MLOps
When should I retrain my model?
Have you heard of lifelong learning? You might be familiar with the story: with today’s rapid technology advancements, what we learned at school will not set us up for professional success for our whole career. To stay useful in the job market, one needs to learn how to learn continuously. In this aspect of life, AI is not so different from us humans. Machine learning models’ knowledge becomes obsolete, too, and they need to relearn stuff just like we do. But when does a model become obsolete?

What is concept shift, and can we detect it?
The phenomenon responsible for ML models’ knowledge going stale is known as concept shift. However, before we dive into the details, let’s take a quick high-level overview of the broader problem: data shifts.
Data shifts primer
The world changes. Consumer behaviors and tastes evolve over time; your users might change their preferences as they grow older; data-collecting devices tend to break or malfunction in unexpected ways. Whatever industry you are working in, and whatever problem you’re solving with machine learning, you can be sure that at some point, the data your production model receives will be different from the data it has seen during training. As a consequence of this, machine learning models tend to deteriorate over time after being deployed to production.
Types of data shift
The changes in the world can translate to the changes in your data in different ways. To better understand this, it’s useful to introduce a bit of notation.
Machine learning models, in general, operate on two kinds of input data: features, X, and targets, y. The data shift in its most generic form is described as a change in the joint distribution of features and targets, P(X, Y). There are four potential causes for P(X, Y) to change.
To list all four, we need to use the so-called product rule, a mathematical formula stating that P(X, Y) = P(Y, X) = P(X|Y)P(Y) = P(Y|X)P(X).
From there, it follows that the joint distribution of features and targets (which can be equivalently written as P(X, Y) or P(Y, X) can be decomposed in two alternative and equivalent ways:
- P(X|Y) * P(Y)
- P(Y|X) * P(X)
This means that if any of the four elements above changes, P(X, Y) will also change, resulting in a data shift. The change of each of the four elements has its own name, its own causes, and its own solutions. Let’s take a look at them briefly.
Side note: I said that each of the four elements can change, leading to a data shift. But of course, there is no rule forbidding multiple of the four elements to change at the same time. In fact, they often do, causing the resulting data shift to be a multifaceted and complex phenomenon. In this article, however, let’s assume only one of the four changes at any given time.
So, back to the four types of data shift.
- If P(X) changes (and P(Y|X) remains unchanged), we are talking about covariate shift. The name makes a lot of sense once we realize that covariate is just another term for the feature or the independent variable in a model. Covariate shift is when the distribution of the model inputs changes.
- If P(Y) changes (but P(X|Y) remains unchanged), we are talking about a label shift. It means the output distribution changed, but for any given output, the input distribution stays the same.
- If P(Y|X) changes (but P(X) remains unchanged), that’s the concept shift, the topic of this article. We will explore it in detail soon.
- Finally, the situation in which P(X|Y) changes while P(Y) remains the same is known as manifestation shift. It means that the same target values manifest themselves differently in the input distribution. We won’t cover manifestation shifts here, leaving it for a separate article.
Out of the four types of data shift, covariate shift and concept shift are the most widely discussed and are arguably the major concerns for most companies having ML models serving predictions in production. Let’s discuss detecting the two to see how concept shift detection introduces new challenges compared to covariate shift detection.
Detecting data shifts
Covariate shift is arguably easier to both understand and detect. Let’s revisit: it’s a situation in which P(X) changes. In other words, the distribution of the model’s input features at serving time is different from the one it has seen in training.
In the vast majority of cases, one has access to both training features and serving features. It’s enough to compare their distributions: if they differ, a covariate shift has happened.
Alright, that’s an oversimplification. In reality, there are two approaches to measuring covariate shift. We can look at it in a univariate way by checking if the distribution of one or more of the features has changed, or in a multivariate way where we focus on the joint distribution of all features.
In the univariate approach, one can compare training and serving distributions using statistical tests and distance measures, feature by feature. In the multivariate approach, a more nuanced approach based on PCA is a good way to go. But in either case, the task is to compare two observed quantities and decide whether they are truly different or not.
In the case of concept shift, the challenge of shift detection is more involved. Let’s revisit: concept shift is when P(Y|X) changes, that is, for given feature values, the target distribution changes.
