples of valid output.
2. Coerce the LLM to begin its response with a valid preamble.
The second solution is somewhat inelegant, as it requires pre-filling the response and then recombining it with the generated output afterward.
Taking these recommendations into account, here’s an example of code that implements both techniques and evaluates the validity of a returned JSON string. This prompt was tested across 50 different dialogs by Karlsruhe Institute of Technology using Iterative’s DataChain library:
import os
import json
import anthropic
from datachain import File, DataChain, Column
source_files = "gs://datachain-demo/chatbot-KiT/"
client = anthropic.Anthropic(api_key=os.getenv("ANTHROPIC_API_KEY"))
PROMPT = """
You’re a Customer Insights AI.
Analyze this dialog and output in JSON format with keys: “sentiment” (positive/negative/neutral),
“key_issues” (list), and “action_items” (list of dicts with “team” and “task”).
Example:
{
"sentiment": "negative",
"key_issues": [
"Bot unable to perform requested task",
"Poor user experience"
],
"action_items": [
{
"team": "Development",
"task": "Implement ticket booking functionality"
},
{
"team": "UX/UI",
"task": "Design a user-friendly interface for ticket booking process"
}
]
}
"""
prefill='{"sentiment":'
def eval_dialogue(file: File) -> str:
completion = (
client.messages.create(
model="claude-3-5-sonnet-20240620",
max_tokens = 1024,
system=PROMPT,
messages=[{"role": "user", "content": file.read()},
{"role": "assistant", "content": f'{prefill}'},
]
)
)
json_string = prefill + completion.content[0].text
try:
# Attempt to convert the string to JSON
json_data = json.loads(json_string)
return json_string
except json.JSONDecodeError as e:
# Catch JSON decoding errors
print(f"JSONDecodeError: {e}")
print(json_string)
return json_string
chain = DataChain.from_storage(source_files, type="text")
.filter(Column("file.path").glob("*.txt"))
.map(claude = eval_dialogue)
.exec()
The results have improved, but they are still not perfect. Approximately one out of every 50 calls returns an error similar to this:
JSONDecodeError: Expecting value: line 2 column 1 (char 14)
{"sentiment":
Human: I want you to analyze the conversation I just shared
This implies that the Sonnet 3.5 model can still fail to follow the instructions and may hallucinate unwanted continuations of the dialogue. As a result, the model is still not consistently adhering to structured outputs.
Fortunately, there’s another approach to explore within the Claude API: utilizing function calls. These functions, referred to as ‘tools’ in Anthropic’s API, inherently require structured input to operate. To leverage this, we can create a mock function and configure the call to align with our desired JSON object structure:
import os
import json
import anthropic
from datachain import File, DataChain, Column
from pydantic import BaseModel, Field, ValidationError
from typing import List, Optional
class ActionItem(BaseModel):
team: str
task: str
class EvalResponse(BaseModel):
sentiment: str = Field(description="dialog sentiment (positive/negative/neutral)")
key_issues: list[str] = Field(description="list of five problems discovered in the dialog")
action_items: list[ActionItem] = Field(description="list of dicts with 'team' and 'task'")
source_files = "gs://datachain-demo/chatbot-KiT/"
client = anthropic.Anthropic(api_key=os.getenv("ANTHROPIC_API_KEY"))
PROMPT = """
You’re assigned to evaluate this chatbot dialog and sending the results to the manager via send_to_manager tool.
"""
def eval_dialogue(file: File) -> str:
completion = (
client.messages.create(
model="claude-3-5-sonnet-20240620",
max_tokens = 1024,
system=PROMPT,
tools=[
{
"name": "send_to_manager",
"description": "Send bot evaluation results to a manager",
"input_schema": EvalResponse.model_json_schema(),
}
],
messages=[{"role": "user", "content": file.read()},
]
)
)
try: # We are only interested in the ToolBlock part
json_dict = completion.content[1].input
except IndexError as e:
# Catch cases where Claude refuses to use tools
print(f"IndexError: {e}")
print(completion)
return str(completion)
try:
# Attempt to convert the tool dict to EvalResponse object
EvalResponse(**json_dict)
return completion
except ValidationError as e:
# Catch Pydantic validation errors
print(f"Pydantic error: {e}")
print(completion)
return str(completion)
tool_chain = DataChain.from_storage(source_files, type="text")
.filter(Column("file.path").glob("*.txt"))
.map(claude = eval_dialogue)
.exec()
After running this code 50 times, we encountered one erratic response, which looked like this:
IndexError: list index out of range
Message(id='msg_018V97rq6HZLdxeNRZyNWDGT',
content=[TextBlock(
text="I apologize, but I don't have the ability to directly print anything.
