

Diving Deep into AutoGen and Multi-Agent Frameworks
This blog post will go into the details of the “AutoGen: Enabling Next-Gen LLM Applications via Multi-Agent Conversation” paper and the AutoGen project
Agents have recently been all over technical news sites. While people have big aspirations for what these programs can do, there has not been much discussion about the frameworks that should power these agents. From a high-level, an agent is simply a program, usually powered by a Large Language Model (LLM) that accomplishes an action. While anyone can prompt a LLM, the key distinguisher for agentic systems is their consistent performance in the face of ambiguous tasks.
To get this kind of consistent performance is not trivial. While prompting techniques like Chain-of-Thought, reflection, and others have been shown to improve LLM performance, LLMs tend to improve radically when given proper feedback during a chat session. This can look like a scientist pointing out a flaw in the chat bot’s response, or a programmer copying in the compiler message when they try to run the LLM’s code.
Thus, as we try to make these agentic systems more consistently performant, one might reasonably ask if we can find a way to have multiple LLMs giving each other feedback, thus improving the overall output of the system. This is where the authors of the “AutoGen: Enabling Next-Gen LLM Applications via Multi-Agent Conversation” paper come in. They both wrote a paper and started a MIT License project to address this viewpoint.
We’ll start with the high-level concepts discussed in the paper and then transition to some examples using the autogen codebase.
Conversable Agent
To orchestrate the LLMs, AutoGen relies on a conversation model. The basic idea is that the agents converse amongst each other to solve the problem. Just like how humans improve upon each other’s work, the LLMs listen to what the others say and then provide improvements or new information.
While one might initially expect all of the work to be done by an LLM, agentic systems need more than just this functionality. As papers like Voyager have shown, there is outsize performance to be gained by creating skills and tools for the agents to use. This means allowing the system to save and execute functions previously coded by the LLM and also leaving open the door for actors like humans to play a role. Thus, the authors decided there are three major sources for the agent: LLM, Human, and Tool.

