
Helping enhance your understanding and optimal usage of structured outputs and LLMs
In the previous article, we were introduced to structured outputs using OpenAI. Since the general availability release in ChatCompletions API (v1.40.0), structured outputs have been applied across dozens of use cases, and spawned numerous threads on OpenAI forums.
In this article, our aim is to provide you with an even deeper understanding, dispel some misconceptions, and give you some tips on how to apply them in the most optimal manner possible, across different scenarios.
Structured outputs overview
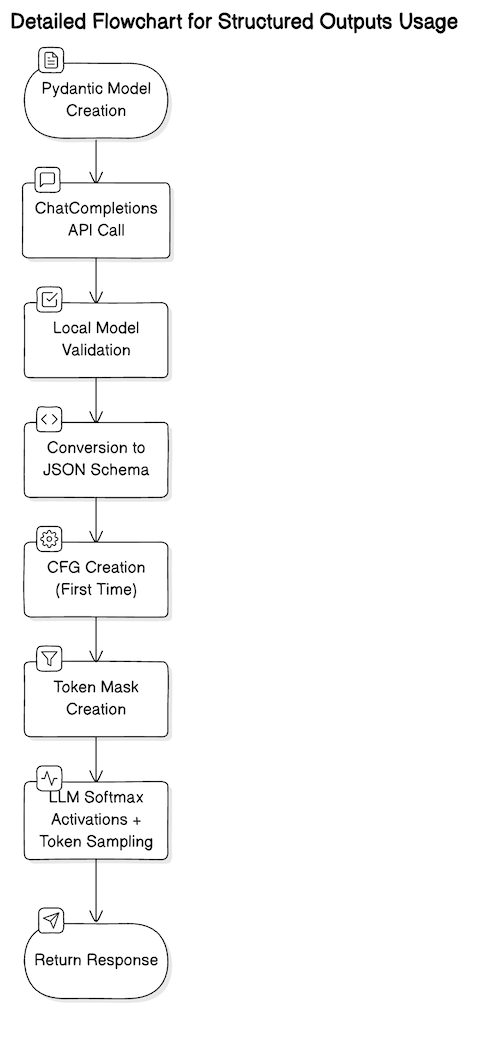
Structured outputs are a way of enforcing the output of an LLM to follow a pre-defined schema — usually a JSON schema. This works by transforming the schema into a context free grammar (CFG), which during the token sampling step, is used together with the previously generated tokens, to inform which subsequent tokens are valid. It’s helpful to think of it as creating a regex for token generation.
OpenAI API implementation actually tracks a limited subset of JSON schema features. With more general structured output solutions, such as Outlines, it is possible to use a somewhat larger subset of the JSON schema, and even define completely custom non-JSON schemas — as long as one has access to an open weight model. For the purpose of this article, we will assume the OpenAI API implementation.
JSON Schema and Pydantic
According to JSON Schema Core Specification, “JSON Schema asserts what a JSON document must look like, ways to extract information from it, and how to interact with it”. JSON schema defines six primitive types — null, boolean, object, array, number and string. It also defines certain keywords, annotations, and specific behaviours. For example, we can specify in our schema that we expect an array and add an annotation that minItems shall be 5 .
Pydantic is a Python library that implements the JSON schema specification. We use Pydantic to build robust and maintainable software in Python. Since Python is a dynamically typed language, data scientists do not necessarily think in terms of variable types — these are often implied in their code. For example, a fruit would be specified as:
fruit = dict(
name="apple",
color="red",
weight=4.2
)
…while a function declaration that returns “fruit” from some piece of data would often be specified as:
def extract_fruit(s):
...
return fruit
Pydantic on the other hand allows us to generate a JSON-schema compliant class, with properly annotated variables and type hints, making our code more readable/maintainable and in general more robust, i.e.
class Fruit(BaseModel):
name: str
color: Literal['red', 'green']
weight: Annotated[float, Gt(0)]
def extract_fruit(s: str) -> Fruit:
...
return fruit
OpenAI actually strongly recommends the use of Pydantic for specifying schemas, as opposed to specifying the “raw” JSON schema directly. There are several reasons for this. Firstly, Pydantic is guaranteed to adhere to the JSON schema specification, so it saves you extra pre-validation steps. Secondly, for larger schemas, it is less verbose, allowing you to write cleaner code, faster. Finally, the openai Python package actually does some housekeeping, like setting additionalProperties to False for you, whereas when defining your schema “by-hand” using JSON, you would need to set these manually, for every object in your schema (failing to do so results in a rather annoying API error).