The tricky part is in measuring and comparing P(Y|X), often referred to as the concept. It’s not a single quantity that can be easily calculated. It’s the true mapping, or relation, between inputs and outputs. We know it for the training data (to the best of our model’s ability), but how can we know when it changes in the real world? Let’s see!
Concept shift detection in the wild
Thanks for bearing with me through this rather lengthy introduction! Now that we know what concept shift is and why it’s challenging to detect, let’s discuss it in greater detail, following a practical example.
Concept shift in time & space
Concept shift means that for specific inputs, the distribution of the output has changed (P(Y|X) has changed, remember?). This change can occur in either of the two dimensions: in time or space.
Concept shift in time means that the concept the model has learned during training has since then changed in the real world. In other words, the model’s knowledge is not up-to-date anymore.
Let me borrow an example from Chip Huyen’s fantastic book “Designing Machine Learning Systems”: imagine you’re building a model to predict housing prices in San Francisco. Before the coronavirus pandemic, a three-bedroom apartment might have cost $2m, but because of the virus, many people have left the city, and as a result of declining demand, the same apartment could now cost $1.5m. The feature distributions P(X) have not changed: the houses still have the same number of bedrooms, square footage, etc. It’s just that the same set of inputs now maps to a different output.
Concept shift in space when a concept learned from data from a particular geography or a particular set of users is not relevant for different regions or user bases. For example, adding 50 square feet to a San Francisco apartment can result in a significant price increase. However, the same addition to a house in rural Wyoming, where the housing market is much less competitive, might not translate to an equally large price increase.
Alright, so what we know so far is that concept shift might be a problem when either some time has passed since model deployment, or when the model starts serving different users or geographies. But how do we go about detecting it?
Detecting concept shift
Imagine this: you train your San Francisco house pricing model on all available data and deploy it to production. Afterward, you collect the features that the model receives for inference and store them in daily batches.
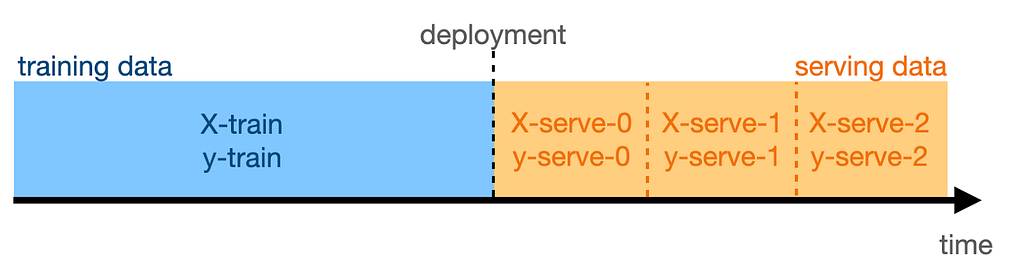
Here, X-serve-0 are the features from the day of deployment, X-serve-1 are the features from the following day, and so on, while y-serve-* denotes the corresponding targets.
It’s day 0 today: the model trained on data up until yesterday is now in production. Are today’s data (X-serve-0 and y-serve-0) subject to concept shift?
Let’s assume for a moment that this is a binary question. In practice, of course, concept shift can be large or small and impact model performance heavily or not very much. But for now, let’s say that concept shift has either happened on day 0 or not.
Here’s an idea: let’s train a model on day 0 data. If there was no concept shift, it should learn the same features-to-target mapping that our production model has learned. If concept shift occurred, the learned mapping will be different.
