A practical assessment of Differential Privacy & Federated Learning in the medical context.

(Bing AI generated image, original, full ownership)
Sensitive data cries out for more protection
The need for data privacy seems to be generally at ease nowadays in the era of large language models trained on everything from the public internet, regardless of actual intellectual property which their respective company leaders openly admit.
But there’s a much more sensitive parallel universe when it comes to patients’ data, our health records, which are undoubtedly much more sensitive and in need of protection.
Also the regulations are getting stronger all over the world, the trend is unanimously towards more stricter data protection regulations, including AI.
There are obvious ethical reasons which we don’t have to explain, but from the enterprise levels regulatory and legal reasons that require pharmaceutical companies, labs and hospitals to use state of the art technologies to protect data privacy of patients.
Federated paradigm is here to help
Federated analytics and learning are great options to be able to analyze data and train models on patients’ data without accessing any raw data.
In case of federated analytics it means, for instance, we can get correlation between blood glucose and patients BMI without accessing any raw data that could lead to patients re-identification.
In the case of machine learning, let’s use the example of diagnostics, where models are trained on patients’ images to detect malignant changes in their tissues and detect early stages of cancer, for instance. This is literally a life saving application of machine learning. Models are trained locally at the hospital level using local images and labels assigned by professional radiologists, then there’s aggregation which combines all those local models into a single more generalized model. The process repeats for tens or hundreds of rounds to improve the performance of the model.
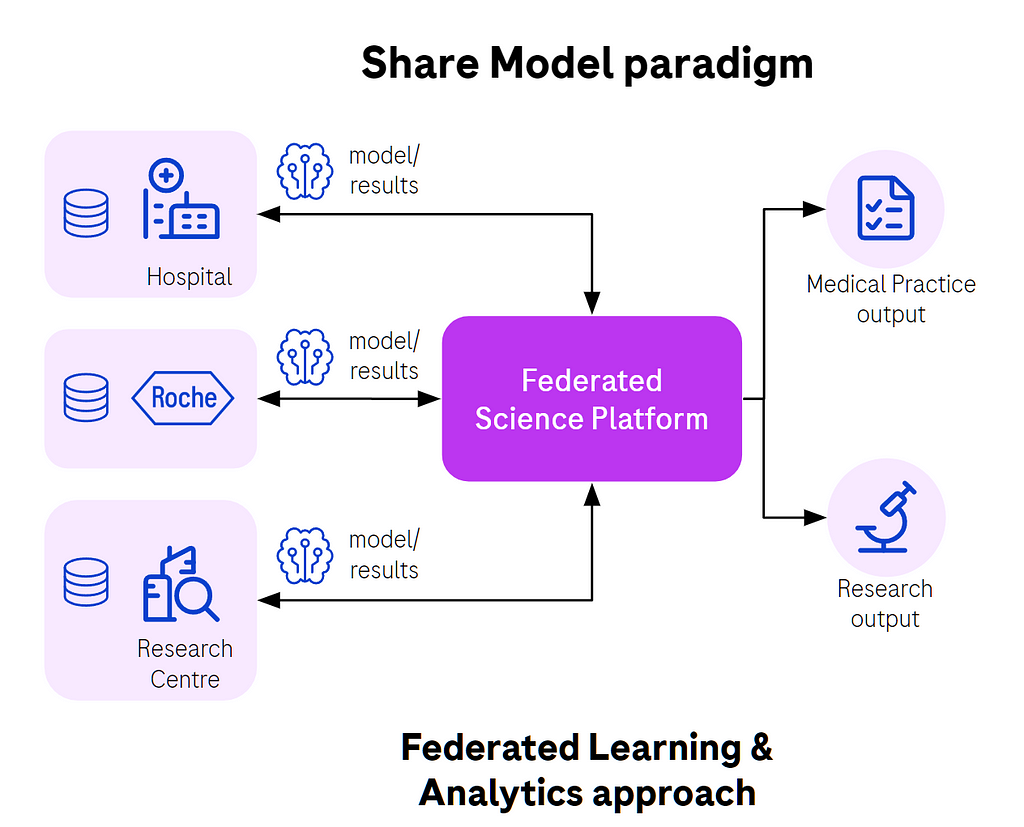
Fig. 1. Federated learning in action, sharing model updates, not data.