Limitations
As we alluded to previously, the ChatCompletions API provides a limited subset of the full JSON schema specification. There are numerous keywords that are not yet supported, such as minimum and maximum for numbers, and minItems and maxItems for arrays — annotations that would be otherwise very useful in reducing hallucinations, or constraining the output size.
Certain formatting features are also unavailable. For example, the following Pydantic schema would result in API error when passed to response_format in ChatCompletions:
class NewsArticle(BaseModel):
headline: str
subheading: str
authors: List[str]
date_published: datetime = Field(None, description="Date when article was published. Use ISO 8601 date format.")
It would fail because openai package has no format handling for datetime , so instead you would need to set date_published as a str and perform format validation (e.g. ISO 8601 compliance) post-hoc.
Other key limitations include the following:
- Hallucinations are still possible — for example, when extracting product IDs, you would define in your response schema the following: product_ids: List[str] ; while the output is guaranteed to produce a list of strings (product IDs), the strings themselves may be hallucinated, so in this use case, you may want to validate the output against some pre-defined set of product IDs.
- The output is capped at 4096 tokens, or the lesser number you set within the max_tokens parameter — so even though the schema will be followed precisely, if the output is too large, it will be truncated and produce an invalid JSON — especially annoying on very large Batch API jobs!
- Deeply nested schemas with many object properties may yield API errors — there is a limitation on the depth and breadth of your schema, but in general it is best to stick to flat and simple structures— not just to avoid API errors but also to squeeze out as much performance from the LLMs as possible (LLMs in general have trouble attending to deeply nested structures).
- Highly dynamic or arbitrary schemas are not possible — even though recursion is supported, it is not possible to create a highly dynamic schema of let’s say, a list of arbitrary key-value objects, i.e. [{“key1”: “val1”}, {“key2”: “val2”}, …, {“keyN”: “valN”}] , since the “keys” in this case must be pre-defined; in such a scenario, the best option is not to use structured outputs at all, but instead opt for standard JSON mode, and provide the instructions on the output structure within the system prompt.
Tips and tricks
With all this in mind, we can now go through a couple of use cases with tips and tricks on how to enhance the performance when using structured outputs.
Creating flexibility using optional parameters
Let’s say we are building a web scraping application where our goal is to collect specific components from the web pages. For each web page, we supply the raw HTML in the user prompt, give specific scraping instructions in the system prompt, and define the following Pydantic model:
class Webpage(BaseModel):
title: str
paragraphs: Optional[List[str]] = Field(None, description="Text contents enclosed within <p></p> tags.")
links: Optional[List[str]] = Field(None, description="URLs specified by `href` field within <a></a> tags.")
images: Optional[List[str]] = Field(None, description="URLs specified by the `src` field within the <img></img> tags.")
We would then call the API as follows…
response = client.beta.chat.completions.parse(
model="gpt-4o-2024-08-06",
messages=[
{
"role": "system",
"content": "You are to parse HTML and return the parsed page components."
},
{
"role": "user",
"content": """
<html>
<title>Structured Outputs Demo</title>
<body>
<img src="test.gif"></image>
<p>Hello world!</p>
</body>
</html>
"""
}
],
response_format=Webpage
)
…with the following response:
{
'images': ['test.gif'],
'links': None,
'paragraphs': ['Hello world!'],
'title': 'Structured Outputs Demo'
}
Response schema supplied to the API using structured outputs must return all the specified fields. However, we can “emulate” optional fields and add more flexibility using the Optional type annotation. We could actually also use Union[List[str], None] — they are syntactically exactly the same. In both cases, we get a conversion to anyOf keyword as per the JSON schema spec. In the example above, since there are no <a></a> tags present on the web page, the API still returns the links field, but it is set to None .