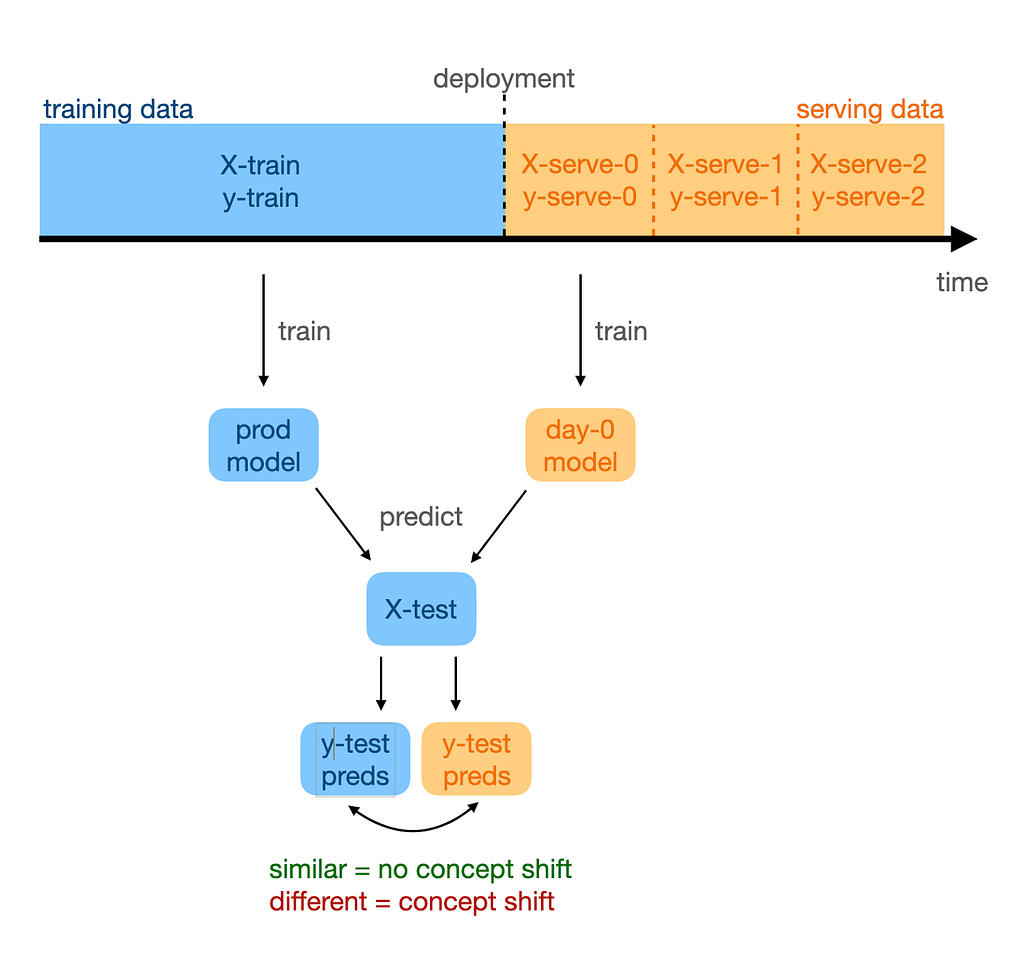
Next, let’s use this day-0 model to make predictions for test data: we just feed it X-test. If the outputs are close to the test-set predictions from the production model, it means that our day-0 model has learned the same P(Y|X), or the same concept, as our production model. Therefore, we proclaim no concept shift. If the outputs are different, however, then concept shift must have happened.
We can detect concept shift by training a model on serving data and comparing it to the production model.
We can repeat this process daily with every new batch of data we receive in serving to keep refreshing our knowledge of whether a concept shift has happened or not.
Concept shift: detection vs. impact on performance
This is all nice, but there is one caveat to it, which a watchful reader might have spotted already. The outputs from the day-* models will never be exactly the same as the ones from the production model: even in the absence of any shift, the sampling error (different sample of training data) will lead to slightly different results. How large differences do actually signal concept shift? Or, to rephrase this question more practically: when do we need to retrain the model?
Indeed, not every difference should call for retraining, which could be a costly or complex procedure. As mentioned above, the difference might sometimes be the result of random sampling, in which case no retraining is necessary. On other occasions, the difference might actually be caused by the concept shift, but one that’s not impacting the model in a meaningful way. In this case, retraining is not needed either.
The key observation to take away here is that one should only retrain the model when the concept shift is meaningfully impacting the model’s performance.
One should only retrain the model when the concept shift is meaningfully impacting the model’s performance.
So how do we tell how much is the performance impacted by concept shift? Let’s flip this question: are there situations where concept shift occurs but does not hurt the model’s performance?
Harmless concept shift
Imagine that your San Francisco house pricing model is now a classification model in which you are predicting whether a house costs more or less than $1m given its features. You have followed the steps described above to find large differences between the outputs of the production model and the current-day model.