The reward for each individual hospital is that they will benefit from a better trained model able to detect disease in future patients with higher probability. It’s a win-win situation for everyone, especially patients.
Of course there’s a variety of federated network topologies and model aggregation strategies, but for the sake of this article we tried to focus on the typical example.
Trust building with the help of technology
It’s believed that vast amounts of clinical data are not being used due to a (justified) reluctance of data owners to share their data with partners.
Federated learning is a key strategy to build that trust backed up by the technology, not only on contracts and faith in ethics of particular employees and partners of the organizations forming consortia.
First of all, the data remains at the source, never leaves the hospital, and is not being centralized in a single, potentially vulnerable location. Federated approach means there aren’t any external copies of the data that may be hard to remove after the research is completed.
The technology blocks access to raw data because of multiple techniques that follow defense in depth principle. Each of them is minimizing the risk of data exposure and patient re-identification by tens or thousands of times. Everything to make it economically unviable to discover nor reconstruct raw level data.
Data is minimized first to expose only the necessary properties to machine learning agents running locally, PII data is stripped, and we also use anonymization techniques.
Then local nodes protect local data against the so-called too curious data scientist threat by allowing only the code and operations accepted by local data owners to run against their data. For instance model training code deployed locally at the hospital as a package is allowed or not by the local data owners. Remote data scientists cannot just send any code to remote nodes as that would allow them for instance to return raw level data. This requires a new, decentralized way of thinking to embrace different mindset and technologies for permission management, an interesting topic for another time.
Are models private enough?
Assuming all those layers of protection are in place there’s still concern related to the safety of model weights themselves.
There’s growing concern in the AI community about machine learning models as the super compression of the data, not as black-boxy as previously considered, and revealing more information about the underlying data than previously thought.
And that means that with enough skills, time, effort and powerful hardware a motivated adversary can try to reconstruct the original data, or at least prove with high probability that a given patient was in the group that was used to train the model (Membership Inference Attack (MIA)) . Other types of attacks possible such as extraction, reconstruction and evasion.
To make things even worse, the progress of generative AI that we all admire and benefit from, delivers new, more effective techniques for image reconstruction (for example, lung scan of the patients). The same ideas that are used by all of us to generate images on demand can be used by adversaries to reconstruct original images from MRI/CT scan machines. Other modalities of data such as tabular data, text, sound and video can now be reconstructed using gen AI.
Differential Privacy to the rescue
Differential privacy (DP) algorithms promise that we exchange some of the model’s accuracy for much improved resilience against inference attacks. This is another privacy-utility trade-off that is worth considering.
Differential privacy means in practice we add a very special type of noise and clipping, that in return will result in a very good ratio of privacy gains versus accuracy loss.
It can be as easy as least effective Gaussian noise but nowadays we embrace the development of much more sophisticated algorithms such as Sparse Vector Technique (SVT), Opacus library as practical implementation of differentially private stochastic gradient descent (DP-SGD), plus venerable Laplacian noise based libraries (i.e. PyDP).

Fig. 2. On device differential privacy that we all use all the time.
And, by the way, we all benefit from this technique without even realizing that it even exists, and it is happening right now. Our telemetry data from mobile devices (Apple iOS, Google Android) and desktop OSes (Microsoft Windows) is using differential privacy and federated learning algorithms to train models without sending raw data from our devices. And it’s been around for years now.
Now, there’s growing adoption for other use cases including our favorite siloed federated learning case, with relatively few participants with large amounts of data in on-purpose established consortia of different organizations and companies.
