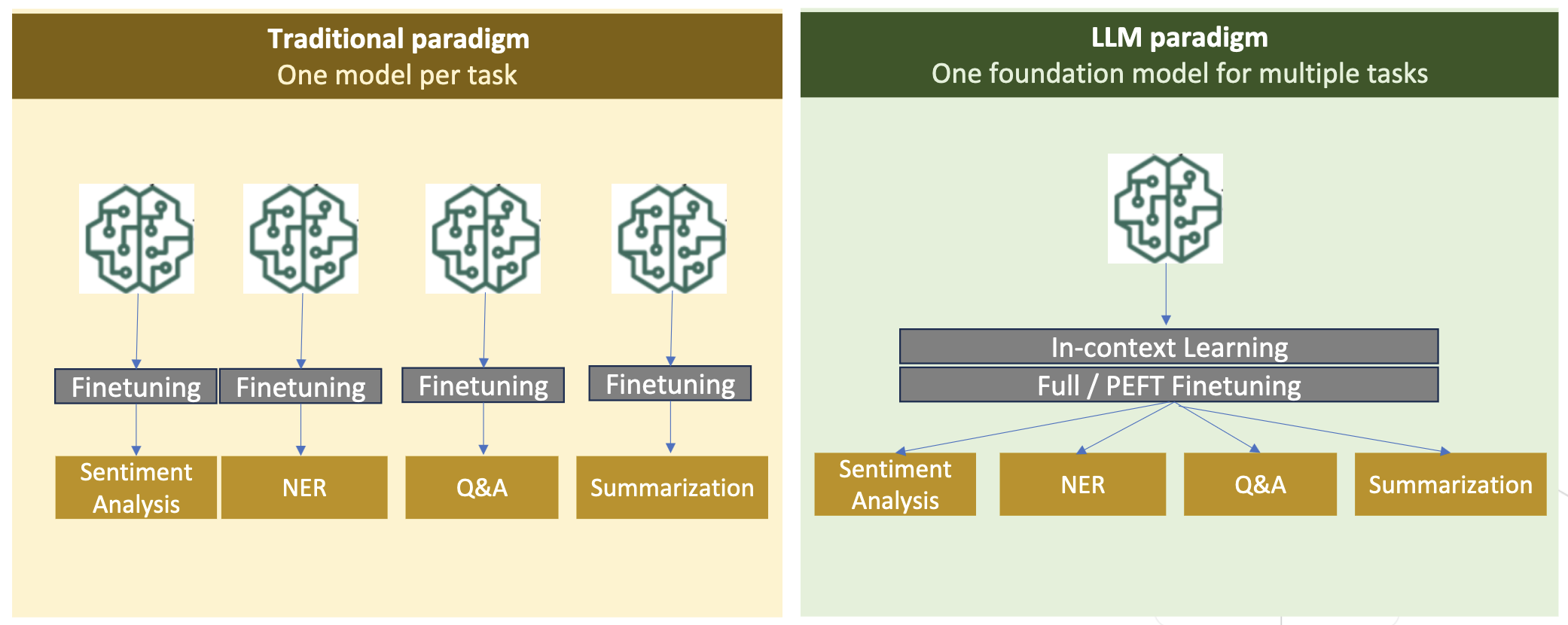

Large language models (LLMs) are generally trained on large publicly available datasets that are domain agnostic. For example, Meta’s Llama models are trained on datasets such as CommonCrawl, C4, Wikipedia, and ArXiv. These datasets encompass a broad range of topics and domains. Although the resulting models yield amazingly good results for general tasks, such as […]
Originally appeared here:
Efficient continual pre-training LLMs for financial domains
Go Here to Read this Fast! Efficient continual pre-training LLMs for financial domains