
Lessons from 30+ years in data engineering: The overlooked value of keeping it simple
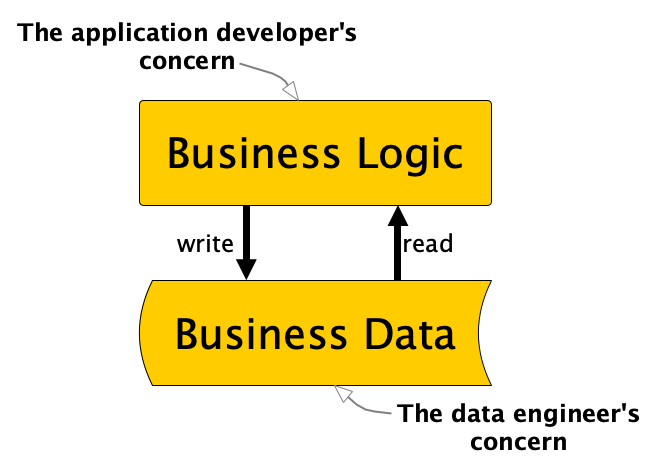
We have a straightforward and fundamental principle in computer programming: the separation of concerns between logic and data. Yet, when I look at the current data engineering landscape, it’s clear that we’ve strayed from this principle, complicating our efforts significantly — I’ve previously written about this issue.
There are other elegantly simple principles that we frequently overlook and fail to follow. The developers of the Unix operating system, for instance, introduced well thought-out and simple abstractions for building software products. These principles have stood the test of time, evident in millions of applications built upon them. However, for some reason we often take convoluted detours via complex and often closed ecosystems, loosing sight of the KISS principle and the Unix philosophy of simplicity and composability.
Why does this happen?
Let’s explore some examples and delve into a bit of history to better understand this phenomenon. This exploration might help to grasp why we repeatedly fail to keep things simple.
Databases
Unix-like systems offer a fundamental abstraction of data as files. In these systems nearly everything related to data is a file, including:
- Regular Files: Typically text, pictures, programs, etc.
- Directories: A special type of file containing lists of other files, organizing them hierarchically.
- Devices: Files representing hardware devices, including block-oriented (disks) and character-oriented devices (terminals).
- Pipes: Files enabling communication between processes.
- Sockets: Files facilitating network communication between computer nodes.
Each application can use common operations that all work similar on these different file types, like open(), read(), write(), close(), and lseek (change the position inside a file). The content of a file is just a stream of bytes and the system has no assumptions about the structure of a file’s content. For every file the system maintains basic metadata about the owner, access rights, timestamps, size, and location of the data-blocks on disks.
This compact and at the same time versatile abstraction supports the construction of very flexible data systems. It has, for instance, also been used to create the well-known relational database systems, which introduced the new abstraction called relation (or table) for us.
Unfortunately these systems evolved in ways that moved away from treating relations as files. To access the data in these relations now requires calling the database application, using the structured query language (SQL) which was defined as the new interface to access data. This allowed databases to better control access and offer higher-level abstractions than the file system.
Was this an improvement in general? For a few decades, we obviously believed in that and relational database systems got all the rage. Interfaces such as ODBC and JDBC standardized access to various database systems, making relational databases the default for many developers. Vendors promoted their systems as comprehensive solutions, incorporating not just data management but also business logic, encouraging developers to work entirely within the database environment.
A brave man named Carlos Strozzi tried to counteract this development and adhere to the Unix philosophy. He aimed to keep things simple and treat the database as just a thin extension to the Unix file abstraction. Because he didn’t want to force applications to only use SQL for accessing the data, he called it NoSQL RDBMS. The term NoSQL was later taken over by the movement towards alternative data storage models driven by the need to handle increasing data volumes at internet scale. Relational databases were dismissed by the NoSQL community as outdated and incapable to address the needs of modern data systems. A confusing multitude of new APIs occured.
Ironically, the NoSQL community eventually recognized the value of a standard interface, leading to the reinterpretation of NoSQL as “Not Only SQL” and the reintroduction of SQL interfaces to NoSQL databases. Concurrently, the open-source movement and new open data formats like Parquet and Avro emerged, saving data in plain files compatible with the good old Unix file abstractions. Systems like Apache Spark and DuckDB now use these formats, enabling direct data access via libraries relying solely on file abstractions, with SQL as one of many access methods.
Ultimately, databases actually didn’t offer the better abstraction for the implementation of all the multifaceted requirements in the enterprise. SQL is a valuable tool but not the only or best option. We had to take the detours via RDBMS and NoSQL databases to end up back at files. Maybe we recognize that simple Unix-like abstractions actually provide a robust foundation for the versatile requirements to data management.
Don’t get me wrong, databases remain crucial, offering features like ACID, granular access control, indexing, and many other. However, I think that one single monolithic system with a constrained and opinionated way of representing data is not the right way to deal with all that varied requirements at enterprise level. Databases add value but should be open and usable as components within larger systems and architecures.
New ecosystems everywhere
Databases are just one example of the trend to create new ecosystems that aim to be the better abstraction for applications to handle data and even logic. A similar phenomenon occured with the big data movement. In an effort to process the enormous amounts of data that traditional databases could apparently no longer handle, a whole new ecosystem emerged around the distributed data system Hadoop.
Hadoop implemented the distributed file system HDFS, tightly coupled with the processing framework MapReduce. Both components are completely Java-based and run in the JVM. Consequently, the abstractions offered by Hadoop were not seamless extensions to the operating system. Instead, applications had to adopt a completely new abstraction layer and API to leverage the advancements in the big data movement.