Differential privacy is not specific to federated learning. However, there are different strategies of applying DP in federated learning scenarios as well as different selection of algorithms. Different algorithms which work better for federated learning setups, different for local data privacy (LDP) and centralized data processing.
In the context of federated learning we anticipate a drop in model accuracy after applying differential privacy, but still (and to some extent hopefully) expect the model to perform better than local models without federated aggregation. So the federated model should still retain its advantage despite added noise and clipping (DP).
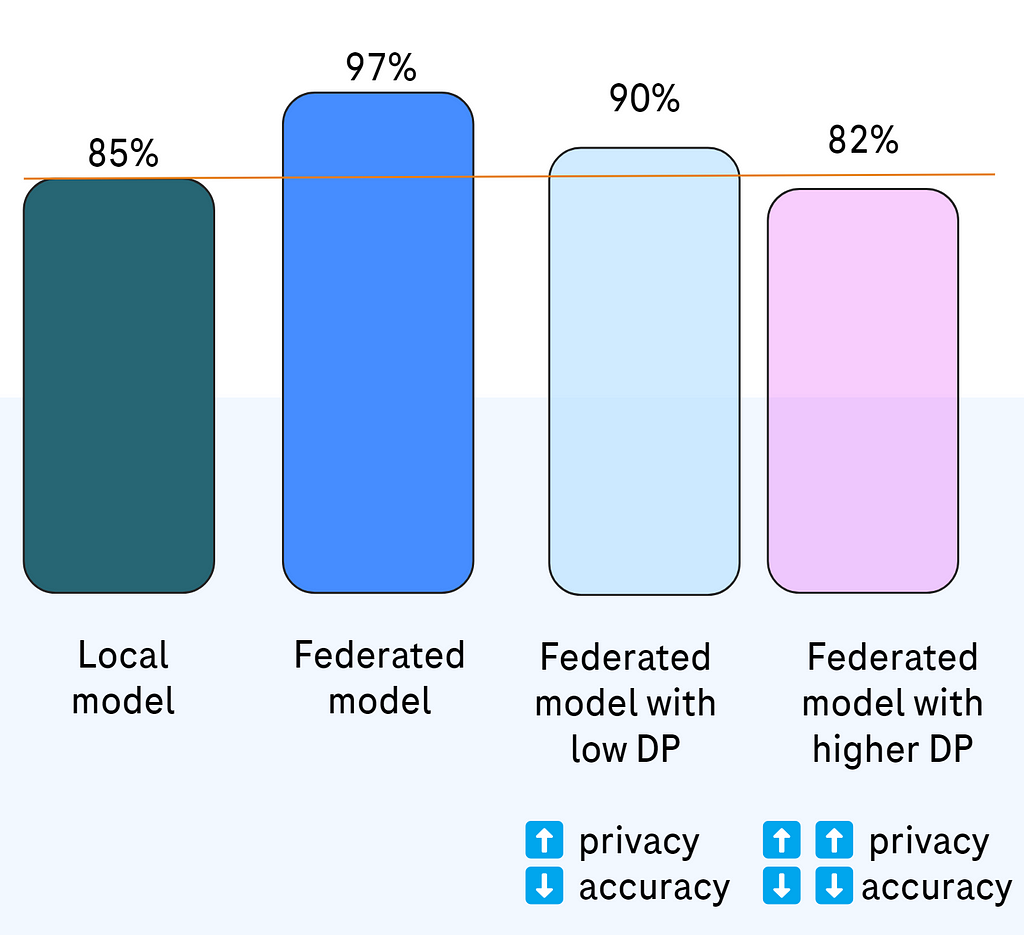
Fig. 3. What we can expect based on known papers and our experiences.
Differential privacy can be applied as early as at the source data (Local Differential Privacy (LDP)).