As we can see from the above, we have a parent class called ConversableAgent which allows for any of the three sources to be used. From this parent, our child classes of AssistantAgent and UserProxyAgent are derived. Note that this shows a pattern of choosing one of the three sources for the agent as we create specialized classes. We like to separate the agents into clear roles so that we can use conversation programming to direct them.
Conversation Programming
With our actors defined, we can discuss how to program them to accomplish the end-goal of our agent. The authors recommend thinking about conversation programming as determining what an agent should compute and when it should compute it.
Every Agent has a send , receive , and a generate_reply function. Going sequentially, first the agent will receive a message, then generate_reply, and finally send the message to other agents. When an agent receives the message is how we control when the computations happen. We can do this both with and without a manager as we’ll see below. While each of these functions can be customized, the generate_reply is the one where the authors recommend you put your computation logic for the agent. Let’s walk through a high-level example from the paper below to see how this is done.
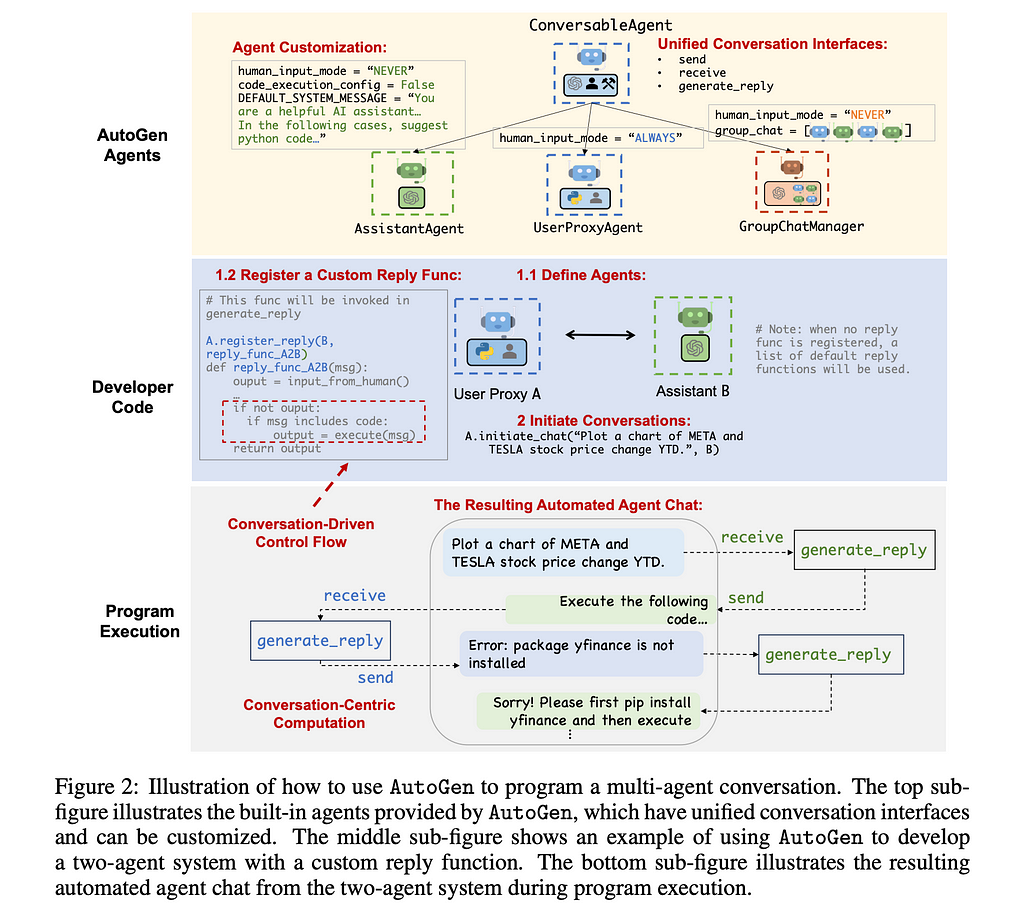
Working our way down, we create two agents: a AssistantAgent (which interacts with OpenAI’s LLMs) and a UserProxyAgent (which will give the instructions and run the code it is sent back). With UserProxyAgent, the authors then defined reply_func_A2B where we see that if the agent sends back code, the UserProxyAgent will then execute that code. Moreover, to make sure that the UserProxyAgent only responds when necessary, we have logic wrapped around that code execution call. The agents will go back and forth until a termination message is sent or we hit the maximum number of auto replies, or when an agent responds to itself the maximum number of times.
In the below visualization of that interaction, we can see that the two agents iterate to create a final result that is immediately useful to the user.
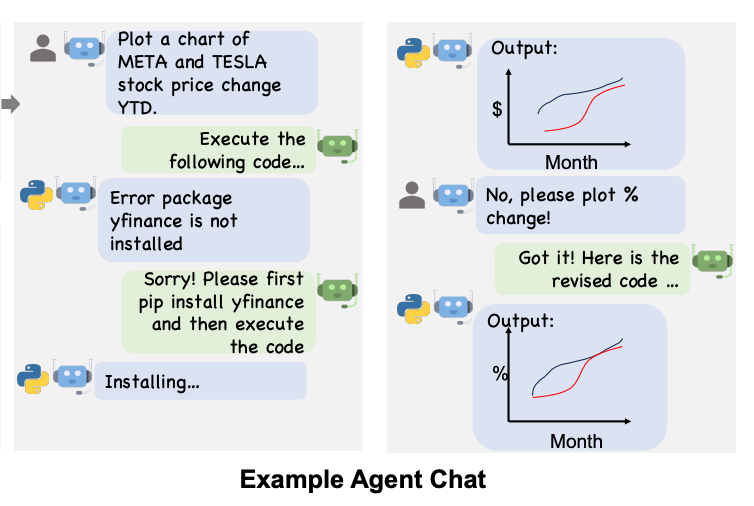
Now that we have a high-level understanding, let’s dive into the code with some example applications.