Unchanged predicted labels
Here is the plot showing the differences in the probability of the house costing more than $1m from the two models for a subset of 10 data points.
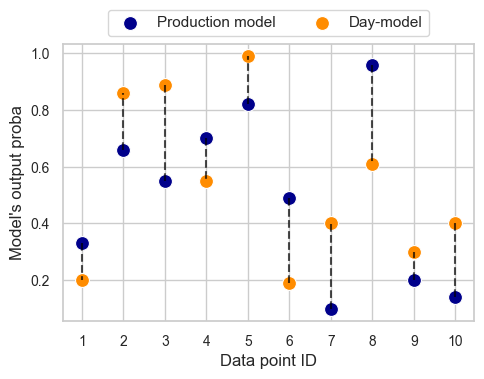
There are three important observations to be made here. First, the two models predict completely different probabilities. The difference is large for each data point and can be as significant as close to 50 percentage points. We can be almost certain that a significant concept shift has occurred.
Second, there is no consistency in the two models’ relative outputs. Sometimes one produces a much higher probability than the other, sometimes the other way round.
Third, the concept shift we are experiencing is completely harmless for the model. Wait, what? That’s right! Although significant, the concept shift we’re dealing with will not impact the model performance at all!
Concept shift does not always impact model performance.
Recall we’re looking at a binary classification task. Given a customary decision threshold at 50%, for each data point, both models will yield the same prediction: data points 2, 3, 4, 5, and 8 correspond to positive predictions (price above $1m), and the remaining ones — to negative predictions. Performance metrics such as accuracy, precision, recall, or f1-score will be the same for both models (ROC AUC will be impacted, though, since it uses the model scores rather than just class assignments).
I admit that this example is artificial and has been deliberately drafted to show what I’m trying to convey: that concept shift need not impact performance. But fair enough — in reality, one would rarely ever just use the predicted labels while disregarding certainty scores. Let’s look at another, arguably more realistic scenario in which concept shift will not hurt you.
Shift in sparse regions
Model features constitute a multidimensional space, and each training example is a point in this space. If you only had two features, x1 and x2, you could plot each example as a point on a two-dimensional plane — the feature space. With three features, each example will be a point inside a cube. In the more common situations of using four features or more, our brains fail to imagine the scene, but still, each example is a point in the feature space.
The training examples are not uniformly distributed across the feature space. Some areas within the feature space will be densely packed by data points, while elsewhere they will be quite sparse. Another way to think about it is that in your data, some combinations of feature values are frequent and others very rare.
Now, here’s the thing: concept shift might occur in any region within the feature space. If it happens to be in a sparse region, its impact on the model’s performance will be minor. This is because there is not much training nor serving data in this region. Thus, the model will hardly ever get to predict in this region. Any misclassifications caused by the concept shift in a sparse region will be rare events, not contributing much to the model’s overall performance.
Misclassifications caused by the concept shift in a sparse region will be rare events, not contributing much to the model’s overall performance.
The takeaway from the two stories above is that some concept shifts are harmless, and only a meaningfully negative impact on performance calls for model retraining. Once you have detected a concept shift, estimate its impact on your model first before taking unnecessary action!
Tools for concept shift detection
We could summarize our whole discussion up to this point as: don’t focus on the shift’s presence. Detect its impact on performance instead.
However, this is not how people typically do it. A quick web search reveals that most approaches to concept shift detection (such as this one from DeepChecks blog or this one from Evidently AI) work indirectly: they are typically based on detecting the prediction drift, label drift, or data drift.
The only tool I found that claims to be able to directly detect the magnitude of concept shift, and more importantly to quantify its impact on model performance as we have just discussed, is NannyML. I contacted the team and was told that besides being available as a standalone algorithm on AWS (which had appeared in my search), it is also available as an Azure managed app.
This approach follows the previously discussed workflow. Every day after deployment, a day-model is trained on serving data collected on this particular day. Next, we look at the predicted probabilities that our day-model produced for the training data and compare them with the ones from the production model. These differences let us estimate the shift’s impact on performance metrics such as ROC AUC, accuracy, and others.
