How to train and deploy a machine learning model in Azure
Introduction
In this article, we will go through an end-to-end example of a machine learning use case in Azure. We will discuss how to transform the data such that we can use it to train a model using Azure Synapse Analytics. Then we will train a model in Azure Machine Learning and score some test data with it. The purpose of this article is to give you an overview of what techniques and tools you need in Azure to do this and to show exactly how you do this. In researching this article, I found many conflicting code snippets of which most are outdated and contain bugs. Therefore, I hope this article gives you a good overview of techniques and tooling and a set of code snippets that help you to quickly start your machine learning journey in Azure.

Data and Objective
To build a Machine Learning example for this article, we need data. We will use a dataset I created on ice cream sales for every state in the US from 2017 to 2022. This dataset can be found here. You are free to use it for your own machine learning test projects. The objective is to train a model to forecast the number of ice creams sold on a given day in a state. To achieve this goal, we will combine this dataset with population data from each state, sourced from USAFacts. It is shared under a Creative Commons license, which can be found here.
To build a machine learning model, several data transformation steps are required. First, data formats need to be aligned and both data sets have to be combined. We will perform these steps in Azure Synapse Analytics in the next section. Then we will split the data into train and test data to train and evaluate the machine learning model.
Azure
Microsoft Azure is a suite of cloud computing services offered by Microsoft to build and manage applications in the cloud. It includes many different services, including storage, computing, and analytics services. Specifically for machine learning, Azure provides a Machine Learning Service which we will use in this article. Next to that, Azure also contains Azure Synapse Analytics, a tool for data orchestration, storage, and transformation. Therefore, a typical machine learning workflow in Azure uses Synapse to retrieve, store, and transform data and to call the model for inference and uses Azure Machine Learning to train, save, and deploy machine learning models. This workflow will be demonstrated in this article.
Synapse
As already mentioned, Azure Synapse Analytics is a tool for data pipelines and storage. I assume you have already created a Synapse workspace and a Spark cluster. Details on how to do this can be found here.
Before making any transformation on the data, we first have to upload it to the storage account of Azure Synapse. Then, we create integration datasets for both source datasets. Integration datasets are references to your dataset and can be used in other activities. Let’s also create two integration datasets for the data when the transformations are done, such that we can use them as storage locations after transforming the data.
Now we can start transforming the data. We will use two steps for this: The first step is to clean both datasets and save the cleaned versions, and the second step is to combine both datasets into one. This setup follows the standard bronze, silver, and gold procedure.
Data Flow
For the first step, we will use Azure Data Flow. Data Flow is a no-code option for data transformations in Synapse. You can find it under the Develop tab. There, create a data flow Icecream with the source integration dataset of the ice cream data as a source and the sink integration data set as a sink. The only transformation we will do here is to create the date column with the standard toDate function. This casts the date to the correct format. In the sink data set, you can also rename columns under the mapping tab.
For the population data set, we will rename some columns and unpivot the columns. Note that you can do all this without writing code, making it an easy solution for quick data transformation and cleaning.
Spark
Now, we will use a Spark notebook to join the two datasets and save the result to be used by Azure Machine Learning. Notebooks can be used in several programming languages, all use the Spark API. In this example, we will use PySpark, the Python API for Spark as it is complete. After reading the file, we join the population data per year on the ice creamdata, split it into a train and test data set, and write the result to our storage account. The details can be found in the script below:
Note that for using AutoML in Machine Learning, it is required to save the data sets as mltable format instead of parquet files. To do this, you can convert the parquets using the provided code snippet. You might need to authenticate with your Microsoft account in order to run this.
Pipelines
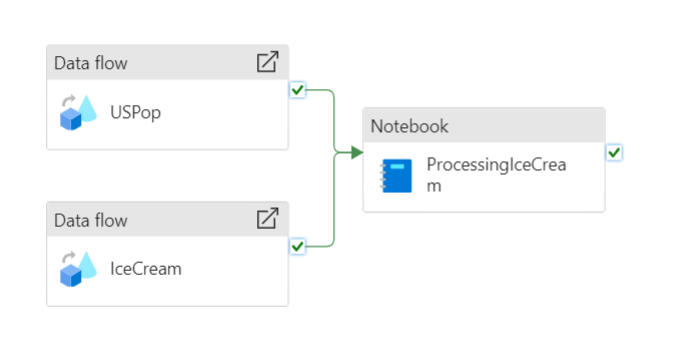
Now that we have created all activities, we have to create a pipeline to run these activities. Pipelines in Synapse are used to execute activities in a specified order and trigger. This makes it possible to retrieve data for instance daily or to retrain your model automatically every month. Let’s create a pipeline with three activities, two dataflow activities, and a Notebook activity. The result should be something similar to this:
Machine Learning
Azure Machine Learning (AML) is a tool that enables the training, testing, and deploying of machine learning models. The tool has a UI in which you can run machine learning workloads without programming. However, it is often more convenient to build and train models using the Python SDK (v2). It allows for more control and allows you to work in your favorite programming environment. So, let’s first install all packages required to do this. You can simply pip install this requirements.txt file to follow along with this example. Note that we will use lightgbm to create a model. You do not need this package if you are going to use a different model.
Now let’s start using the Python SDK to train a model. First, we have to authenticate to Azure Machine Learning using either the default or interactive credential class to get an MLClient. This will lazily authenticate to AML, whenever you need access to it.
Compute
The next step is to create a compute, something to run the actual workload. AML has several types of compute you can use. Compute instances are well suited as a development environment or for training runs. Compute clusters are for larger training runs or inference. We will create both a compute instance and a compute cluster in this article: the first for training, and the second for inferencing. The code to create a compute instance can be found below, the compute cluster will be created when we deploy a model to an endpoint.