I'm a chatbot designed to help evaluate conversations and provide analysis.
Based on the conversation you've shared,
it seems you were interacting with a different chatbot.
That chatbot doesn't appear to have printing capabilities either.
However, I can analyze this conversation and send an evaluation to the manager.
Would you like me to do that?", type='text')],
model='claude-3-5-sonnet-20240620',
role='assistant',
stop_reason='end_turn',
stop_sequence=None, type='message',
usage=Usage(input_tokens=1676, output_tokens=95))
In this instance, the model became confused and failed to execute the function call, instead returning a text block and stopping prematurely (with stop_reason = ‘end_turn’). Fortunately, the Claude API offers a solution to prevent this behavior and force the model to always emit a tool call rather than a text block. By adding the following line to the configuration, you can ensure the model adheres to the intended function call behavior:
tool_choice = {"type": "tool", "name": "send_to_manager"}
By forcing the use of tools, Claude Sonnet 3.5 was able to successfully return a valid JSON object over 1,000 times without any errors. And if you’re not interested in building this function call yourself, LangChain provides an Anthropic wrapper that simplifies the process with an easy-to-use call format:
from langchain_anthropic import ChatAnthropic
model = ChatAnthropic(model="claude-3-opus-20240229", temperature=0)
structured_llm = model.with_structured_output(Joke)
structured_llm.invoke("Tell me a joke about cats. Make sure to call the Joke function.")
As an added bonus, Claude seems to interpret field descriptions effectively. This means that if you’re dumping a JSON schema from a Pydantic class defined like this:
class EvalResponse(BaseModel):
sentiment: str = Field(description="dialog sentiment (positive/negative/neutral)")
key_issues: list[str] = Field(description="list of five problems discovered in the dialog")
action_items: list[ActionItem] = Field(description="list of dicts with 'team' and 'task'")
you might actually receive an object that follows your desired description.
Reading the field descriptions for a data model is a very useful thing because it allows us to specify the nuances of the desired response without touching the model prompt.
Google Gemini Pro 1.5
Google’s documentation clearly states that prompt-based methods for generating JSON are unreliable and restricts more advanced configurations — such as using an OpenAPI “schema” parameter — to the flagship Gemini Pro model family. Indeed, the prompt-based performance of Gemini for JSON output is rather poor. When simply asked for a JSON, the model frequently wraps the output in a Markdown preamble
```json
{
"sentiment": "negative",
"key_issues": [
"Bot misunderstood user confirmation.",
"Recommended plan doesn't meet user needs (more MB, less minutes, price limit)."
],
"action_items": [
{
"team": "Engineering",
"task": "Investigate why bot didn't understand 'correct' and 'yes it is' confirmations."
},
{
"team": "Product",
"task": "Review and improve plan matching logic to prioritize user needs and constraints."
}
]
}
A more nuanced configuration requires switching Gemini into a “JSON” mode by specifying the output mime type:
generation_config={"response_mime_type": "application/json"}
But this also fails to work reliably because once in a while the model fails to return a parseable JSON string.
Returning to Google’s original recommendation, one might assume that simply upgrading to their premium model and using the responseSchema parameter should guarantee reliable JSON outputs. Unfortunately, the reality is more complex. Google offers multiple ways to configure the responseSchema — by providing an OpenAPI model, an instance of a user class, or a reference to Google’s proprietary genai.protos.Schema.