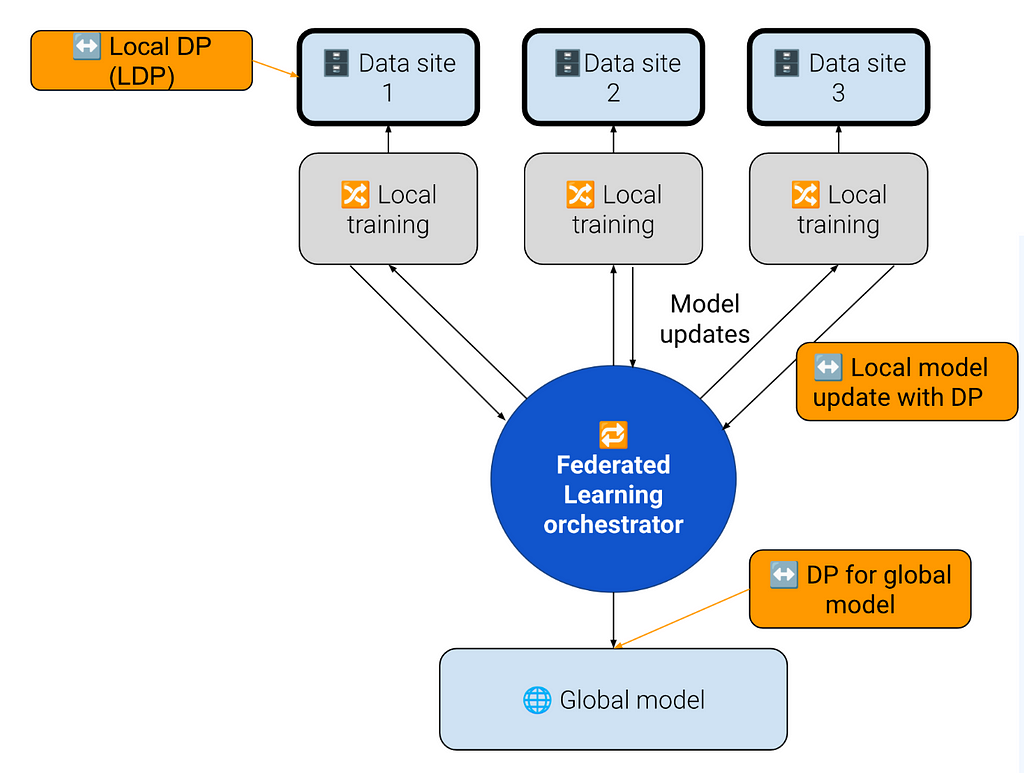
Fig. 4, different places where DP can be applied to improve data protection
There are also cases of federated learning within a network of partners who have all data access rights and are less concerned about data protection levels so there might be no DP at all.
On the other hand when the model is going to be shared with the outside world or sold commercially it might be a good idea to apply DP for the global model as well.
Practical experimentation results
At Roche’s Federated Open Science team, NVIDIA Flare is our tool of choice for federated learning as the most mature open source federated framework on the market. We also collaborate with the NVIDIA team on future development of NVIDIA Flare and are glad to help to improve an already great solution for federated learning.
We tested three different DP algorithms:
We applied differential privacy for the models using different strategies:
- Every federated learning round
- Only the first round (of federated training)
- Each Nth round (of federated training)
for three different cases (datasets and algorithms):
- FLamby Tiny IXI dataset
- Breast density classification
- Higgs classification
So, we tried three dimensions of algorithm, strategy and dataset (case).
The results are conforming with our expectations of model accuracy degradation that was larger with lower privacy budgets (as expected).