This ecosystem spawned a multitude of tools and libraries, ultimately giving rise to the new role of the data engineer. A new role that seemed inevitable because the ecosystem had grown so complex that regular software engineers could no longer keep up. Clearly, we failed to keep things simple.
Distributed operating system equivalents
With the insight that big data can’t be handled by single systems, we witnessed the emergence of new distributed operating system equivalents. This somewhat unwieldy term refers to systems that allocate resources to software components running across a cluster of compute nodes.
For Hadoop, this role was filled with YARN (Yet Another Resource Negotiator), which managed resource allocation among the running MapReduce jobs in Hadoop clusters, much like an operating system allocates resources among processes running in a single system.
Consequently, an alternative approach would have been to scale the Unix-like operating systems across multiple nodes while retaining familiar single-system abstractions. Indeed, such systems, known as Single System Image (SSI), were developed independently of the big data movement. This approach abstracted the fact that the Unix-like system ran on many distributed nodes, promising horizontal scaling while evolving proven abstractions. However, the development of these systems proved complex apparently and stagnated around 2015.
A key factor in this stagnation was likely the parallel development by influential cloud providers, who advanced YARN functionality into a distributed orchestration layer for standard Linux systems. Google, for example, pioneered this with its internal system Borg, which apparently required less effort than rewriting the operating system itself. But once again, we sacrificed simplicity.
Today, we lack a system that transparently scales single-system processes across a cluster of nodes. Instead, we were blessed (or cursed?) with Kubernetes that evolved from Google’s Borg to become the de-facto standard for a distributed resource and orchestration layer running containers in clusters of Linux nodes. Known for its complexity, Kubernetes requires the learning about Persistent Volumes, Persistent Volume Claims, Storage Classes, Pods, Deployments, Stateful Sets, Replica Sets and more. A totally new abstraction layer that bears little resemblance to the simple, familiar abstractions of Unix-like systems.
Agility
It is not only computer systems that suffer from supposed advances that disregard the KISS principle. The same applies to systems that organize the development process.
Since 2001, we have a lean and well-thougt-out manifesto of principles for agile software development. Following these straightforward principles helps teams to collaborate, innovate, and ultimately produce better software systems.
However, in our effort to ensure successful application, we tried to prescribe these general principles more precisely, detailing them so much that teams now require agile training courses to fully grasp the complex processes. We finally got overly complex frameworks like SAFe that most agile practitioners wouldn’t even consider agile anymore.
You do not have to believe in agile principles — some argue that agile working has failed — to see the point I’m making. We tend to complicate things excessively when commercial interests gain upper hand or when we rigidly prescribe rules that we believe must be followed. There’s a great talk on this by Dave Thomas (one of the authors of the manifesto) where he explains what happens when we forget about simplicity.
Trust in principles and architecture, not products and rituals
The KISS principle and the Unix philosophy are easy to understand, but in the daily madness of data architecture in IT projects, they can be hard to follow. We have too many tools, too many vendors selling too many products that all promise to solve our challenges.
The only way out is to truly understand and adhere to sound principles. I think we should always think twice before replacing tried and tested simple abstractions with something new and trendy.
I’ve written about my personal strategy for staying on top of things and understanding the big picture to deal with the extreme complexity we face.
Commercialism must not determine decisions
It is hard to follow the simple principles given by the Unix philosophy when your organization is clamoring for a new giant AI platform (or any other platform for that matter).
Enterprise Resource Planning (ERP) providers, for instance, made us believe at the time that they could deliver systems covering all relevant business requirements in a company. How dare you contradict these specialists?
Unified Real-Time (Data) Platform (URP) providers now claim their systems will solve all our data concerns. How dare you not use such a comprehensive system?
But products are always just a small brick in the overall system architecture, no matter how extensive the range of functionality is advertised.
Data engineering should be grounded in the same software architecture principles used in software engineering. And software architecture is about balancing trade-offs and maintaining flexibility, focusing on long-term business value. Simplicity and composability can help you maintain this focus.
Pressure from closed thinking models
Not only commercialism keeps us from adhering to simplicity. Even open source communities can be dogmatic. While we seek golden rules for perfect systems development, they don’t exist in reality.
The Python community may say that non-pythonic code is bad. The functional programming community might claim that applying OOP principles will send you to hell. And the protagonists on agile programming may want to convince you that any development following the waterfall approach will doom your project to failure. Of course, they are all wrong in their absolutism, but we often dismiss ideas outside our thinking space as inappropriate.
We like clear rules that we just have to follow to be successful. At one of my clients, for instance, the software development team had intensely studied software design patterns. Such patterns can be very helpful in finding a tried and tested solution for common problems. But what I actually observed in the team was that they viewed these patterns as rules that they had to adhere to rigidly. Not following these rules was like being a bad software engineer. But this often leaded to overly complex designs for very simple problems. Critical thinking based on sound principles cannot be replaced by rigid adherence to rules.
In the end, it takes courage and thorough understanding of principles to embrace simplicity and composability. This approach is essential to design reliable data systems that scale, can be maintained, and evolve with the enterprise.
If you find this information useful, please consider to clap. I would be more than happy to receive your feedback with your opinions and questions.
Embracing Simplicity and Composability in Data Engineering was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
Originally appeared here:
Embracing Simplicity and Composability in Data Engineering
Go Here to Read this Fast! Embracing Simplicity and Composability in Data Engineering