Coding Example
Let’s start off with asking the LLM to generate code that runs locally and ask the LLM to edit if any exceptions are thrown. Below I’m modifying the “Task Solving with Code Generation, Execution and Debugging” example from the AutoGen project.
from IPython.display import Image, display
import autogen
from autogen.coding import LocalCommandLineCodeExecutor
import os
config_list = [{
"model": "llama3-70b-8192",
"api_key": os.environ.get('GROQ_API_KEY'),
"base_url":"https://api.groq.com/openai/v1"
}]
assistant = autogen.AssistantAgent(
name="assistant",
llm_config={
"cache_seed": 41, # seed for caching and reproducibility
"config_list": config_list, # a list of OpenAI API configurations
"temperature": 0, # temperature for sampling
}, # configuration for autogen's enhanced inference API which is compatible with OpenAI API
)
# create a UserProxyAgent instance named "user_proxy"
user_proxy = autogen.UserProxyAgent(
name="user_proxy",
human_input_mode="NEVER",
max_consecutive_auto_reply=10,
is_termination_msg=lambda x: x.get("content", "").rstrip().endswith("TERMINATE"),
code_execution_config={
# the executor to run the generated code
"executor": LocalCommandLineCodeExecutor(work_dir="coding"),
},
)
# the assistant receives a message from the user_proxy, which contains the task description
chat_res = user_proxy.initiate_chat(
assistant,
message="""What date is today? Compare the year-to-date gain for META and TESLA.""",
summary_method="reflection_with_llm",
)
To go into the details, we begin with instantiating two agents — our user proxy agent (AssistantAgent) and our LLM agent (UserProxyAgent). The LLM agent is given an API key so that it can call the external LLM and then a system message along with a cache_seed to reduce randomness across runs. Note that AutoGen doesn’t limit you to only using OpenAI endpoints — you can connect to any external provider that follows the OpenAI API format (in this example I’m showing Groq).
The user proxy agent has a more complex configuration. Going over some of the more interesting ones, let’s start from the top. The human_input_mode allows you to determine how involved the human should be in the process. The examples here and below choose “NEVER”, as they want this to be as seamless as possible where the human is never prompted. If you pick something like “ALWAYS”, the human is prompted every time the agent receives a message. The middle-ground is “TERMINATE”, which will prompt the user only when we either hit the max_consecutive_auto_reply or when a termination message is received from one of the other agents.
We can also configure what the termination message looks like. In this case, we look to see if TERMINATE appears at the end of the message received by the agent. While the code above doesn’t show it, the prompts given to the agents within the AutoGen library are what tell the LLM to respond this way. To change this, you would need to alter the prompt and the config.
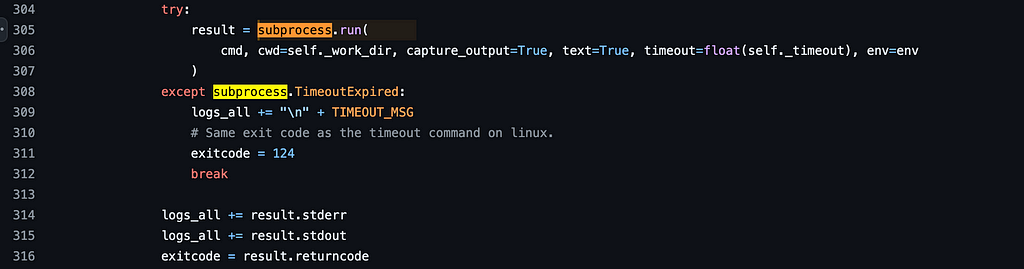
Finally, and perhaps most critically, is the code_execution_config. In this example, we want the user’s computer to execute the code generated by the LLM. To do so, we pass in this LocalCommandLineCodeExecutor that will handle the processing. The code here determines the system’s local shell and then saves the program to a local file. It will then use Python’s subprocess to execute this locally and return both stdout and stderr, along with the exit code of the subprocess.