Reducing hallucinations using enums
We mentioned previously that even if the LLM is guaranteed to follow the provided response schema, it may still hallucinate the actual values. Adding to this, a recent paper found that enforcing a fixed schema on the outputs, actually causes the LLM to hallucinate, or degrade in terms of its reasoning capabilities.
One way to overcome these limitations, is to try and utilize enums as much as possible. Enums constrain the output to a very specific set of tokens, placing a probability of zero on everything else. For example, let’s assume you are trying to re-rank product similarity results between a target product that contains a description and a unique product_id , and top-5 products that were obtained using some vector similarity search (e.g. using a cosine distance metric). Each one of those top-5 products also contain the corresponding textual description and a unique ID. In your response you simply wish to obtain the re-ranking 1–5 as a list (e.g. [1, 4, 3, 5, 2] ), instead of getting a list of re-ranked product ID strings, which may be hallucinated or invalid. We setup our Pydantic model as follows…
class Rank(IntEnum):
RANK_1 = 1
RANK_2 = 2
RANK_3 = 3
RANK_4 = 4
RANK_5 = 5
class RerankingResult(BaseModel):
ordered_ranking: List[Rank] = Field(description="Provides ordered ranking 1-5.")
…and run the API like so:
response = client.beta.chat.completions.parse(
model="gpt-4o-2024-08-06",
messages=[
{
"role": "system",
"content": """
You are to rank the similarity of the candidate products against the target product.
Ranking should be orderly, from the most similar, to the least similar.
"""
},
{
"role": "user",
"content": """
## Target Product
Product ID: X56HHGHH
Product Description: 80" Samsung LED TV
## Candidate Products
Product ID: 125GHJJJGH
Product Description: NVIDIA RTX 4060 GPU
Product ID: 76876876GHJ
Product Description: Sony Walkman
Product ID: 433FGHHGG
Product Description: Sony LED TV 56"
Product ID: 777888887888
Product Description: Blueray Sony Player
Product ID: JGHHJGJ56
Product Description: BenQ PC Monitor 37" 4K UHD
"""
}
],
response_format=RerankingResult
)
The final result is simply:
{'ordered_ranking': [3, 5, 1, 4, 2]}
So the LLM ranked the Sony LED TV (i.e. item number “3” in the list), and the BenQ PC Monitor (i.e. item number “5”), as the two most similar product candidates, i.e. the first two elements of the ordered_ranking list!
Conclusion
In this article we gave a thorough deep-dive into structured outputs. We introduced the JSON schema and Pydantic models, and connected these to OpenAI’s ChatCompletions API. We walked through a number of examples and showcased some optimal ways of resolving those using structured outputs. To summarize some key takeaways:
- Structured outputs as supported by OpenAI API, and other 3rd party frameworks, implement only a subset of the JSON schema specification — getting better informed in terms of its features and limitations will help you make the right design decisions.
- Using Pydantic or similar frameworks that track JSON schema specification faithfully, is highly recommended, as it allows you to create valid and cleaner code.
- Whilst hallucinations are still expected, there are different ways of mitigating those, simply by a choice of response schema design; for example, by utilizing enums where appropriate.
About the Author
Armin Catovic is a Secretary of the Board at Stockholm AI, and a Vice President and a Senior ML/AI Engineer at the EQT Group, with 18 years of engineering experience across Australia, South-East Asia, Europe and the US, and a number of patents and top-tier peer-reviewed AI publications.
Diving Deeper with Structured Outputs was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
Originally appeared here:
Diving Deeper with Structured Outputs
Go Here to Read this Fast! Diving Deeper with Structured Outputs