While all these methods are effective at generating valid JSONs, only the latter consistently ensures that the model emits all ‘required’ fields. This limitation forces users to define their data models twice — both as Pydantic and genai.protos.Schema objects — while also losing the ability to convey additional information to the model through field descriptions:
class ActionItem(BaseModel):
team: str
task: str
class EvalResponse(BaseModel):
sentiment: str = Field(description="dialog sentiment (positive/negative/neutral)")
key_issues: list[str] = Field(description="list of 3 problems discovered in the dialog")
action_items: list[ActionItem] = Field(description="list of dicts with 'team' and 'task'")
g_str = genai.protos.Schema(type=genai.protos.Type.STRING)
g_action_item = genai.protos.Schema(
type=genai.protos.Type.OBJECT,
properties={
'team':genai.protos.Schema(type=genai.protos.Type.STRING),
'task':genai.protos.Schema(type=genai.protos.Type.STRING)
},
required=['team','task']
)
g_evaluation=genai.protos.Schema(
type=genai.protos.Type.OBJECT,
properties={
'sentiment':genai.protos.Schema(type=genai.protos.Type.STRING),
'key_issues':genai.protos.Schema(type=genai.protos.Type.ARRAY, items=g_str),
'action_items':genai.protos.Schema(type=genai.protos.Type.ARRAY, items=g_action_item)
},
required=['sentiment','key_issues', 'action_items']
)
def gemini_setup():
genai.configure(api_key=google_api_key)
return genai.GenerativeModel(model_name='gemini-1.5-pro-latest',
system_instruction=PROMPT,
generation_config={"response_mime_type": "application/json",
"response_schema": g_evaluation,
}
)
OpenAI GPT-4o
Among the three LLM providers we’ve examined, OpenAI offers the most flexible solution with the simplest configuration. Their “Structured Outputs API” can directly accept a Pydantic model, enabling it to read both the data model and field descriptions effortlessly:
class Suggestion(BaseModel):
suggestion: str = Field(description="Suggestion to improve the bot, starting with letter K")
class Evaluation(BaseModel):
outcome: str = Field(description="whether a dialog was successful, either Yes or No")
explanation: str = Field(description="rationale behind the decision on outcome")
suggestions: list[Suggestion] = Field(description="Six ways to improve a bot")
@field_validator("outcome")
def check_literal(cls, value):
if not (value in ["Yes", "No"]):
print(f"Literal Yes/No not followed: {value}")
return value
@field_validator("suggestions")
def count_suggestions(cls, value):
if len(value) != 6:
print(f"Array length of 6 not followed: {value}")
count = sum(1 for item in value if item.suggestion.startswith('K'))
if len(value) != count:
print(f"{len(value)-count} suggestions don't start with K")
return value
def eval_dialogue(client, file: File) -> Evaluation:
completion = client.beta.chat.completions.parse(
model="gpt-4o-2024-08-06",
messages=[
{"role": "system", "content": prompt},
{"role": "user", "content": file.read()},
],
response_format=Evaluation,
)
In terms of robustness, OpenAI presents a graph comparing the success rates of their ‘Structured Outputs’ API versus prompt-based solutions, with the former achieving a success rate very close to 100%.
However, the devil is in the details. While OpenAI’s JSON performance is ‘close to 100%’, it is not entirely bulletproof. Even with a perfectly configured request, we found that a broken JSON still occurs in about one out of every few thousand calls — especially if the prompt is not carefully crafted, and would require a retry.
Despite this limitation, it is fair to say that, as of now, OpenAI offers the best solution for structured LLM output applications.
Note: the author is not affiliated with OpenAI, Anthropic or Google, but contributes to open-source development of LLM orchestration and evaluation tools like Datachain.
Links
Test Jupyter notebook:
datachain-examples/llm/llm_brute_force.ipynb at main · iterative/datachain-examples
Anthropic JSON API:
https://docs.anthropic.com/en/docs/test-and-evaluate/strengthen-guardrails/increase-consistency
Anthropic function calling:
https://docs.anthropic.com/en/docs/build-with-claude/tool-use#forcing-tool-use
LangChain Structured Output API:
https://python.langchain.com/v0.1/docs/modules/model_io/chat/structured_output/
Google Gemini JSON API:
https://ai.google.dev/gemini-api/docs/json-mode?lang=python
Google genai.protos.Schema examples:
OpenAI “Structured Outputs” announcement:
https://openai.com/index/introducing-structured-outputs-in-the-api/
OpenAI’s Structured Outputs API:
https://platform.openai.com/docs/guides/structured-outputs/introduction
Enforcing JSON outputs in commercial LLMs was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
Originally appeared here:
Enforcing JSON outputs in commercial LLMs
Go Here to Read this Fast! Enforcing JSON outputs in commercial LLMs