I used the free trial to see how to estimate the performance implications of a concept shift in practice for a classification task. And no, it won’t be about San Francisco housing again.
Consider flight cancellations. They are primarily driven by operational factors like weather conditions or airline-specific problems. We can use these features to quite reliably predict whether a given flight will be canceled or not.
Or at least that was the case until the end of the year 2019. With the onset of the COVID-19 pandemic, travel restrictions, lockdowns, and a sharp decrease in travel demand led to a significant increase in flight cancellations, fundamentally changing the relationship between factors such as weather and cancellations. For example, good weather did not guarantee fewer cancellations anymore.
Let’s train a model to predict cancellations on data up to the year 2018, and treat years 2019 through 2023 as our serving data based on the data from the Bureau of Transportation Statistics. Here’s what NannyML’s concept shift detection algorithm outputs.
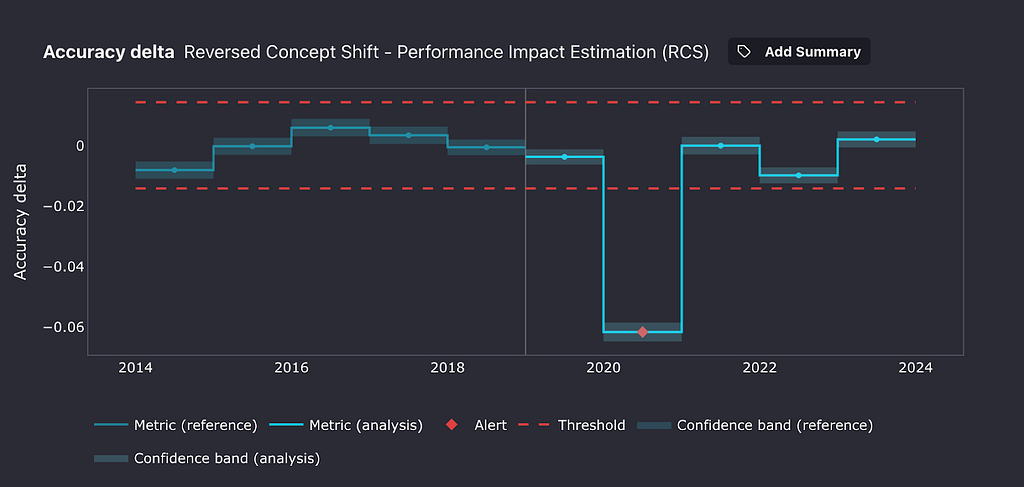
During the first year after deployment, 2019, no significant concept shift seems to have happened. Our thresholds for meaningful performance change were not crossed. The following year, however, as the pandemic broke out, our cancellation classifier lost 6 accuracy percentage points! Interestingly, the following year, things roughly got back to their pre-pandemic state.
Considerations & Conclusion
A Concept shift is a change in the mapping between features and targets, while the features themselves remain unchanged. Think of it as: the same inputs, different outputs. It’s arguably harder to detect than its evil twin, covariate shift, in which the features’ distributions change.
A clever way of detecting concept shift is to regularly train models on incoming serving data and compare the concept they learn to the concept learned by the production model. If they are different, concept shift must have happened. This approach has some limitations, though. It assumes that the targets for the serving data are available, which is not the case in many applications.
Finally, not all concept shift is bad. In some situations, however, it can negatively impact the performance of your models in production, and by extension, the business value delivered by these models. By following the approach outlined above, you can quantify your concept shift’s impact and ensure your ML models continue to provide value.
Thanks for reading!
If you liked this post, why don’t you subscribe for email updates on my new articles? By becoming a Medium member, you can support my writing and get unlimited access to all stories by other authors and yours truly. Need consulting? You can ask me anything or book me for a 1:1 here.
You can also try one of my other articles. Can’t choose? Pick one of these:
- How to Detect Data Drift with Hypothesis Testing
- Organizing a Machine Learning Monorepo with Pants
- Self-Supervised Learning in Computer Vision
Detecting Concept Shift: Impact on Machine Learning Performance was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
Originally appeared here:
Detecting Concept Shift: Impact on Machine Learning Performance
Go Here to Read this Fast! Detecting Concept Shift: Impact on Machine Learning Performance