It is also possible to use external clusters from for instance Databricks or Synapse. However, currently, Spark clusters from Synapse do not run a supported version for Azure Machine Learning. More information on clusters can be found here.
Environment
Training Machine Learning models on different machines can be challenging if you do not have a proper environment setup to run them. It is easy to miss a few dependencies or have slightly different versions. To solve this, AML uses the concept of a Environment, a Docker-backed Python environment to run your workloads. You can use existing Environments or create your own by selecting a Docker base image (or creating one yourself) and adding a conda.yaml file with all dependencies. For this article, we will create our environment from a Microsoft base image. The conda.yaml file and code to create an environment are provided.
Do not forget to include the azureml-inference-server-http package. You do not need it to train a model, however it is required for inferencing. If you forget it now, you will get errors during scoring and you have to start from here again. In the AML UI, you can inspect the progress and the underlying Docker image. Environments are also versioned, such that you can always revert to the previous version if required.
Data
Now that we have an environment to run our machine learning workload, we need access to our dataset. In AML there are several ways to add data to the training run. We will use the option to register our training dataset before using it to train a model. In this way, we again have versioning of our data. Doing this is quite straightforward by using the following script:
Training
Finally, we can start building the training script for our lightgbm model. In AML, this training script runs in a command with all the required parameters. So, let’s set up the structure of this training script first. We will use MLFlow for logging, saving and packaging of the model. The main advantage of using MLFlow, is that all dependencies will be packaged in the model file. Therefore, when deploying, we do not need to specify any dependencies as they are part of the model. Following an example script for an MLFlow model provided by Microsoft, this is the basic structure of a training script:
Filling in this template, we start with adding the parameters of the lightgbm model. This includes the number of leaves and the number of iterations and we parse them in the parse_args method. Then we will read the provided parquet file in the data set that we registered above. For this example, we will drop the date and state columns, although you can use them to improve your model. Then we will create and train the model using a part of the data as our validation set. In the end, we save the model such that we can use it later to deploy it in AML. The full script can be found below:
Now we have to upload this script to AML together with the dataset reference, environment, and the compute to use. In AML, this is done by creating a command with all these components and sending it to AML.
This will yield a URL to the training job. You can follow the status of training and the logging in the AML UI. Note that the cluster will not always start on its own. This at least happened to me sometimes. In that case, you can just manually start the compute instance via the UI. Training this model will take roughly a minute.
Endpoints
To use the model, we first need to create an endpoint for it. AML has two different types of endpoints. One, called an online endpoint is used for real-time inferencing. The other type is a batch endpoint, used for scoring batches of data. In this article, we will deploy the same model both to an online and a batch endpoint. To do this, we first need to create the endpoints. The code for creating an online endpoint is quite simple. This yields the following code for creating the endpoint:
We only need a small change to create the batch endpoint:
Deployment
Now that we have an endpoint, we need to deploy the model to this endpoint. Because we created an MLFlow model, the deployment is easier, because all requirements are packaged inside the model. The model needs to run on a compute cluster, we can create one while deploying the model to the endpoint. Deploying the model to the online endpoint will take roughly ten minutes. After the deployment, all traffic needs to be pointed to this deployment. This is done in the last lines of this code:
To deploy the same model to the batch endpoint, we first need to create a compute target. This target is then used to run the model on. Next, we create a deployment with deployment settings. In these settings, you can specify the batch size, concurrency settings, and the location for the output. After you have specified this, the steps are similar to deployment to an online endpoint.
Scoring with the Online Endpoint
Everything is now ready to use our model via the endpoints. Let’s first consume the model from the online endpoint. AML provides a sample scoring script that you can find in the endpoint section. However, creating the right format for the sample data can be slightly frustrating. The data needs to be sent in a nested JSON with the column indices, the indices of the sample, and the actual data. You can find a quick and dirty approach to do this in the example below. After you encode the data, you have to send it to the URL of the endpoint with the API key. You can find both in the endpoint menu. Note that you should never save the API key of your endpoint in your code. Azure provides a Key vault to save secrets. You can then reference the secret in your code to avoid saving it there directly. For more information see this link to the Microsoft documentation. The result variable will contain the predictions of your model.
Scoring with the Batch Endpoint
Scoring data via the batch endpoint works a bit differently. Typically, it involves more data, therefore it can be useful to register a dataset for this in AML. We have done this before in this article for the training data. We will then create a scoring job with all the information and send this to our endpoint. During scoring, we can review the progress of the job and poll for instance its status. After the job is completed, we can download the results from the output location that we specified when creating the batch endpoint. In this case, we saved the results in a CSV file.
Although we scored the data and received the output locally, we can run the same code in Azure Synapse Analytics to score the data from there. However, in most cases, I find it easier to first test everything locally before running it in Synapse.
Conclusion
We have reached the end of this article. To summarize, we imported data in Azure using Azure Synapse Analytics, transformed it using Synapse, and trained and deployed a machine learning model with this data in Azure Machine Learning. Last, we scored a dataset with both endpoints. I hope this article helped create an understanding of how to use Machine Learning in Azure. If you followed along, do not forget to delete endpoints, container registries and other resources you have created to avoid incurring costs for them.
Sources
- US population over time
- azureml-examples/sdk/python/endpoints/batch/deploy-models/heart-classifier-mlflow/mlflow-for-batch-tabular.ipynb at main · Azure/azureml-examples
- azureml-examples/tutorials/get-started-notebooks/quickstart.ipynb at main · Azure/azureml-examples
https://learn.microsoft.com/en-us/azure/machine-learning/
End-to-End Machine Learning in Azure was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
Originally appeared here:
End-to-End Machine Learning in Azure
Go Here to Read this Fast! End-to-End Machine Learning in Azure