FLamby Tiny IXI dataset
(Dataset source: https://owkin.github.io/FLamby/fed_ixi.html)

Fig. 5. Models performance without DP
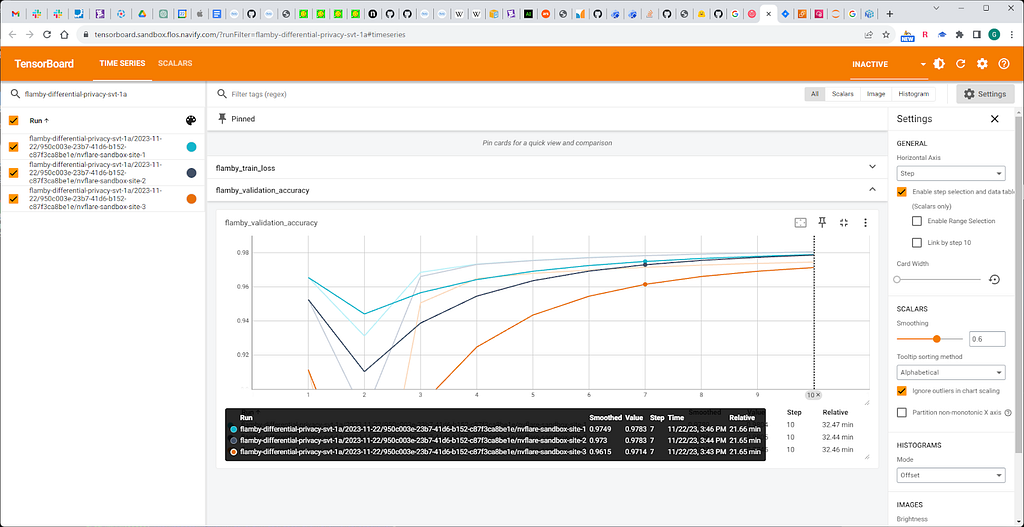
Fig. 6. Models performance with DP on first round
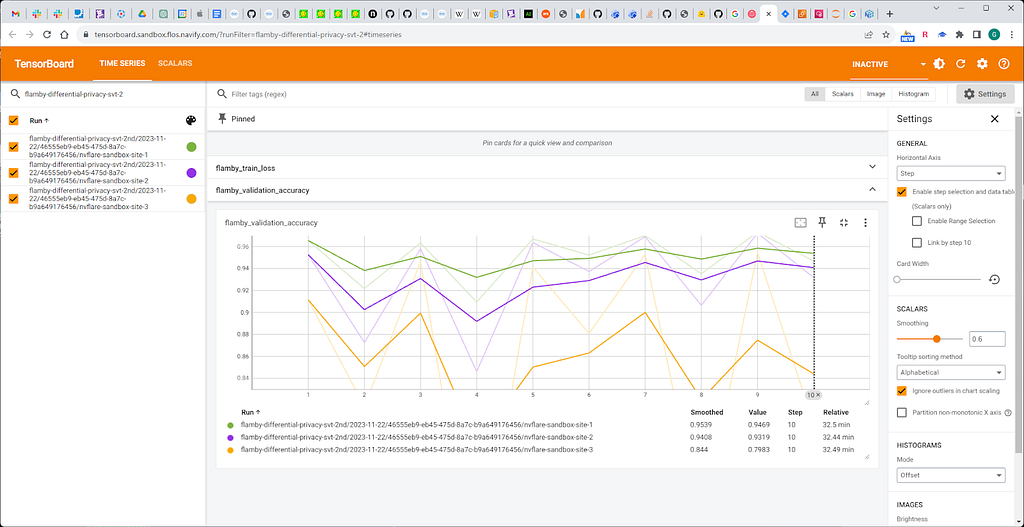
Fig. 7. SVT applied every second round (with decreasing threshold)
We observe significant improvement of accuracy with SVT applied on the first round compared to SVT filter applied to every round.