RAG Example
Moving on to another example, let’s see how to set up a Retrieval Augmented Generation (RAG) agent using the “Using RetrieveChat for Retrieve Augmented Code Generation and Question Answering” example. In short, this code allows a user to ask a LLM a question about a specific data-source and get a high-accuracy response to that question.
import json
import os
import chromadb
import autogen
from autogen.agentchat.contrib.retrieve_assistant_agent import RetrieveAssistantAgent
from autogen.agentchat.contrib.retrieve_user_proxy_agent import RetrieveUserProxyAgent
# Accepted file formats for that can be stored in
# a vector database instance
from autogen.retrieve_utils import TEXT_FORMATS
config_list = [
{"model": "gpt-3.5-turbo-0125", "api_key": "<YOUR_API_KEY>", "api_type": "openai"},
]
assistant = RetrieveAssistantAgent(
name="assistant",
system_message="You are a helpful assistant.",
llm_config={
"timeout": 600,
"cache_seed": 42,
"config_list": config_list,
},
)
ragproxyagent = RetrieveUserProxyAgent(
name="ragproxyagent",
human_input_mode="NEVER",
max_consecutive_auto_reply=3,
retrieve_config={
"task": "qa",
"docs_path": [
"https://raw.githubusercontent.com/microsoft/FLAML/main/website/docs/Examples/Integrate%20-%20Spark.md",
"https://raw.githubusercontent.com/microsoft/FLAML/main/website/docs/Research.md",
os.path.join(os.path.abspath(""), "..", "website", "docs"),
],
"custom_text_types": ["non-existent-type"],
"chunk_token_size": 2000,
"model": config_list[0]["model"],
"vector_db": "chroma", # conversely pass your client here
"overwrite": False, # set to True if you want to overwrite an existing collection
},
code_execution_config=False, # set to False if you don't want to execute the code
)
assistant.reset()
code_problem = "How can I use FLAML to perform a classification task and use spark to do parallel training. Train 30 seconds and force cancel jobs if time limit is reached."
chat_result = ragproxyagent.initiate_chat(
assistant, message=ragproxyagent.message_generator, problem=code_problem, search_string="spark"
)
The LLM Agent is setup similarly here, only with the class RetrieveAssistantAgent instead, which seems very similar to the typical AssistantAgent class.
For the RetrieveUserProxyAgent, we have a number of configs. From the top, we have a “task” value that tells the Agent what to do . It can be either “qa” (question and answer), “code” or “default”, where “default” means to both do code and qa. These determine the prompt given to the agent.
Most of the rest of the retrieve config here is used to pass in information for our RAG. RAG is typically built atop similarity search via vector embeddings, so this config lets us specify how the vector embeddings are created from the source documents. In the example above, we are passing through the model that creates these embeddings, the chunk size that we will break the source documents into for each embedding, and the vector database of choice.
There are two things to note with the example above. First, it assumes you are creating your vector DB on the fly. If you want to connect to a vector DB already instantiated, AutoGen can handle this, you’ll just pass in your client. Second, you should note that this API has recently changed, and work appears to still be active on it so the configs may be slightly different when you run it locally, though the high-level concepts will likely remain the same.
Multi-Agent Example
Finally, let’s go into how we can use AutoGen to have three or more agents. Below we have the “Group Chat with Coder and Visualization Critic” example, with three agents: a coder, critic and a user proxy.
Like a network, as we add more agents the number of connections increases at a quadratic rate. With the above examples, we only had two agents so we did not have too many messages that could be sent. With three we need assistance; we need a manger.
import matplotlib.pyplot as plt
import pandas as pd
import seaborn as sns
from IPython.display import Image
import autogen
config_list_gpt4 = autogen.config_list_from_json(
"OAI_CONFIG_LIST",
filter_dict={
"model": ["gpt-4", "gpt-4-0314", "gpt4", "gpt-4-32k", "gpt-4-32k-0314", "gpt-4-32k-v0314"],
},
)
llm_config = {"config_list": config_list_gpt4, "cache_seed": 42}
user_proxy = autogen.UserProxyAgent(
name="User_proxy",
system_message="A human admin.",
code_execution_config={
"last_n_messages": 3,
"work_dir": "groupchat",
"use_docker": False,
}, # Please set use_docker=True if docker is available to run the generated code. Using docker is safer than running the generated code directly.
human_input_mode="NEVER",
)
coder = autogen.AssistantAgent(
name="Coder", # the default assistant agent is capable of solving problems with code
llm_config=llm_config,
)
critic = autogen.AssistantAgent(
name="Critic",
system_message="""Critic. You are a helpful assistant highly skilled in evaluating the quality of a given visualization code by providing a score from 1 (bad) - 10 (good) while providing clear rationale. YOU MUST CONSIDER VISUALIZATION BEST PRACTICES for each evaluation. Specifically, you can carefully evaluate the code across the following dimensions
- bugs (bugs): are there bugs, logic errors, syntax error or typos? Are there any reasons why the code may fail to compile? How should it be fixed? If ANY bug exists, the bug score MUST be less than 5.
