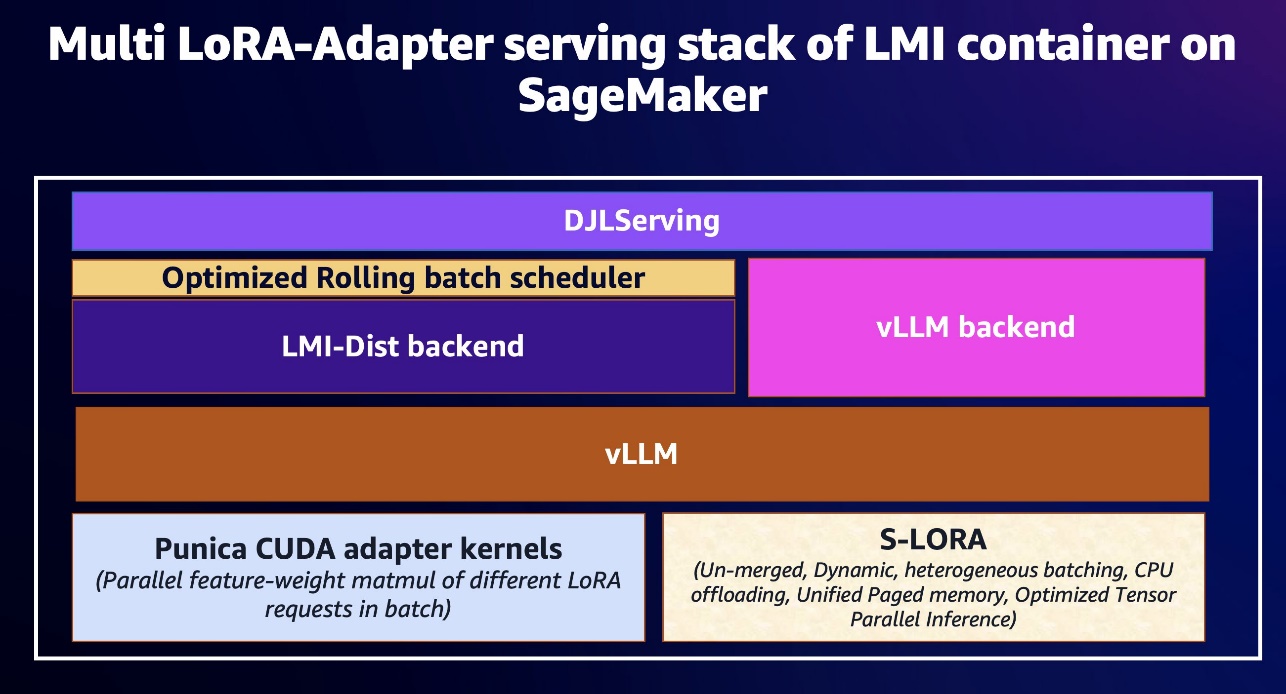

In this post, we explore a solution that addresses these challenges head-on using LoRA serving with Amazon SageMaker. By using the new performance optimizations of LoRA techniques in SageMaker large model inference (LMI) containers along with inference components, we demonstrate how organizations can efficiently manage and serve their growing portfolio of fine-tuned models, while optimizing costs and providing seamless performance for their customers. The latest SageMaker LMI container offers unmerged-LoRA inference, sped up with our LMI-Dist inference engine and OpenAI style chat schema. To learn more about LMI, refer to LMI Starting Guide, LMI handlers Inference API Schema, and Chat Completions API Schema.
Originally appeared here:
Efficient and cost-effective multi-tenant LoRA serving with Amazon SageMaker