Breast density case
(Dataset source Breast Density Classification using MONAI | Kaggle)
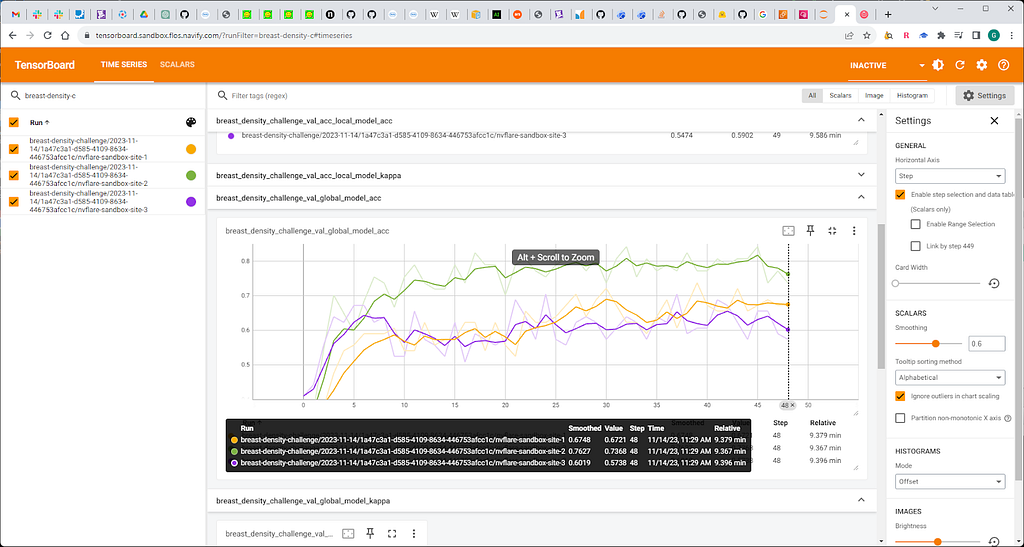
Fig. 8. Models performance without DP
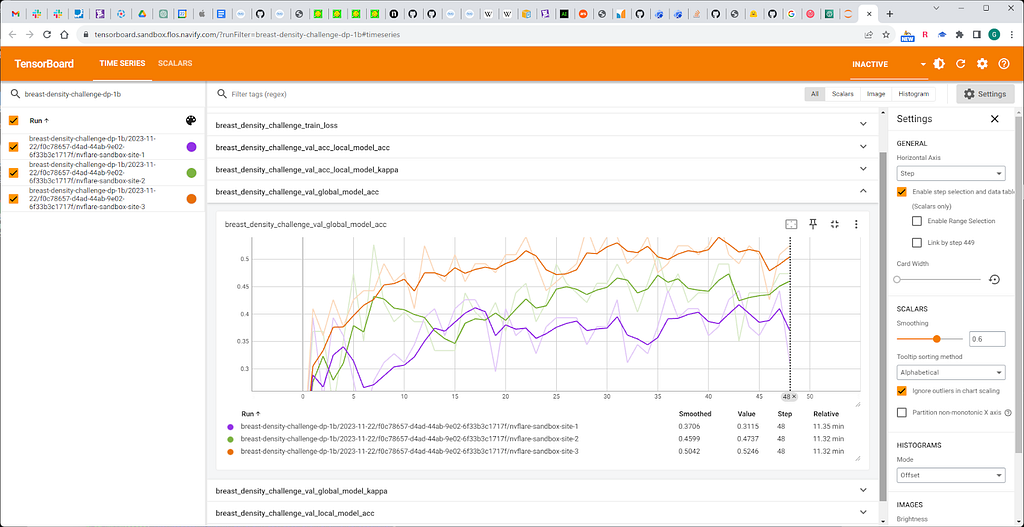
Fig. 9. DP applied to the first round
We observe a mediocre accuracy loss after applying a Gaussian noise filter.
This dataset was the most troublesome and sensitive to DP (major accuracy loss, unpredictability).
Higgs classification
(Dataset source HIGGS — UCI Machine Learning Repository)
Fig. 10. Models performance with percentile value 95.