- Data transformation (transformation): Is the data transformed appropriately for the visualization type? E.g., is the dataset appropriated filtered, aggregated, or grouped if needed? If a date field is used, is the date field first converted to a date object etc?
- Goal compliance (compliance): how well the code meets the specified visualization goals?
- Visualization type (type): CONSIDERING BEST PRACTICES, is the visualization type appropriate for the data and intent? Is there a visualization type that would be more effective in conveying insights? If a different visualization type is more appropriate, the score MUST BE LESS THAN 5.
- Data encoding (encoding): Is the data encoded appropriately for the visualization type?
- aesthetics (aesthetics): Are the aesthetics of the visualization appropriate for the visualization type and the data?
YOU MUST PROVIDE A SCORE for each of the above dimensions.
{bugs: 0, transformation: 0, compliance: 0, type: 0, encoding: 0, aesthetics: 0}
Do not suggest code.
Finally, based on the critique above, suggest a concrete list of actions that the coder should take to improve the code.
""",
llm_config=llm_config,
)
groupchat = autogen.GroupChat(agents=[user_proxy, coder, critic], messages=[], max_round=20)
manager = autogen.GroupChatManager(groupchat=groupchat, llm_config=llm_config)
user_proxy.initiate_chat(
manager,
message="download data from https://raw.githubusercontent.com/uwdata/draco/master/data/cars.csv and plot a visualization that tells us about the relationship between weight and horsepower. Save the plot to a file. Print the fields in a dataset before visualizing it.",
)
To begin, similar to the examples above, we create an agent for the user (UserProxyAgent), but this time we create 2 distinct LLM agents — a coder and a critic. The coder is not given special instructions, but the critic is. The critic is given code from the coder agent and told to critique it along a certain paradigm.
After creating the agents, we take all three and pass them in to a GroupChat object. The group chat is a data object that keeps track of everything that has happened. It stores the messages, the prompts to help select the next agent, and the list of agents involved.
The GroupChatManager is then given this data object as a way to help it make its decisions. You can configure it to choose the next speaker in a variety of ways including round-round, randomly, and by providing a function. By default it uses the following prompt: “Read the above conversation. Then select the next role from {agentlist} to play. Only return the role.” Naturally, you can adjust this to your liking.
Once the conversation either goes on for the maximum number of rounds (in round robin) or once it gets a “TERMINATE” string, the manager will end the group chat. In this way, we can coordinate multiple agents at one.
Conclusion
While LLM research and development continues to create incredible performance, it seems likely that there will be edge cases for both data and performance that LLM developers simply won’t have built into their models. Thus, systems that can provide these models with the tools, feedback, and data that they need to create consistently high quality performance will be enormously valuable.
From that viewpoint, AutoGen is a fun project to watch. It is both immediately usable and open-source, giving a glimpse into how people are thinking about solving some of the technical challenges around agents.
It is an exciting time to be building
[1] Wu, Q., et al. “AutoGen: Enabling Next-Gen LLM Applications via Multi-Agent Conversation” (2023), arXiv
[2] Wang, C., et al. “autogen” (2024), GitHub
[3] Microsoft., et al. “Group Chat with Coder and Visualization Critic” (2024), GitHub
[4] Microsoft., et al. “Task Solving with Code Generation, Execution and Debugging” (2024), GitHub
[5] Microsoft., et al. “Using RetrieveChat for Retrieve Augmented Code Generation and Question Answering” (2024), GitHub
Diving Deep into AutoGen and Agentic Frameworks was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
Originally appeared here:
Diving Deep into AutoGen and Agentic Frameworks
Go Here to Read this Fast! Diving Deep into AutoGen and Agentic Frameworks