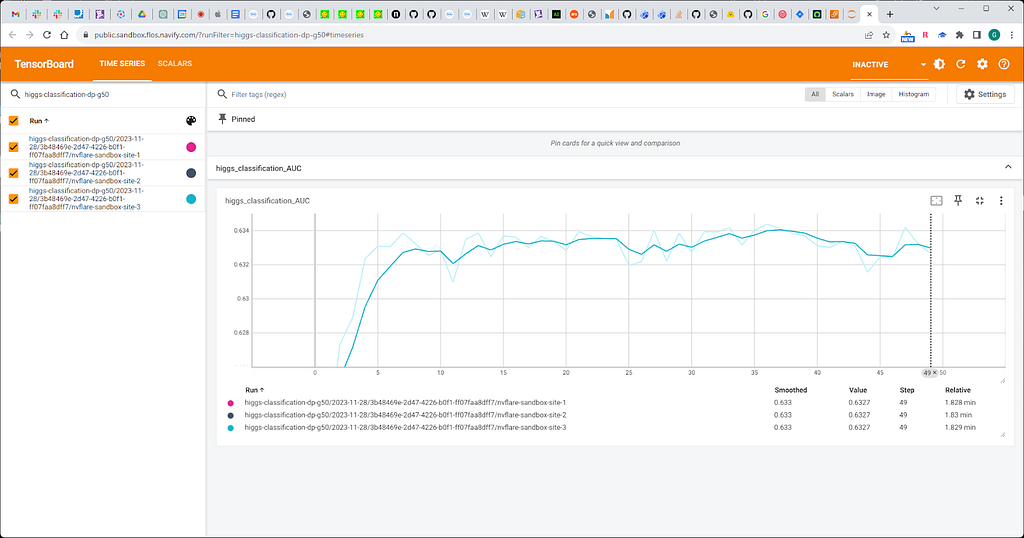
Fig. 11. Percentile value 50.
We observe minor, acceptable accuracy loss related to DP.
Lessons learned
Important lesson learned is that differential privacy outcomes are very sensitive to parameters of a given DP algorithm and it’s hard to tune it to avoid total collapse of model accuracy.
Also, we experienced some kind of anxiety, based on the impression of not really really knowing how much privacy protection we have gained for what price. We only saw the “cost” side (accuracy degradation).
We had to rely to a major extent on known literature, that says and demonstrated, that even small amounts of DP-noise are helping to secure data.
As engineers, we’d like to see some type of automatic measure that would prove how much privacy we gained for how much accuracy lost, and maybe even some kind of AutoDP tuning. Seems to be far, far away from the current state of technology and knowledge.
Then we applied privacy meters to see if there’s a visible difference between models without DP versus models with DP and we observed changes in the curve, but it’s really hard to quantify how much we gained.
Some algorithms didn’t work at all, some required many attempts to tune them properly to deliver viable results. There was no clear guidance on how to tune different parameters for particular dataset and ML models.
So our current opinion is that DP for FL is hard, but totally feasible. It requires a lot of iterations, and trial and error loops to achieve acceptable results while believing in privacy improvements of orders of magnitude based on the trust in algorithms.
The future
Federated learning is a great option to improve patients’ outcomes and treatment efficacy because of the improved ML models while preserving patients’ data.
But data protection never comes without any price and differential privacy for federated learning is a perfect example of that trade-off.
It’s great to see improvements in algorithms of differential privacy for federated learning scenarios to minimize the impact on accuracy while maximizing resilience of models against inference attacks.
As with all trade-offs the decisions have to be made balancing usefulness of models for practical applications against the risks of data leakage and reconstruction.
And that’s where our expectation for privacy meters are growing to know more precisely what we are selling and we are “buying”, what the exchange ratio is.
The landscape is dynamic, with better tools available for both those who want to better protect their data and those who are motivated to violate those rules and expose sensitive data.
We also invite other federated minds to build upon and contribute to the collective effort of advancing patient data privacy for Federated Learning.
The author would like to thank Jacek Chmiel for significant impact on the blog post itself, as well as the people who helped develop these ideas and bring them to practice: Jacek Chmiel, Lukasz Antczak and Grzegory Gajda.
All images in this article were created by the authors.
Differential Privacy and Federated Learning for Medical Data was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
Originally appeared here:
Differential Privacy and Federated Learning for Medical Data
Go Here to Read this Fast! Differential Privacy and Federated Learning for Medical Data